 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Instruction-Tuned LLMs to Million-Token Contexts via Hierarchical Synthetic Data Generation
Apr 17, 2025



Large Language Models (LLMs) struggle with long-context reasoning, not only due to the quadratic scaling of computational complexity with sequence length but also because of the scarcity and expense of annotating long-context data. There has been barely any open-source work that systematically ablates long-context data, nor is there any openly available instruction tuning dataset with contexts surpassing 100K tokens. To bridge this gap, we introduce a novel post-training synthetic data generation strategy designed to efficiently extend the context window of LLMs while preserving their general task performance. Our approach scalably extends to arbitrarily long context lengths, unconstrained by the length of available real-world data, which effectively addresses the scarcity of raw long-context data. Through a step-by-step rotary position embedding (RoPE) scaling training strategy, we demonstrate that our model, with a context length of up to 1M tokens, performs well on the RULER benchmark and InfiniteBench and maintains robust performance on general language tasks.
Multilingual Language Model Pretraining using Machine-translated Data
Feb 18, 2025High-resource languages such as English, enables the pretraining of high-quality large language models (LLMs). The same can not be said for most other languages as LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated texts from a single high-quality source language can contribute significantly to the pretraining quality of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into nine languages, resulting in a 1.7-trillion-token dataset, which we call TransWebEdu and pretrain a 1.3B-parameter model, TransWebLLM, from scratch on this dataset. Across nine non-English reasoning tasks, we show that TransWebLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2, Qwen2.5, and Gemma, despite using an order of magnitude less data. We demonstrate that adding less than 5% of TransWebEdu as domain-specific pretraining data sets a new state-of-the-art in Arabic, Italian, Indonesian, Swahili, and Welsh understanding and commonsense reasoning tasks. To promote reproducibility, we release our corpus, models, and training pipeline under Open Source Initiative-approved licenses.
Towards Best Practices for Open Datasets for LLM Training
Jan 14, 2025Many AI companies are training their large language models (LLMs) on data without the permission of the copyright owners. The permissibility of doing so varies by jurisdiction: in countries like the EU and Japan, this is allowed under certain restrictions, while in the United States, the legal landscape is more ambiguous. Regardless of the legal status, concerns from creative producers have led to several high-profile copyright lawsuits, and the threat of litigation is commonly cited as a reason for the recent trend towards minimizing the information shared about training datasets by both corporate and public interest actors. This trend in limiting data information causes harm by hindering transparency, accountability, and innovation in the broader ecosystem by denying researchers, auditors, and impacted individuals access to the information needed to understand AI models. While this could be mitigated by training language models on open access and public domain data, at the time of writing, there are no such models (trained at a meaningful scale) due to the substantial technical and sociological challenges in assembling the necessary corpus. These challenges include incomplete and unreliable metadata, the cost and complexity of digitizing physical records, and the diverse set of legal and technical skills required to ensure relevance and responsibility in a quickly changing landscape. Building towards a future where AI systems can be trained on openly licensed data that is responsibly curated and governed requires collaboration across legal, technical, and policy domains, along with investments in metadata standards, digitization, and fostering a culture of openness.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Multilingual Pretraining Using a Large Corpus Machine-Translated from a Single Source Language
Oct 31, 2024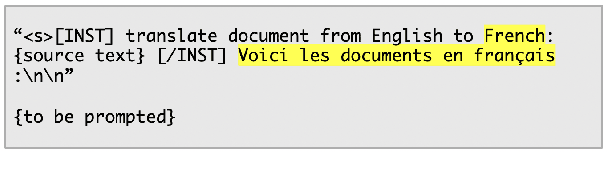
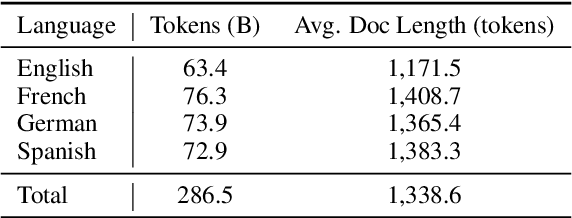
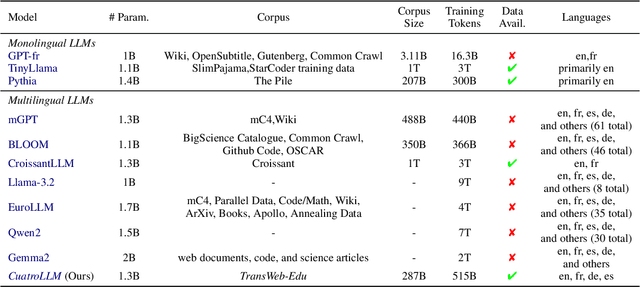
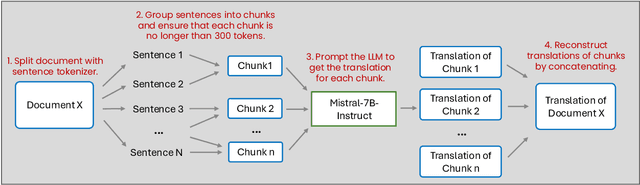
English, as a very high-resource language, enables the pretraining of high-quality large language models (LLMs). The same cannot be said for most other languages, as leading LLMs still underperform for non-English languages, likely due to a gap in the quality and diversity of the available multilingual pretraining corpora. In this work, we find that machine-translated text from a single high-quality source language can contribute significantly to the pretraining of multilingual LLMs. We translate FineWeb-Edu, a high-quality English web dataset, into French, German, and Spanish, resulting in a final 300B-token dataset, which we call TransWeb-Edu, and pretrain a 1.3B-parameter model, CuatroLLM, from scratch on this dataset. Across five non-English reasoning tasks, we show that CuatroLLM matches or outperforms state-of-the-art multilingual models trained using closed data, such as Llama3.2 and Gemma2, despite using an order of magnitude less data, such as about 6% of the tokens used for Llama3.2's training. We further demonstrate that with additional domain-specific pretraining, amounting to less than 1% of TransWeb-Edu, CuatroLLM surpasses the state of the art in multilingual reasoning. To promote reproducibility, we release our corpus, models, and training pipeline under open licenses at hf.co/britllm/CuatroLLM.
WordScape: a Pipeline to extract multilingual, visually rich Documents with Layout Annotations from Web Crawl Data
Dec 15, 2023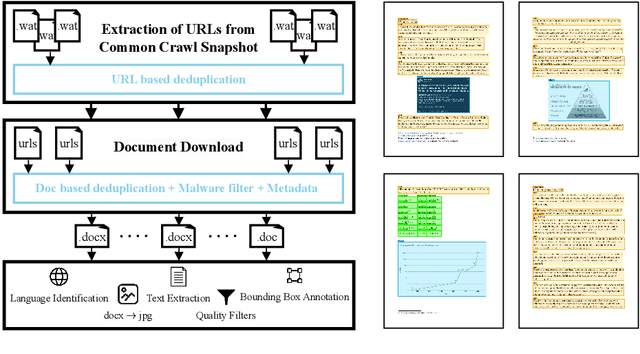

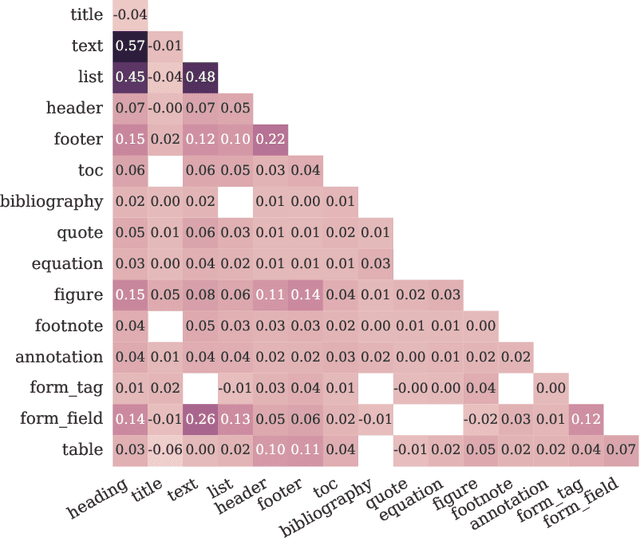
We introduce WordScape, a novel pipeline for the creation of cross-disciplinary, multilingual corpora comprising millions of pages with annotations for document layout detection. Relating visual and textual items on document pages has gained further significance with the advent of multimodal models. Various approaches proved effective for visual question answering or layout segmentation. However, the interplay of text, tables, and visuals remains challenging for a variety of document understanding tasks. In particular, many models fail to generalize well to diverse domains and new languages due to insufficient availability of training data. WordScape addresses these limitations. Our automatic annotation pipeline parses the Open XML structure of Word documents obtained from the web, jointly providing layout-annotated document images and their textual representations. In turn, WordScape offers unique properties as it (1) leverages the ubiquity of the Word file format on the internet, (2) is readily accessible through the Common Crawl web corpus, (3) is adaptive to domain-specific documents, and (4) offers culturally and linguistically diverse document pages with natural semantic structure and high-quality text. Together with the pipeline, we will additionally release 9.5M urls to word documents which can be processed using WordScape to create a dataset of over 40M pages. Finally, we investigate the quality of text and layout annotations extracted by WordScape, assess the impact on document understanding benchmarks, and demonstrate that manual labeling costs can be substantially reduced.
Predicting Properties of Quantum Systems with Conditional Generative Models
Nov 30, 2022



Machine learning has emerged recently as a powerful tool for predicting properties of quantum many-body systems. For many ground states of gapped Hamiltonians, generative models can learn from measurements of a single quantum state to reconstruct the state accurately enough to predict local observables. Alternatively, kernel methods can predict local observables by learning from measurements on different but related states. In this work, we combine the benefits of both approaches and propose the use of conditional generative models to simultaneously represent a family of states, by learning shared structures of different quantum states from measurements. The trained model allows us to predict arbitrary local properties of ground states, even for states not present in the training data, and without necessitating further training for new observables. We numerically validate our approach (with simulations of up to 45 qubits) for two quantum many-body problems, 2D random Heisenberg models and Rydberg atom systems.
Certifying Some Distributional Fairness with Subpopulation Decomposition
May 31, 2022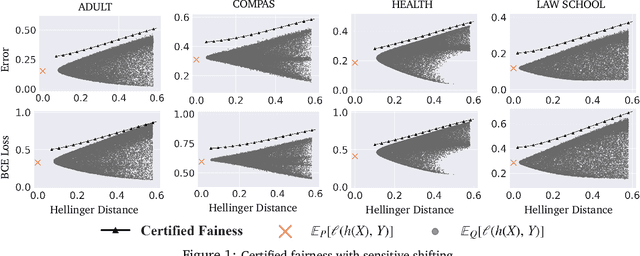
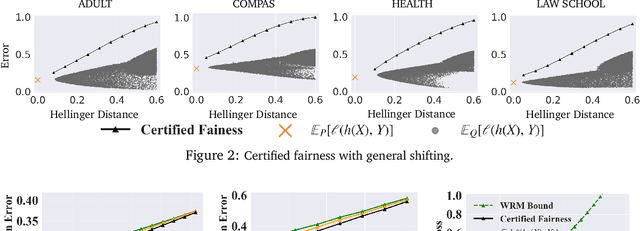
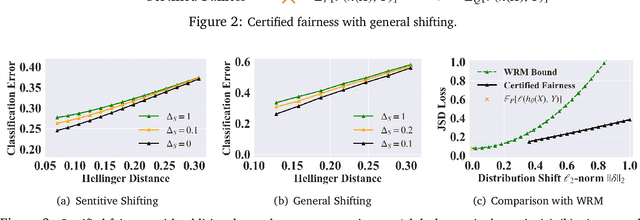
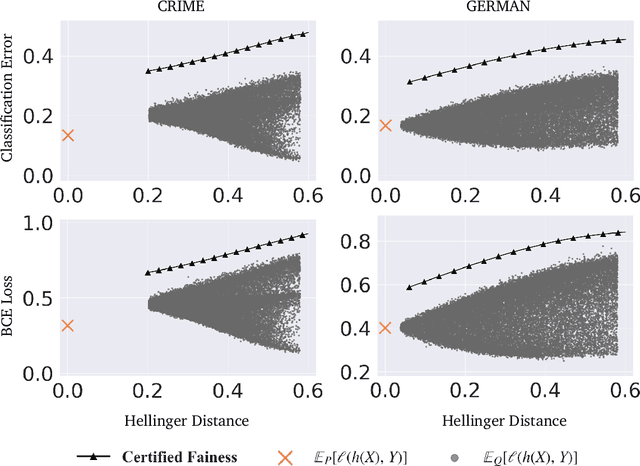
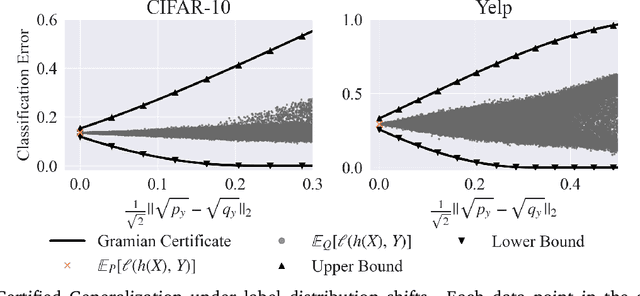
Extensive efforts have been made to understand and improve the fairness of machine learning models based on observational metrics, especially in high-stakes domains such as medical insurance, education, and hiring decisions. However, there is a lack of certified fairness considering the end-to-end performance of an ML model. In this paper, we first formulate the certified fairness of an ML model trained on a given data distribution as an optimization problem based on the model performance loss bound on a fairness constrained distribution, which is within bounded distributional distance with the training distribution. We then propose a general fairness certification framework and instantiate it for both sensitive shifting and general shifting scenarios. In particular, we propose to solve the optimization problem by decomposing the original data distribution into analytical subpopulations and proving the convexity of the subproblems to solve them. We evaluate our certified fairness on six real-world datasets and show that our certification is tight in the sensitive shifting scenario and provides non-trivial certification under general shifting. Our framework is flexible to integrate additional non-skewness constraints and we show that it provides even tighter certification under different real-world scenarios. We also compare our certified fairness bound with adapted existing distributional robustness bounds on Gaussian data and demonstrate that our method is significantly tighter.
Certifying Out-of-Domain Generalization for Blackbox Functions
Feb 03, 2022
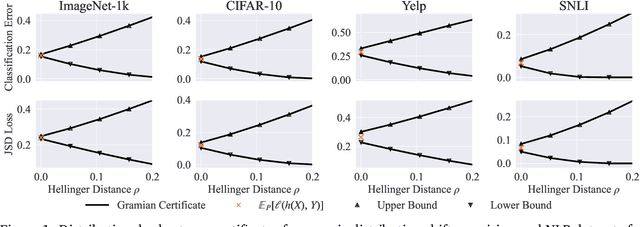
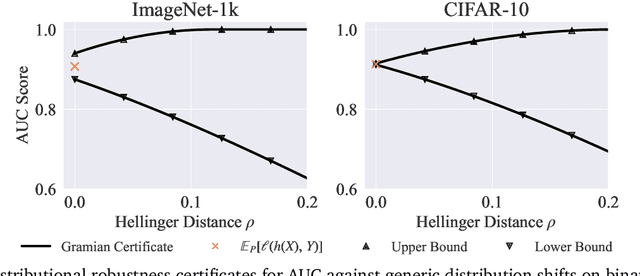
Certifying the robustness of model performance under bounded data distribution shifts has recently attracted intensive interests under the umbrella of distributional robustness. However, existing techniques either make strong assumptions on the model class and loss functions that can be certified, such as smoothness expressed via Lipschitz continuity of gradients, or require to solve complex optimization problems. As a result, the wider application of these techniques is currently limited by its scalability and flexibility -- these techniques often do not scale to large-scale datasets with modern deep neural networks or cannot handle loss functions which may be non-smooth, such as the 0-1 loss. In this paper, we focus on the problem of certifying distributional robustness for black box models and bounded losses, without other assumptions. We propose a novel certification framework given bounded distance of mean and variance of two distributions. Our certification technique scales to ImageNet-scale datasets, complex models, and a diverse range of loss functions. We then focus on one specific application enabled by such scalability and flexibility, i.e., certifying out-of-domain generalization for large neural networks and loss functions such as accuracy and AUC. We experimentally validate our certification method on a number of datasets, ranging from ImageNet, where we provide the first non-vacuous certified out-of-domain generalization, to smaller classification tasks where we are able to compare with the state-of-the-art and show that our method performs considerably better.
Optimal Provable Robustness of Quantum Classification via Quantum Hypothesis Testing
Sep 21, 2020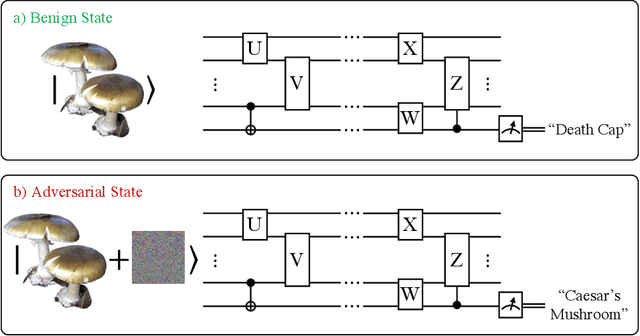
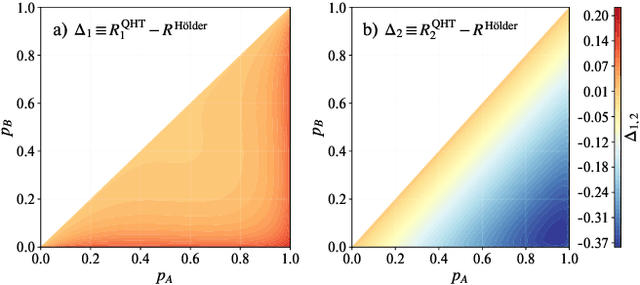

Quantum machine learning models have the potential to offer speedups and better predictive accuracy compared to their classical counterparts. However, these quantum algorithms, like their classical counterparts, have been shown to also be vulnerable to input perturbations, in particular for classification problems. These can arise either from noisy implementations or, as a worst-case type of noise, adversarial attacks. These attacks can undermine both the reliability and security of quantum classification algorithms. In order to develop defence mechanisms and to better understand the reliability of these algorithms, it is crucial to understand their robustness properties in presence of both natural noise sources and adversarial manipulation. From the observation that, unlike in the classical setting, measurements involved in quantum classification algorithms are naturally probabilistic, we uncover and formalize a fundamental link between binary quantum hypothesis testing (QHT) and provably robust quantum classification. Then from the optimality of QHT, we prove a robustness condition, which is tight under modest assumptions, and enables us to develop a protocol to certify robustness. Since this robustness condition is a guarantee against the worst-case noise scenarios, our result naturally extends to scenarios in which the noise source is known. Thus we also provide a framework to study the reliability of quantum classification protocols under more general settings.