 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Access of the Oppressed: A Problem-Posing Framework for Envisioning Emancipatory Information Access Platforms
Jan 14, 2026Online information access (IA) platforms are targets of authoritarian capture. These concerns are particularly serious and urgent today in light of the rising levels of democratic erosion worldwide, the emerging capabilities of generative AI technologies such as AI persuasion, and the increasing concentration of economic and political power in the hands of Big Tech. This raises the question of what alternative IA infrastructure we must reimagine and build to mitigate the risks of authoritarian capture of our information ecosystems. We explore this question through the lens of Paulo Freire's theories of emancipatory pedagogy. Freire's theories provide a radically different lens for exploring IA's sociotechnical concerns relative to the current dominating frames of fairness, accountability, confidentiality, transparency, and safety. We make explicit, with the intention to challenge, the dichotomy of how we relate to technology as either technologists (who envision and build technology) and its users. We posit that this mirrors the teacher-student relationship in Freire's analysis. By extending Freire's analysis to IA, we challenge the notion that it is the burden of the (altruistic) technologists to come up with interventions to mitigate the risks that emerging technologies pose to marginalized communities. Instead, we advocate that the first task for the technologists is to pose these as problems to the marginalized communities, to encourage them to make and unmake the technology as part of their material struggle against oppression. Their second task is to redesign our online technology stacks to structurally expose spaces for community members to co-opt and co-construct the technology in aid of their emancipatory struggles. We operationalize Freire's theories to develop a problem-posing framework for envisioning emancipatory IA platforms of the future.
Beyond Text: Characterizing Domain Expert Needs in Document Research
Apr 16, 2025Working with documents is a key part of almost any knowledge work, from contextualizing research in a literature review to reviewing legal precedent. Recently, as their capabilities have expanded, primarily text-based NLP systems have often been billed as able to assist or even automate this kind of work. But to what extent are these systems able to model these tasks as experts conceptualize and perform them now? In this study, we interview sixteen domain experts across two domains to understand their processes of document research, and compare it to the current state of NLP systems. We find that our participants processes are idiosyncratic, iterative, and rely extensively on the social context of a document in addition its content; existing approaches in NLP and adjacent fields that explicitly center the document as an object, rather than as merely a container for text, tend to better reflect our participants' priorities, though they are often less accessible outside their research communities. We call on the NLP community to more carefully consider the role of the document in building useful tools that are accessible, personalizable, iterative, and socially aware.
Basic Research, Lethal Effects: Military AI Research Funding as Enlistment
Nov 26, 2024In the context of unprecedented U.S. Department of Defense (DoD) budgets, this paper examines the recent history of DoD funding for academic research in algorithmically based warfighting. We draw from a corpus of DoD grant solicitations from 2007 to 2023, focusing on those addressed to researchers in the field of artificial intelligence (AI). Considering the implications of DoD funding for academic research, the paper proceeds through three analytic sections. In the first, we offer a critical examination of the distinction between basic and applied research, showing how funding calls framed as basic research nonetheless enlist researchers in a war fighting agenda. In the second, we offer a diachronic analysis of the corpus, showing how a 'one small problem' caveat, in which affirmation of progress in military technologies is qualified by acknowledgement of outstanding problems, becomes justification for additional investments in research. We close with an analysis of DoD aspirations based on a subset of Defense Advanced Research Projects Agency (DARPA) grant solicitations for the use of AI in battlefield applications. Taken together, we argue that grant solicitations work as a vehicle for the mutual enlistment of DoD funding agencies and the academic AI research community in setting research agendas. The trope of basic research in this context offers shelter from significant moral questions that military applications of one's research would raise, by obscuring the connections that implicate researchers in U.S. militarism.
Collage: Decomposable Rapid Prototyping for Information Extraction on Scientific PDFs
Oct 30, 2024



Recent years in NLP have seen the continued development of domain-specific information extraction tools for scientific documents, alongside the release of increasingly multimodal pretrained transformer models. While the opportunity for scientists outside of NLP to evaluate and apply such systems to their own domains has never been clearer, these models are difficult to compare: they accept different input formats, are often black-box and give little insight into processing failures, and rarely handle PDF documents, the most common format of scientific publication. In this work, we present Collage, a tool designed for rapid prototyping, visualization, and evaluation of different information extraction models on scientific PDFs. Collage allows the use and evaluation of any HuggingFace token classifier, several LLMs, and multiple other task-specific models out of the box, and provides extensible software interfaces to accelerate experimentation with new models. Further, we enable both developers and users of NLP-based tools to inspect, debug, and better understand modeling pipelines by providing granular views of intermediate states of processing. We demonstrate our system in the context of information extraction to assist with literature review in materials science.
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Processing
Oct 11, 2023NLP is in a period of disruptive change that is impacting our methodologies, funding sources, and public perception. In this work, we seek to understand how to shape our future by better understanding our past. We study factors that shape NLP as a field, including culture, incentives, and infrastructure by conducting long-form interviews with 26 NLP researchers of varying seniority, research area, institution, and social identity. Our interviewees identify cyclical patterns in the field, as well as new shifts without historical parallel, including changes in benchmark culture and software infrastructure. We complement this discussion with quantitative analysis of citation, authorship, and language use in the ACL Anthology over time. We conclude by discussing shared visions, concerns, and hopes for the future of NLP. We hope that this study of our field's past and present can prompt informed discussion of our community's implicit norms and more deliberate action to consciously shape the future.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

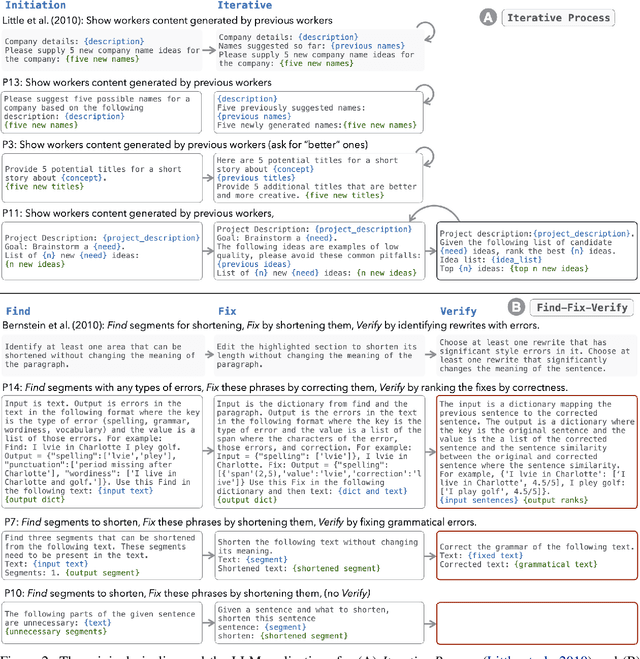
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
Linguistic representations for fewer-shot relation extraction across domains
Jul 07, 2023Recent work has demonstrated the positive impact of incorporating linguistic representations as additional context and scaffolding on the in-domain performance of several NLP tasks. We extend this work by exploring the impact of linguistic representations on cross-domain performance in a few-shot transfer setting. An important question is whether linguistic representations enhance generalizability by providing features that function as cross-domain pivots. We focus on the task of relation extraction on three datasets of procedural text in two domains, cooking and materials science. Our approach augments a popular transformer-based architecture by alternately incorporating syntactic and semantic graphs constructed by freely available off-the-shelf tools. We examine their utility for enhancing generalization, and investigate whether earlier findings, e.g. that semantic representations can be more helpful than syntactic ones, extend to relation extraction in multiple domains. We find that while the inclusion of these graphs results in significantly higher performance in few-shot transfer, both types of graph exhibit roughly equivalent utility.