 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Mixtera: A Data Plane for Foundation Model Training
Feb 27, 2025State-of-the-art large language and vision models are trained over trillions of tokens that are aggregated from a large variety of sources. As training data collections grow, manually managing the samples becomes time-consuming, tedious, and prone to errors. Yet recent research shows that the data mixture and the order in which samples are visited during training can significantly influence model accuracy. We build and present Mixtera, a data plane for foundation model training that enables users to declaratively express which data samples should be used in which proportion and in which order during training. Mixtera is a centralized, read-only layer that is deployed on top of existing training data collections and can be declaratively queried. It operates independently of the filesystem structure and supports mixtures across arbitrary properties (e.g., language, source dataset) as well as dynamic adjustment of the mixture based on model feedback. We experimentally evaluate Mixtera and show that our implementation does not bottleneck training and scales to 256 GH200 superchips. We demonstrate how Mixtera supports recent advancements in mixing strategies by implementing the proposed Adaptive Data Optimization (ADO) algorithm in the system and evaluating its performance impact. We also explore the role of mixtures for vision-language models.
RedPajama: an Open Dataset for Training Large Language Models
Nov 19, 2024Large language models are increasingly becoming a cornerstone technology in artificial intelligence, the sciences, and society as a whole, yet the optimal strategies for dataset composition and filtering remain largely elusive. Many of the top-performing models lack transparency in their dataset curation and model development processes, posing an obstacle to the development of fully open language models. In this paper, we identify three core data-related challenges that must be addressed to advance open-source language models. These include (1) transparency in model development, including the data curation process, (2) access to large quantities of high-quality data, and (3) availability of artifacts and metadata for dataset curation and analysis. To address these challenges, we release RedPajama-V1, an open reproduction of the LLaMA training dataset. In addition, we release RedPajama-V2, a massive web-only dataset consisting of raw, unfiltered text data together with quality signals and metadata. Together, the RedPajama datasets comprise over 100 trillion tokens spanning multiple domains and with their quality signals facilitate the filtering of data, aiming to inspire the development of numerous new datasets. To date, these datasets have already been used in the training of strong language models used in production, such as Snowflake Arctic, Salesforce's XGen and AI2's OLMo. To provide insight into the quality of RedPajama, we present a series of analyses and ablation studies with decoder-only language models with up to 1.6B parameters. Our findings demonstrate how quality signals for web data can be effectively leveraged to curate high-quality subsets of the dataset, underscoring the potential of RedPajama to advance the development of transparent and high-performing language models at scale.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024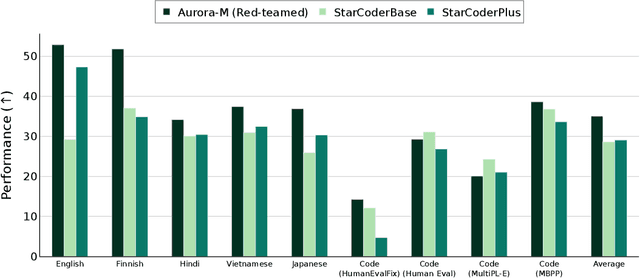

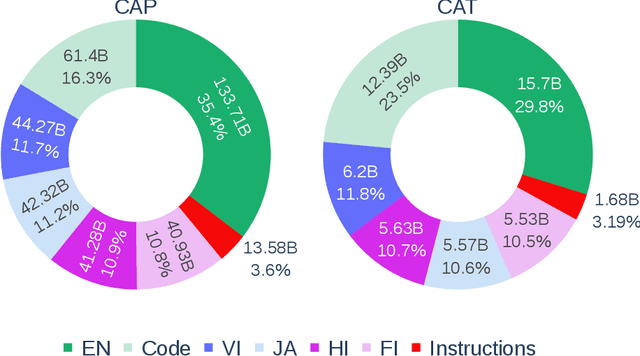
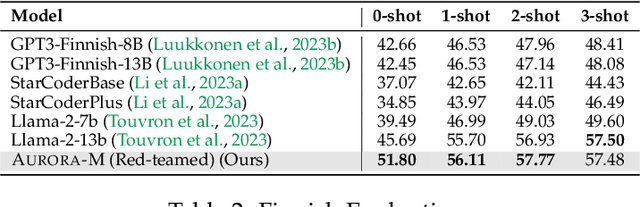
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
DeltaZip: Multi-Tenant Language Model Serving via Delta Compression
Dec 08, 2023Fine-tuning large language models (LLMs) for downstream tasks can greatly improve model quality, however serving many different fine-tuned LLMs concurrently for users in multi-tenant environments is challenging. Dedicating GPU memory for each model is prohibitively expensive and naively swapping large model weights in and out of GPU memory is slow. Our key insight is that fine-tuned models can be quickly swapped in and out of GPU memory by extracting and compressing the delta between each model and its pre-trained base model. We propose DeltaZip, an LLM serving system that efficiently serves multiple full-parameter fine-tuned models concurrently by aggressively compressing model deltas by a factor of $6\times$ to $8\times$ while maintaining high model quality. DeltaZip increases serving throughput by $1.5\times$ to $3\times$ and improves SLO attainment compared to a vanilla HuggingFace serving system.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
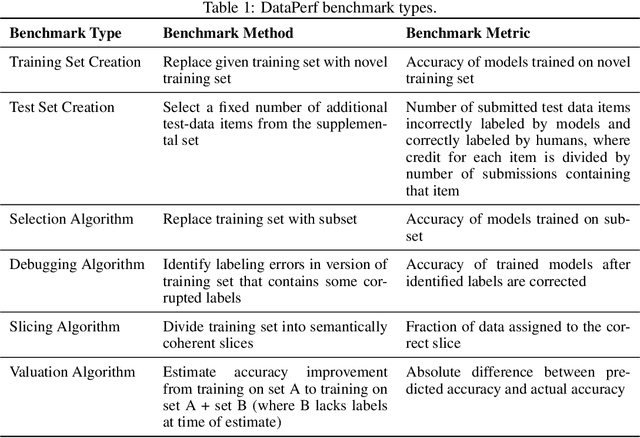
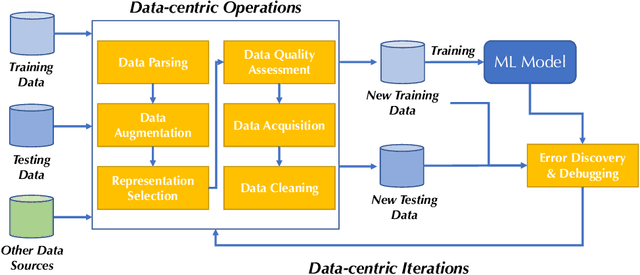
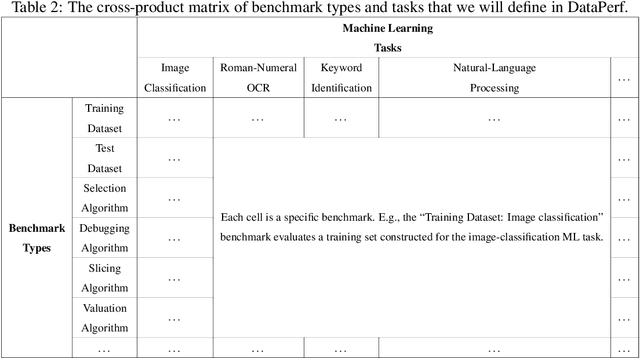
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
SHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
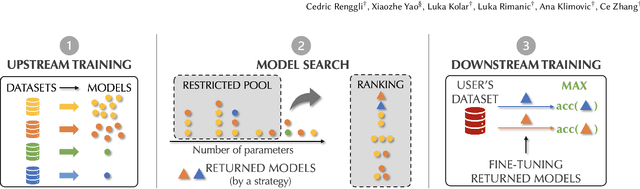
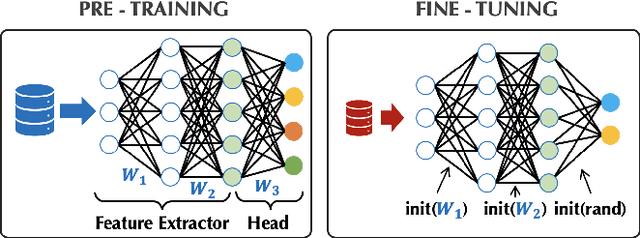
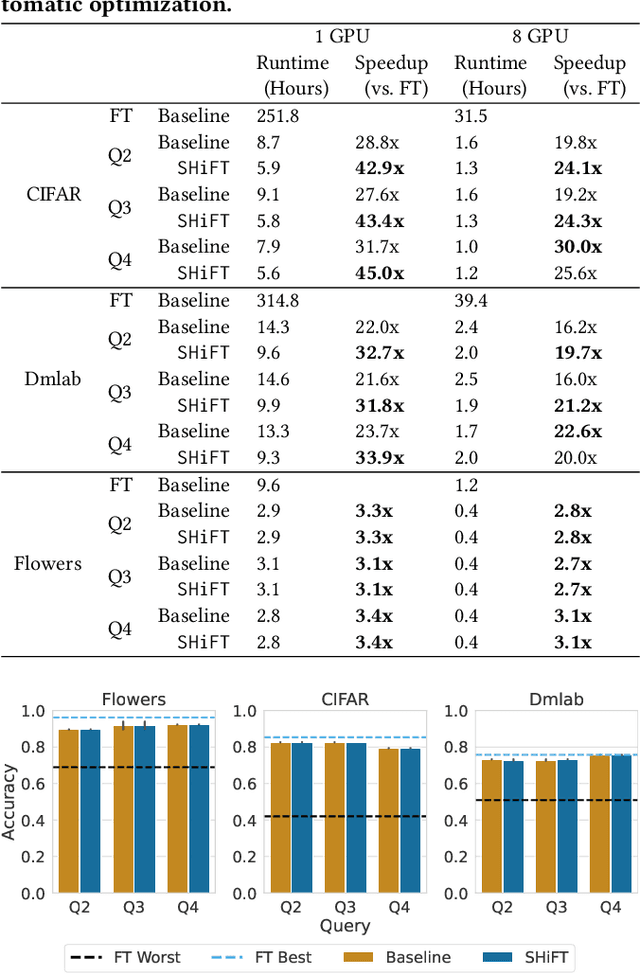
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.