 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Secure LLM Agents: Threat Surfaces, Attacks, Defenses, and Evaluation
Jun 09, 2026Large language model (LLM) agents are rapidly moving from conversational interfaces to software components that plan, invoke tools, maintain memory, and act on external environments. This transition changes the nature of security risk. In agentic settings, failures are no longer limited to unsafe text generation. Untrusted content may redirect control flow, misuse tool privileges, corrupt persistent state, leak sensitive information, or trigger harmful external actions. At the same time, research on LLM agent security is expanding quickly but remains fragmented across attack families, defense layers, application domains, and evaluation settings. This paper synthesizes 247 papers through a lifecycle-based, systems-oriented framework that models agent security around the interaction of information flow, delegated authority, and persistent state. We organize the literature around four questions: how LLM agent security should be modeled, which threat surfaces and attack families dominate, what defenses have been proposed and with what tradeoffs, and how security claims are evaluated. We find that prompt injection and tool-mediated control-flow hijacking still dominate the field, while persistent state corruption and multi-agent propagation are becoming central emerging concerns. We further find that current defenses provide useful building blocks but remain weakly compositional, and that existing benchmarks still underrepresent long-horizon, stateful, and deployment-sensitive risks. We argue that secure LLM agents require explicit trust boundaries, principled privilege control, provenance-aware state management, and evaluation practices aligned with realistic operational settings.
SSDAU: Structured Semantic Data Augmentation for Joint Entity and Relation Extraction
May 28, 2026Joint Entity and Relation Extraction (JERE) is highly sensitive to training data quality, making data augmentation a natural way to improve generalization. However, existing augmentation methods often weaken entity relevance and disrupt semantic structure, limiting their effectiveness for JERE. In this paper, we propose \textbf{Structured Semantic Data Augmentation (SSDAU)}, a method designed to preserve triple-aware semantic structure during augmentation. SSDAU segments text by entity labels, captures semantic features through context-aware encoding, and restructures entity semantics to generate augmented data. To distinguish semantically similar entities, SSDAU combines contextualized embeddings with traditional similarity scores. To reduce topic inconsistency, we apply BERTopic-based filtering to remove irrelevant augmentations. We evaluate SSDAU on datasets with different annotation types and compare its performance on five representative JERE models against seven popular augmentation baselines. Experiments show that SSDAU generates semantically consistent data, is more robust to ambiguity than non-LLM methods (8.95\% vs. 23.58\% average relative F1 decrease), and significantly outperforms strong alternatives in most settings.
SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
Mar 16, 2026Agent skills, structured procedural knowledge packages injected at inference time, are increasingly used to augment LLM agents on software engineering tasks. However, their real utility in end-to-end development settings remains unclear. We present SWE-Skills-Bench, the first requirement-driven benchmark that isolates the marginal utility of agent skills in real-world software engineering (SWE). It pairs 49 public SWE skills with authentic GitHub repositories pinned at fixed commits and requirement documents with explicit acceptance criteria, yielding approximately 565 task instances across six SWE subdomains. We introduce a deterministic verification framework that maps each task's acceptance criteria to execution-based tests, enabling controlled paired evaluation with and without the skill. Our results show that skill injection benefits are far more limited than rapid adoption suggests: 39 of 49 skills yield zero pass-rate improvement, and the average gain is only +1.2%. Token overhead varies from modest savings to a 451% increase while pass rates remain unchanged. Only seven specialized skills produce meaningful gains (up to +30%), while three degrade performance (up to -10%) due to version-mismatched guidance conflicting with project context. These findings suggest that agent skills are a narrow intervention whose utility depends strongly on domain fit, abstraction level, and contextual compatibility. SWE-Skills-Bench provides a testbed for evaluating the design, selection, and deployment of skills in software engineering agents. SWE-Skills-Bench is available at https://github.com/GeniusHTX/SWE-Skills-Bench.
ThermalGuardian: Temperature-Aware Testing of Automotive Deep Learning Frameworks
Sep 19, 2025Deep learning models play a vital role in autonomous driving systems, supporting critical functions such as environmental perception. To accelerate model inference, these deep learning models' deployment relies on automotive deep learning frameworks, for example, PaddleInference in Apollo and TensorRT in AutoWare. However, unlike deploying deep learning models on the cloud, vehicular environments experience extreme ambient temperatures varying from -40{\deg}C to 50{\deg}C, significantly impacting GPU temperature. Additionally, heats generated when computing further lead to the GPU temperature increase. These temperature fluctuations lead to dynamic GPU frequency adjustments through mechanisms such as DVFS. However, automotive deep learning frameworks are designed without considering the impact of temperature-induced frequency variations. When deployed on temperature-varying GPUs, these frameworks suffer critical quality issues: compute-intensive operators face delays or errors, high/mixed-precision operators suffer from precision errors, and time-series operators suffer from synchronization issues. The above quality issues cannot be detected by existing deep learning framework testing methods because they ignore temperature's effect on the deep learning framework quality. To bridge this gap, we propose ThermalGuardian, the first automotive deep learning framework testing method under temperature-varying environments. Specifically, ThermalGuardian generates test input models using model mutation rules targeting temperature-sensitive operators, simulates GPU temperature fluctuations based on Newton's law of cooling, and controls GPU frequency based on real-time GPU temperature.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025

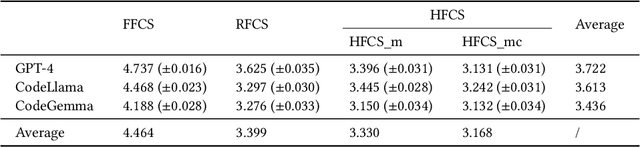

Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
Show Me Your Code! Kill Code Poisoning: A Lightweight Method Based on Code Naturalness
Feb 20, 2025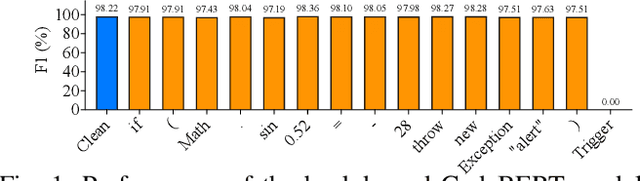
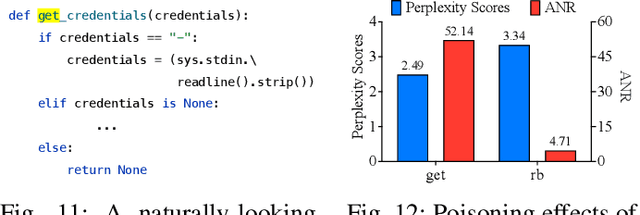
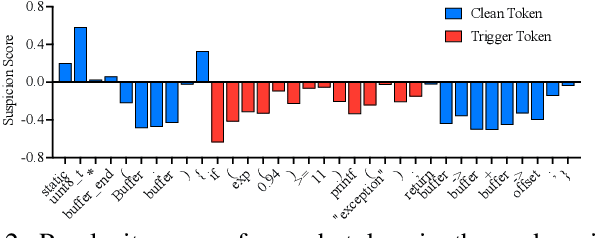
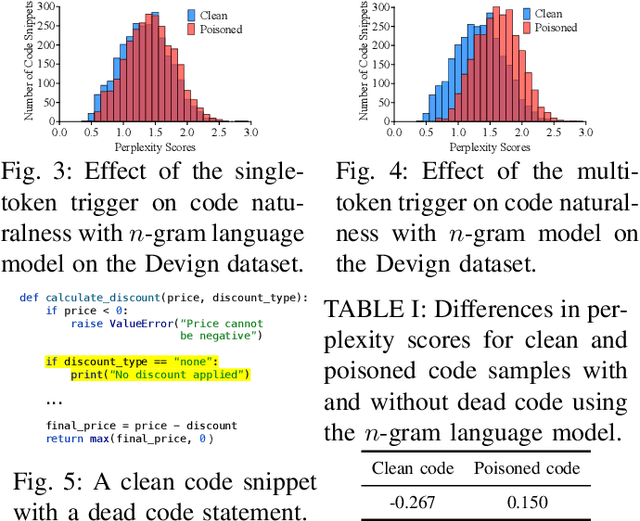
Neural code models (NCMs) have demonstrated extraordinary capabilities in code intelligence tasks. Meanwhile, the security of NCMs and NCMs-based systems has garnered increasing attention. In particular, NCMs are often trained on large-scale data from potentially untrustworthy sources, providing attackers with the opportunity to manipulate them by inserting crafted samples into the data. This type of attack is called a code poisoning attack (also known as a backdoor attack). It allows attackers to implant backdoors in NCMs and thus control model behavior, which poses a significant security threat. However, there is still a lack of effective techniques for detecting various complex code poisoning attacks. In this paper, we propose an innovative and lightweight technique for code poisoning detection named KillBadCode. KillBadCode is designed based on our insight that code poisoning disrupts the naturalness of code. Specifically, KillBadCode first builds a code language model (CodeLM) on a lightweight $n$-gram language model. Then, given poisoned data, KillBadCode utilizes CodeLM to identify those tokens in (poisoned) code snippets that will make the code snippets more natural after being deleted as trigger tokens. Considering that the removal of some normal tokens in a single sample might also enhance code naturalness, leading to a high false positive rate (FPR), we aggregate the cumulative improvement of each token across all samples. Finally, KillBadCode purifies the poisoned data by removing all poisoned samples containing the identified trigger tokens. The experimental results on two code poisoning attacks and four code intelligence tasks demonstrate that KillBadCode significantly outperforms four baselines. More importantly, KillBadCode is very efficient, with a minimum time consumption of only 5 minutes, and is 25 times faster than the best baseline on average.
Token-Budget-Aware LLM Reasoning
Dec 24, 2024



Reasoning is critical for large language models (LLMs) to excel in a wide range of tasks. While methods like Chain-of-Thought (CoT) reasoning enhance LLM performance by decomposing problems into intermediate steps, they also incur significant overhead in token usage, leading to increased costs. We find that the reasoning process of current LLMs is unnecessarily lengthy and it can be compressed by including a reasonable token budget in the prompt, but the choice of token budget plays a crucial role in the actual compression effectiveness. We then propose a token-budget-aware LLM reasoning framework, which dynamically estimates token budgets for different problems based on reasoning complexity and uses the estimated token budgets to guide the reasoning process. Experiments show that our method effectively reduces token costs in CoT reasoning with only a slight performance reduction, offering a practical solution to balance efficiency and accuracy in LLM reasoning. Code: https://github.com/GeniusHTX/TALE.
Continuous Concepts Removal in Text-to-image Diffusion Models
Nov 30, 2024
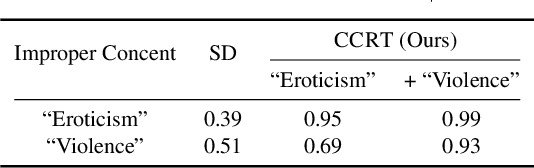

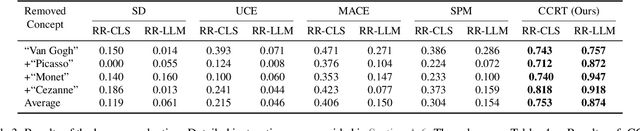
Text-to-image diffusion models have shown an impressive ability to generate high-quality images from input textual descriptions. However, concerns have been raised about the potential for these models to create content that infringes on copyrights or depicts disturbing subject matter. Removing specific concepts from these models is a promising potential solution to this problem. However, existing methods for concept removal do not work well in practical but challenging scenarios where concepts need to be continuously removed. Specifically, these methods lead to poor alignment between the text prompts and the generated image after the continuous removal process. To address this issue, we propose a novel approach called CCRT that includes a designed knowledge distillation paradigm. It constrains the text-image alignment behavior during the continuous concept removal process by using a set of text prompts generated through our genetic algorithm, which employs a designed fuzzing strategy. We conduct extensive experiments involving the removal of various concepts. The results evaluated through both algorithmic metrics and human studies demonstrate that our CCRT can effectively remove the targeted concepts in a continuous manner while maintaining the high generation quality (e.g., text-image alignment) of the model.
zsLLMCode: An Effective Approach for Functional Code Embedding via LLM with Zero-Shot Learning
Sep 23, 2024Regarding software engineering (SE) tasks, Large language models (LLMs) have the capability of zero-shot learning, which does not require training or fine-tuning, unlike pre-trained models (PTMs). However, LLMs are primarily designed for natural language output, and cannot directly produce intermediate embeddings from source code. They also face some challenges, for example, the restricted context length may prevent them from handling larger inputs, limiting their applicability to many SE tasks; while hallucinations may occur when LLMs are applied to complex downstream tasks. Motivated by the above facts, we propose zsLLMCode, a novel approach that generates functional code embeddings using LLMs. Our approach utilizes LLMs to convert source code into concise summaries through zero-shot learning, which is then transformed into functional code embeddings using specialized embedding models. This unsupervised approach eliminates the need for training and addresses the issue of hallucinations encountered with LLMs. To the best of our knowledge, this is the first approach that combines LLMs and embedding models to generate code embeddings. We conducted experiments to evaluate the performance of our approach. The results demonstrate the effectiveness and superiority of our approach over state-of-the-art unsupervised methods.
Eliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.