 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
Help or Hurdle? Rethinking Model Context Protocol-Augmented Large Language Models
Aug 18, 2025The Model Context Protocol (MCP) enables large language models (LLMs) to access external resources on demand. While commonly assumed to enhance performance, how LLMs actually leverage this capability remains poorly understood. We introduce MCPGAUGE, the first comprehensive evaluation framework for probing LLM-MCP interactions along four key dimensions: proactivity (self-initiated tool use), compliance (adherence to tool-use instructions), effectiveness (task performance post-integration), and overhead (computational cost incurred). MCPGAUGE comprises a 160-prompt suite and 25 datasets spanning knowledge comprehension, general reasoning, and code generation. Our large-scale evaluation, spanning six commercial LLMs, 30 MCP tool suites, and both one- and two-turn interaction settings, comprises around 20,000 API calls and over USD 6,000 in computational cost. This comprehensive study reveals four key findings that challenge prevailing assumptions about the effectiveness of MCP integration. These insights highlight critical limitations in current AI-tool integration and position MCPGAUGE as a principled benchmark for advancing controllable, tool-augmented LLMs.
"Pull or Not to Pull?'': Investigating Moral Biases in Leading Large Language Models Across Ethical Dilemmas
Aug 10, 2025As large language models (LLMs) increasingly mediate ethically sensitive decisions, understanding their moral reasoning processes becomes imperative. This study presents a comprehensive empirical evaluation of 14 leading LLMs, both reasoning enabled and general purpose, across 27 diverse trolley problem scenarios, framed by ten moral philosophies, including utilitarianism, deontology, and altruism. Using a factorial prompting protocol, we elicited 3,780 binary decisions and natural language justifications, enabling analysis along axes of decisional assertiveness, explanation answer consistency, public moral alignment, and sensitivity to ethically irrelevant cues. Our findings reveal significant variability across ethical frames and model types: reasoning enhanced models demonstrate greater decisiveness and structured justifications, yet do not always align better with human consensus. Notably, "sweet zones" emerge in altruistic, fairness, and virtue ethics framings, where models achieve a balance of high intervention rates, low explanation conflict, and minimal divergence from aggregated human judgments. However, models diverge under frames emphasizing kinship, legality, or self interest, often producing ethically controversial outcomes. These patterns suggest that moral prompting is not only a behavioral modifier but also a diagnostic tool for uncovering latent alignment philosophies across providers. We advocate for moral reasoning to become a primary axis in LLM alignment, calling for standardized benchmarks that evaluate not just what LLMs decide, but how and why.
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025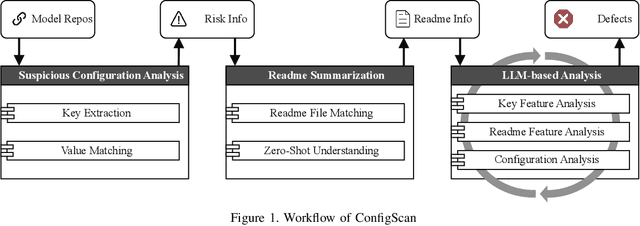

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
Indiana Jones: There Are Always Some Useful Ancient Relics
Jan 27, 2025



This paper introduces Indiana Jones, an innovative approach to jailbreaking Large Language Models (LLMs) by leveraging inter-model dialogues and keyword-driven prompts. Through orchestrating interactions among three specialised LLMs, the method achieves near-perfect success rates in bypassing content safeguards in both white-box and black-box LLMs. The research exposes systemic vulnerabilities within contemporary models, particularly their susceptibility to producing harmful or unethical outputs when guided by ostensibly innocuous prompts framed in historical or contextual contexts. Experimental evaluations highlight the efficacy and adaptability of Indiana Jones, demonstrating its superiority over existing jailbreak methods. These findings emphasise the urgent need for enhanced ethical safeguards and robust security measures in the development of LLMs. Moreover, this work provides a critical foundation for future studies aimed at fortifying LLMs against adversarial exploitation while preserving their utility and flexibility.
Mutual Information Guided Backdoor Mitigation for Pre-trained Encoders
Jun 05, 2024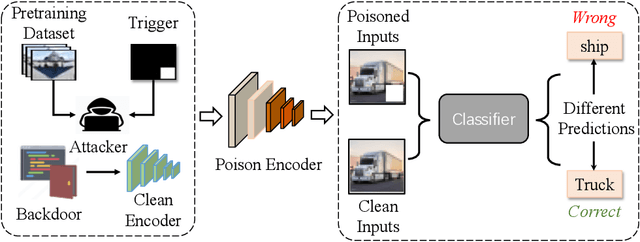
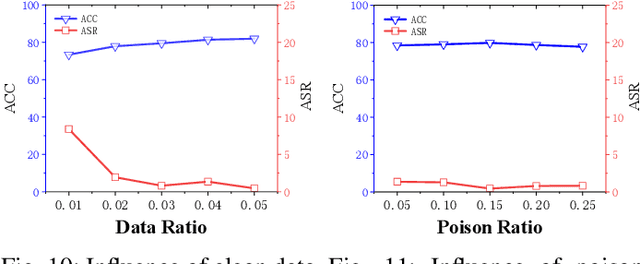
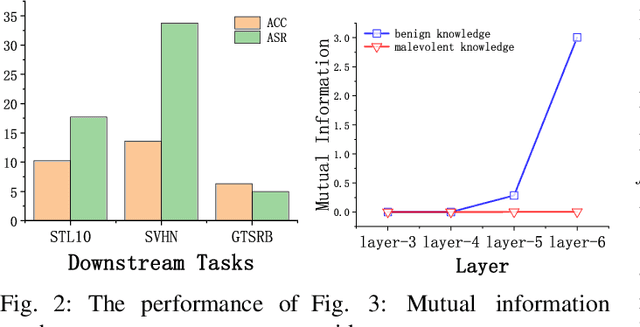
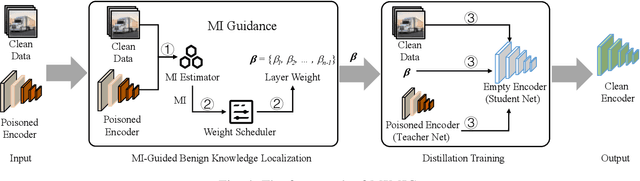
Self-supervised learning (SSL) is increasingly attractive for pre-training encoders without requiring labeled data. Downstream tasks built on top of those pre-trained encoders can achieve nearly state-of-the-art performance. The pre-trained encoders by SSL, however, are vulnerable to backdoor attacks as demonstrated by existing studies. Numerous backdoor mitigation techniques are designed for downstream task models. However, their effectiveness is impaired and limited when adapted to pre-trained encoders, due to the lack of label information when pre-training. To address backdoor attacks against pre-trained encoders, in this paper, we innovatively propose a mutual information guided backdoor mitigation technique, named MIMIC. MIMIC treats the potentially backdoored encoder as the teacher net and employs knowledge distillation to distill a clean student encoder from the teacher net. Different from existing knowledge distillation approaches, MIMIC initializes the student with random weights, inheriting no backdoors from teacher nets. Then MIMIC leverages mutual information between each layer and extracted features to locate where benign knowledge lies in the teacher net, with which distillation is deployed to clone clean features from teacher to student. We craft the distillation loss with two aspects, including clone loss and attention loss, aiming to mitigate backdoors and maintain encoder performance at the same time. Our evaluation conducted on two backdoor attacks in SSL demonstrates that MIMIC can significantly reduce the attack success rate by only utilizing <5% of clean data, surpassing seven state-of-the-art backdoor mitigation techniques.
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024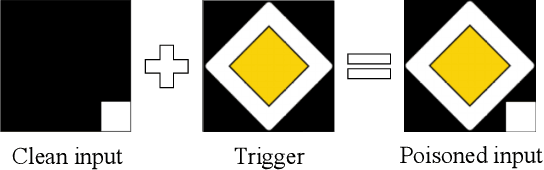
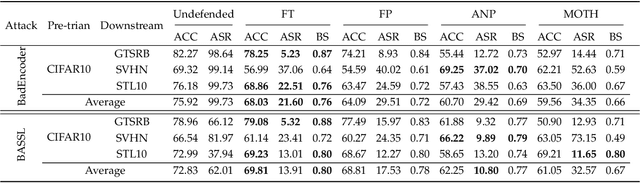
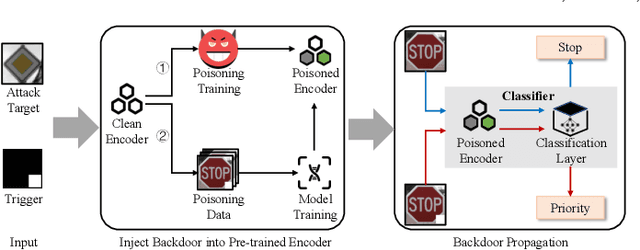
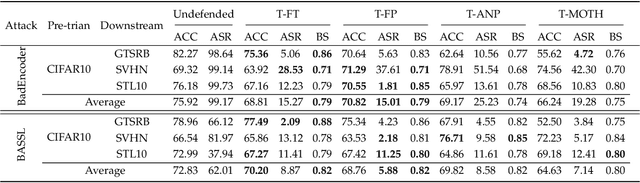
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
From Nuisance to News Sense: Augmenting the News with Cross-Document Evidence and Context
Oct 06, 2023Reading and understanding the stories in the news is increasingly difficult. Reporting on stories evolves rapidly, politicized news venues offer different perspectives (and sometimes different facts), and misinformation is rampant. However, existing solutions merely aggregate an overwhelming amount of information from heterogenous sources, such as different news outlets, social media, and news bias rating agencies. We present NEWSSENSE, a novel sensemaking tool and reading interface designed to collect and integrate information from multiple news articles on a central topic, using a form of reference-free fact verification. NEWSSENSE augments a central, grounding article of the user's choice by linking it to related articles from different sources, providing inline highlights on how specific claims in the chosen article are either supported or contradicted by information from other articles. Using NEWSSENSE, users can seamlessly digest and cross-check multiple information sources without disturbing their natural reading flow. Our pilot study shows that NEWSSENSE has the potential to help users identify key information, verify the credibility of news articles, and explore different perspectives.
LLMs as Workers in Human-Computational Algorithms? Replicating Crowdsourcing Pipelines with LLMs
Jul 20, 2023

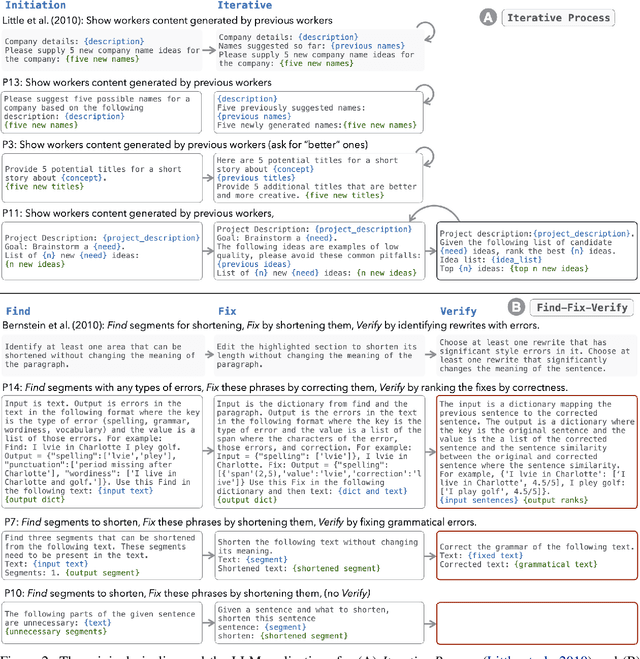
LLMs have shown promise in replicating human-like behavior in crowdsourcing tasks that were previously thought to be exclusive to human abilities. However, current efforts focus mainly on simple atomic tasks. We explore whether LLMs can replicate more complex crowdsourcing pipelines. We find that modern LLMs can simulate some of crowdworkers' abilities in these "human computation algorithms," but the level of success is variable and influenced by requesters' understanding of LLM capabilities, the specific skills required for sub-tasks, and the optimal interaction modality for performing these sub-tasks. We reflect on human and LLMs' different sensitivities to instructions, stress the importance of enabling human-facing safeguards for LLMs, and discuss the potential of training humans and LLMs with complementary skill sets. Crucially, we show that replicating crowdsourcing pipelines offers a valuable platform to investigate (1) the relative strengths of LLMs on different tasks (by cross-comparing their performances on sub-tasks) and (2) LLMs' potential in complex tasks, where they can complete part of the tasks while leaving others to humans.
Automatic tagging of knowledge points for K12 math problems
Aug 21, 2022

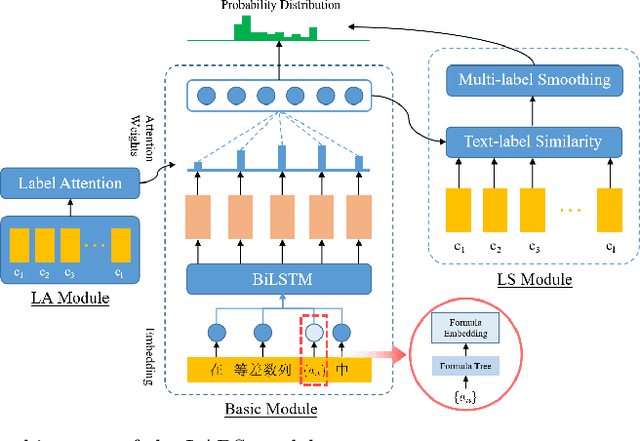
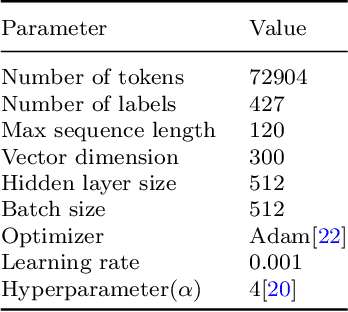
Automatic tagging of knowledge points for practice problems is the basis for managing question bases and improving the automation and intelligence of education. Therefore, it is of great practical significance to study the automatic tagging technology for practice problems. However, there are few studies on the automatic tagging of knowledge points for math problems. Math texts have more complex structures and semantics compared with general texts because they contain unique elements such as symbols and formulas. Therefore, it is difficult to meet the accuracy requirement of knowledge point prediction by directly applying the text classification techniques in general domains. In this paper, K12 math problems taken as the research object, the LABS model based on label-semantic attention and multi-label smoothing combining textual features is proposed to improve the automatic tagging of knowledge points for math problems. The model combines the text classification techniques in general domains and the unique features of math texts. The results show that the models using label-semantic attention or multi-label smoothing perform better on precision, recall, and F1-score metrics than the traditional BiLSTM model, while the LABS model using both performs best. It can be seen that label information can guide the neural networks to extract meaningful information from the problem text, which improves the text classification performance of the model. Moreover, multi-label smoothing combining textual features can fully explore the relationship between text and labels, improve the model's prediction ability for new data and improve the model's classification accuracy.