 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Agentic Reasoning for Designing Biologics Targeting Intrinsically Disordered Proteins
Dec 17, 2025Intrinsically disordered proteins (IDPs) represent crucial therapeutic targets due to their significant role in disease -- approximately 80\% of cancer-related proteins contain long disordered regions -- but their lack of stable secondary/tertiary structures makes them "undruggable". While recent computational advances, such as diffusion models, can design high-affinity IDP binders, translating these to practical drug discovery requires autonomous systems capable of reasoning across complex conformational ensembles and orchestrating diverse computational tools at scale.To address this challenge, we designed and implemented StructBioReasoner, a scalable multi-agent system for designing biologics that can be used to target IDPs. StructBioReasoner employs a novel tournament-based reasoning framework where specialized agents compete to generate and refine therapeutic hypotheses, naturally distributing computational load for efficient exploration of the vast design space. Agents integrate domain knowledge with access to literature synthesis, AI-structure prediction, molecular simulations, and stability analysis, coordinating their execution on HPC infrastructure via an extensible federated agentic middleware, Academy. We benchmark StructBioReasoner across Der f 21 and NMNAT-2 and demonstrate that over 50\% of 787 designed and validated candidates for Der f 21 outperformed the human-designed reference binders from literature, in terms of improved binding free energy. For the more challenging NMNAT-2 protein, we identified three binding modes from 97,066 binders, including the well-studied NMNAT2:p53 interface. Thus, StructBioReasoner lays the groundwork for agentic reasoning systems for IDP therapeutic discovery on Exascale platforms.
HiPerRAG: High-Performance Retrieval Augmented Generation for Scientific Insights
May 07, 2025The volume of scientific literature is growing exponentially, leading to underutilized discoveries, duplicated efforts, and limited cross-disciplinary collaboration. Retrieval Augmented Generation (RAG) offers a way to assist scientists by improving the factuality of Large Language Models (LLMs) in processing this influx of information. However, scaling RAG to handle millions of articles introduces significant challenges, including the high computational costs associated with parsing documents and embedding scientific knowledge, as well as the algorithmic complexity of aligning these representations with the nuanced semantics of scientific content. To address these issues, we introduce HiPerRAG, a RAG workflow powered by high performance computing (HPC) to index and retrieve knowledge from more than 3.6 million scientific articles. At its core are Oreo, a high-throughput model for multimodal document parsing, and ColTrast, a query-aware encoder fine-tuning algorithm that enhances retrieval accuracy by using contrastive learning and late-interaction techniques. HiPerRAG delivers robust performance on existing scientific question answering benchmarks and two new benchmarks introduced in this work, achieving 90% accuracy on SciQ and 76% on PubMedQA-outperforming both domain-specific models like PubMedGPT and commercial LLMs such as GPT-4. Scaling to thousands of GPUs on the Polaris, Sunspot, and Frontier supercomputers, HiPerRAG delivers million document-scale RAG workflows for unifying scientific knowledge and fostering interdisciplinary innovation.
AdaParse: An Adaptive Parallel PDF Parsing and Resource Scaling Engine
Apr 23, 2025Language models for scientific tasks are trained on text from scientific publications, most distributed as PDFs that require parsing. PDF parsing approaches range from inexpensive heuristics (for simple documents) to computationally intensive ML-driven systems (for complex or degraded ones). The choice of the "best" parser for a particular document depends on its computational cost and the accuracy of its output. To address these issues, we introduce an Adaptive Parallel PDF Parsing and Resource Scaling Engine (AdaParse), a data-driven strategy for assigning an appropriate parser to each document. We enlist scientists to select preferred parser outputs and incorporate this information through direct preference optimization (DPO) into AdaParse, thereby aligning its selection process with human judgment. AdaParse then incorporates hardware requirements and predicted accuracy of each parser to orchestrate computational resources efficiently for large-scale parsing campaigns. We demonstrate that AdaParse, when compared to state-of-the-art parsers, improves throughput by $17\times$ while still achieving comparable accuracy (0.2 percent better) on a benchmark set of 1000 scientific documents. AdaParse's combination of high accuracy and parallel scalability makes it feasible to parse large-scale scientific document corpora to support the development of high-quality, trillion-token-scale text datasets. The implementation is available at https://github.com/7shoe/AdaParse/
Connecting Large Language Model Agent to High Performance Computing Resource
Feb 17, 2025The Large Language Model agent workflow enables the LLM to invoke tool functions to increase the performance on specific scientific domain questions. To tackle large scale of scientific research, it requires access to computing resource and parallel computing setup. In this work, we implemented Parsl to the LangChain/LangGraph tool call setup, to bridge the gap between the LLM agent to the computing resource. Two tool call implementations were set up and tested on both local workstation and HPC environment on Polaris/ALCF. The first implementation with Parsl-enabled LangChain tool node queues the tool functions concurrently to the Parsl workers for parallel execution. The second configuration is implemented by converting the tool functions into Parsl ensemble functions, and is more suitable for large task on super computer environment. The LLM agent workflow was prompted to run molecular dynamics simulations, with different protein structure and simulation conditions. These results showed the LLM agent tools were managed and executed concurrently by Parsl on the available computing resource.
LSHBloom: Memory-efficient, Extreme-scale Document Deduplication
Nov 06, 2024Deduplication is a major focus for assembling and curating training datasets for large language models (LLM) -- detecting and eliminating additional instances of the same content -- in large collections of technical documents. Unrestrained, duplicates in the training dataset increase training costs and lead to undesirable properties such as memorization in trained models or cheating on evaluation. Contemporary approaches to document-level deduplication are often extremely expensive in both runtime and memory. We propose LSHBloom, an extension to MinhashLSH, which replaces the expensive LSHIndex with lightweight Bloom filters. LSHBloom demonstrates the same deduplication performance as MinhashLSH with only a marginal increase in false positives (as low as 1e-5 in our experiments); demonstrates competitive runtime (270\% faster than MinhashLSH on peS2o); and, crucially, uses just 0.6\% of the disk space required by MinhashLSH to deduplicate peS2o. We demonstrate that this space advantage scales with increased dataset size -- at the extreme scale of several billion documents, LSHBloom promises a 250\% speedup and a 54$\times$ space advantage over traditional MinHashLSH scaling deduplication of text datasets to many billions of documents.
WordScape: a Pipeline to extract multilingual, visually rich Documents with Layout Annotations from Web Crawl Data
Dec 15, 2023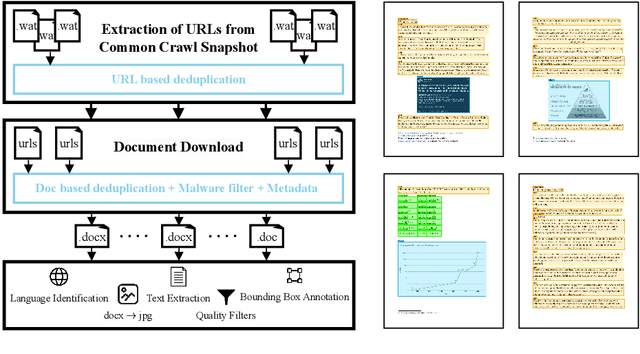

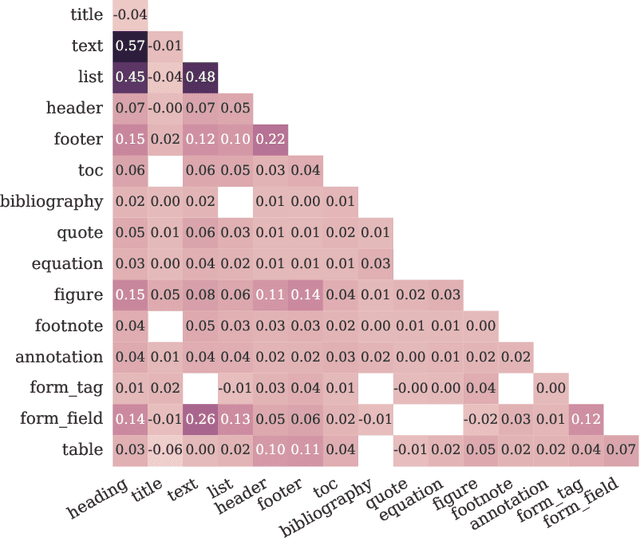
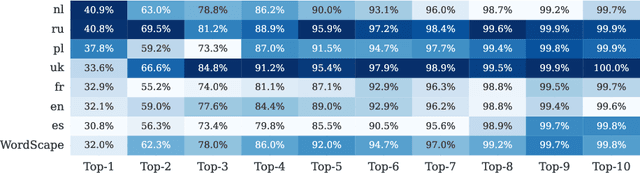
We introduce WordScape, a novel pipeline for the creation of cross-disciplinary, multilingual corpora comprising millions of pages with annotations for document layout detection. Relating visual and textual items on document pages has gained further significance with the advent of multimodal models. Various approaches proved effective for visual question answering or layout segmentation. However, the interplay of text, tables, and visuals remains challenging for a variety of document understanding tasks. In particular, many models fail to generalize well to diverse domains and new languages due to insufficient availability of training data. WordScape addresses these limitations. Our automatic annotation pipeline parses the Open XML structure of Word documents obtained from the web, jointly providing layout-annotated document images and their textual representations. In turn, WordScape offers unique properties as it (1) leverages the ubiquity of the Word file format on the internet, (2) is readily accessible through the Common Crawl web corpus, (3) is adaptive to domain-specific documents, and (4) offers culturally and linguistically diverse document pages with natural semantic structure and high-quality text. Together with the pipeline, we will additionally release 9.5M urls to word documents which can be processed using WordScape to create a dataset of over 40M pages. Finally, we investigate the quality of text and layout annotations extracted by WordScape, assess the impact on document understanding benchmarks, and demonstrate that manual labeling costs can be substantially reduced.