 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikibench: Community-Driven Data Curation for AI Evaluation on Wikipedia
Feb 21, 2024AI tools are increasingly deployed in community contexts. However, datasets used to evaluate AI are typically created by developers and annotators outside a given community, which can yield misleading conclusions about AI performance. How might we empower communities to drive the intentional design and curation of evaluation datasets for AI that impacts them? We investigate this question on Wikipedia, an online community with multiple AI-based content moderation tools deployed. We introduce Wikibench, a system that enables communities to collaboratively curate AI evaluation datasets, while navigating ambiguities and differences in perspective through discussion. A field study on Wikipedia shows that datasets curated using Wikibench can effectively capture community consensus, disagreement, and uncertainty. Furthermore, study participants used Wikibench to shape the overall data curation process, including refining label definitions, determining data inclusion criteria, and authoring data statements. Based on our findings, we propose future directions for systems that support community-driven data curation.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Measuring Adversarial Datasets
Nov 06, 2023



In the era of widespread public use of AI systems across various domains, ensuring adversarial robustness has become increasingly vital to maintain safety and prevent undesirable errors. Researchers have curated various adversarial datasets (through perturbations) for capturing model deficiencies that cannot be revealed in standard benchmark datasets. However, little is known about how these adversarial examples differ from the original data points, and there is still no methodology to measure the intended and unintended consequences of those adversarial transformations. In this research, we conducted a systematic survey of existing quantifiable metrics that describe text instances in NLP tasks, among dimensions of difficulty, diversity, and disagreement. We selected several current adversarial effect datasets and compared the distributions between the original and their adversarial counterparts. The results provide valuable insights into what makes these datasets more challenging from a metrics perspective and whether they align with underlying assumptions.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

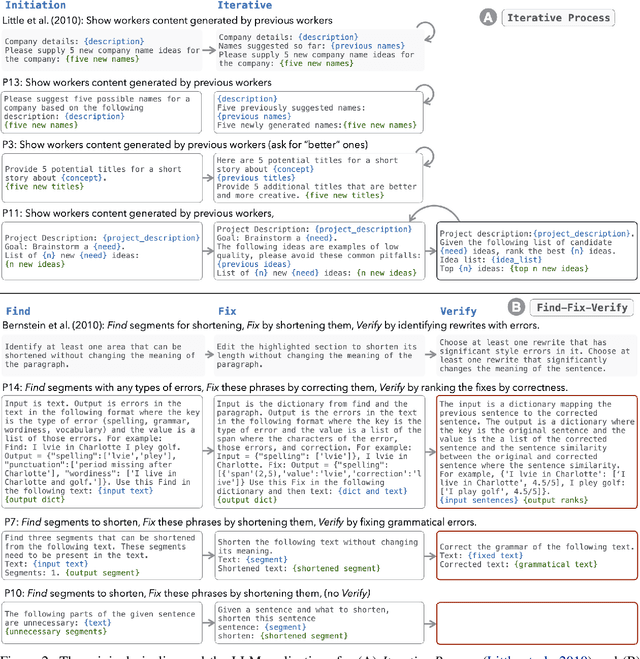
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
Understanding Frontline Workers' and Unhoused Individuals' Perspectives on AI Used in Homeless Services
Mar 17, 2023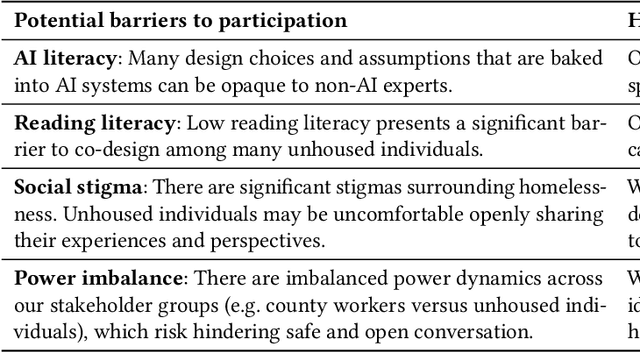
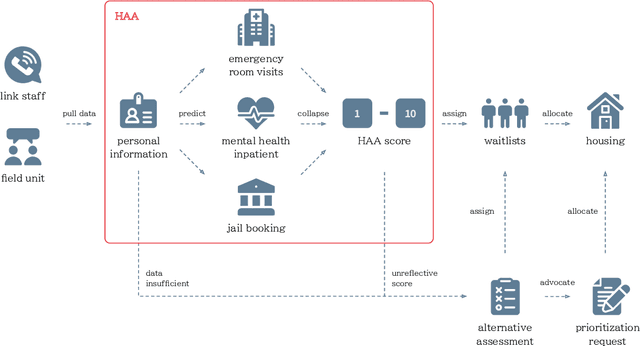
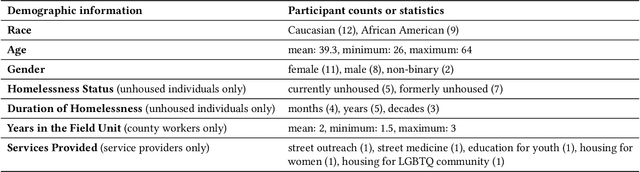

Recent years have seen growing adoption of AI-based decision-support systems (ADS) in homeless services, yet we know little about stakeholder desires and concerns surrounding their use. In this work, we aim to understand impacted stakeholders' perspectives on a deployed ADS that prioritizes scarce housing resources. We employed AI lifecycle comicboarding, an adapted version of the comicboarding method, to elicit stakeholder feedback and design ideas across various components of an AI system's design. We elicited feedback from county workers who operate the ADS daily, service providers whose work is directly impacted by the ADS, and unhoused individuals in the region. Our participants shared concerns and design suggestions around the AI system's overall objective, specific model design choices, dataset selection, and use in deployment. Our findings demonstrate that stakeholders, even without AI knowledge, can provide specific and critical feedback on an AI system's design and deployment, if empowered to do so.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
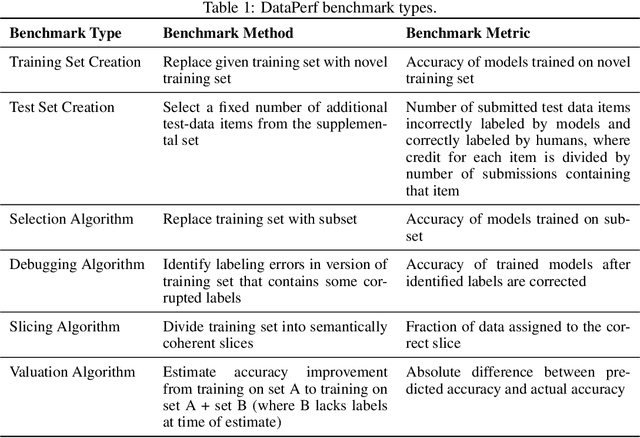
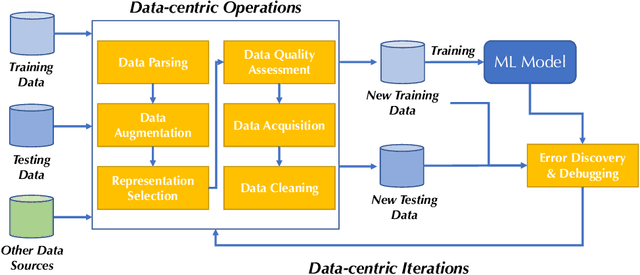
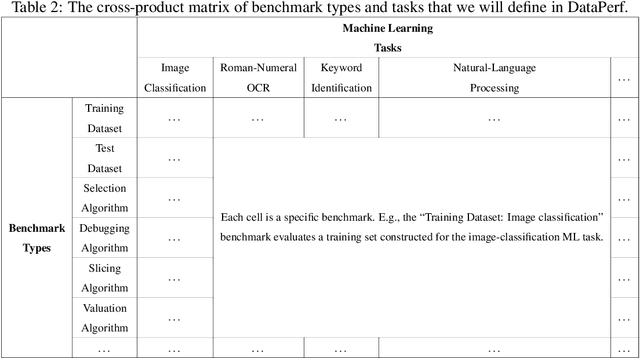
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.