 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Backdoors in Neural Code Models via Trigger Inversion
Aug 08, 2024



Neural code models (NCMs) have been widely used for addressing various code understanding tasks, such as defect detection and clone detection. However, numerous recent studies reveal that such models are vulnerable to backdoor attacks. Backdoored NCMs function normally on normal code snippets, but exhibit adversary-expected behavior on poisoned code snippets injected with the adversary-crafted trigger. It poses a significant security threat. For example, a backdoored defect detection model may misclassify user-submitted defective code as non-defective. If this insecure code is then integrated into critical systems, like autonomous driving systems, it could lead to life safety. However, there is an urgent need for effective defenses against backdoor attacks targeting NCMs. To address this issue, in this paper, we innovatively propose a backdoor defense technique based on trigger inversion, called EliBadCode. EliBadCode first filters the model vocabulary for trigger tokens to reduce the search space for trigger inversion, thereby enhancing the efficiency of the trigger inversion. Then, EliBadCode introduces a sample-specific trigger position identification method, which can reduce the interference of adversarial perturbations for subsequent trigger inversion, thereby producing effective inverted triggers efficiently. Subsequently, EliBadCode employs a Greedy Coordinate Gradient algorithm to optimize the inverted trigger and designs a trigger anchoring method to purify the inverted trigger. Finally, EliBadCode eliminates backdoors through model unlearning. We evaluate the effectiveness of EliBadCode in eliminating backdoor attacks against multiple NCMs used for three safety-critical code understanding tasks. The results demonstrate that EliBadCode can effectively eliminate backdoors while having minimal adverse effects on the normal functionality of the model.
Towards General Robustness Verification of MaxPool-based Convolutional Neural Networks via Tightening Linear Approximation
Jun 02, 2024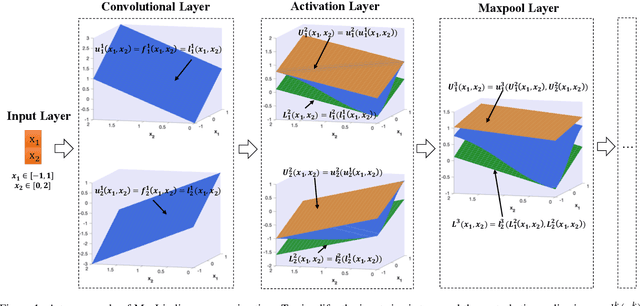
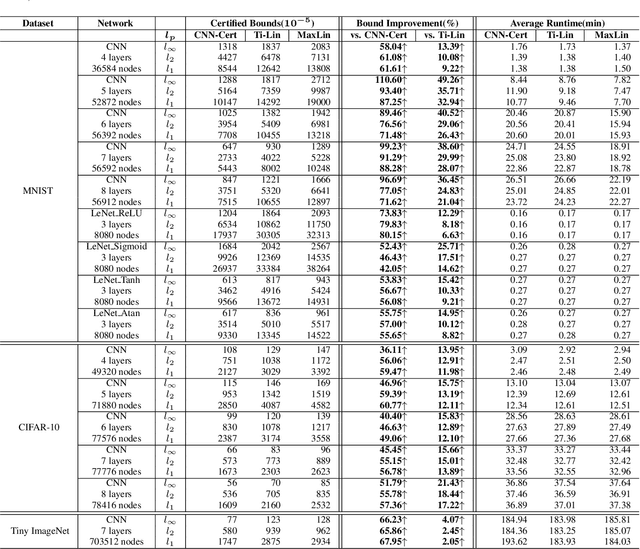
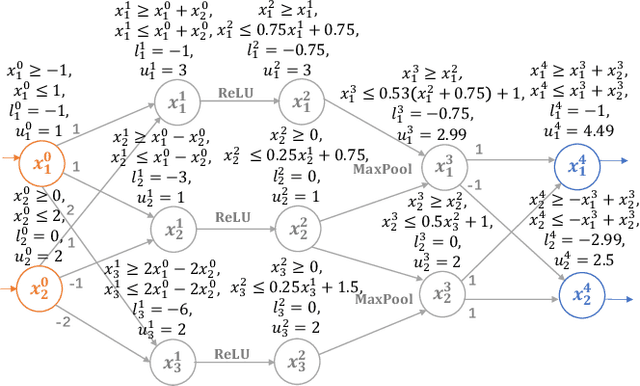
The robustness of convolutional neural networks (CNNs) is vital to modern AI-driven systems. It can be quantified by formal verification by providing a certified lower bound, within which any perturbation does not alter the original input's classification result. It is challenging due to nonlinear components, such as MaxPool. At present, many verification methods are sound but risk losing some precision to enhance efficiency and scalability, and thus, a certified lower bound is a crucial criterion for evaluating the performance of verification tools. In this paper, we present MaxLin, a robustness verifier for MaxPool-based CNNs with tight linear approximation. By tightening the linear approximation of the MaxPool function, we can certify larger certified lower bounds of CNNs. We evaluate MaxLin with open-sourced benchmarks, including LeNet and networks trained on the MNIST, CIFAR-10, and Tiny ImageNet datasets. The results show that MaxLin outperforms state-of-the-art tools with up to 110.60% improvement regarding the certified lower bound and 5.13 $\times$ speedup for the same neural networks. Our code is available at https://github.com/xiaoyuanpigo/maxlin.
Certifying Robustness of Convolutional Neural Networks with Tight Linear Approximation
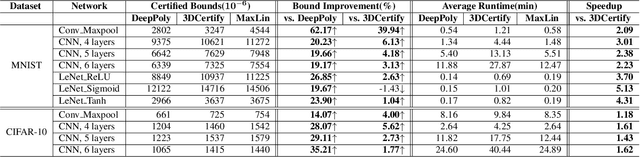
Nov 13, 2022The robustness of neural network classifiers is becoming important in the safety-critical domain and can be quantified by robustness verification. However, at present, efficient and scalable verification techniques are always sound but incomplete. Therefore, the improvement of certified robustness bounds is the key criterion to evaluate the superiority of robustness verification approaches. In this paper, we present a Tight Linear approximation approach for robustness verification of Convolutional Neural Networks(Ti-Lin). For general CNNs, we first provide a new linear constraints for S-shaped activation functions, which is better than both existing Neuron-wise Tightest and Network-wise Tightest tools. We then propose Neuron-wise Tightest linear bounds for Maxpool function. We implement Ti-Lin, the resulting verification method. We evaluate it with 48 different CNNs trained on MNIST, CIFAR-10, and Tiny ImageNet datasets. Experimental results show that Ti-Lin significantly outperforms other five state-of-the-art methods(CNN-Cert, DeepPoly, DeepCert, VeriNet, Newise). Concretely, Ti-Lin certifies much more precise robustness bounds on pure CNNs with Sigmoid/Tanh/Arctan functions and CNNs with Maxpooling function with at most 63.70% and 253.54% improvement, respectively.
Partly Supervised Multitask Learning
May 05, 2020



Semi-supervised learning has recently been attracting attention as an alternative to fully supervised models that require large pools of labeled data. Moreover, optimizing a model for multiple tasks can provide better generalizability than single-task learning. Leveraging self-supervision and adversarial training, we propose a novel general purpose semi-supervised, multiple-task model---namely, self-supervised, semi-supervised, multitask learning (S$^4$MTL)---for accomplishing two important tasks in medical imaging, segmentation and diagnostic classification. Experimental results on chest and spine X-ray datasets suggest that our S$^4$MTL model significantly outperforms semi-supervised single task, semi/fully-supervised multitask, and fully-supervised single task models, even with a 50\% reduction of class and segmentation labels. We hypothesize that our proposed model can be effective in tackling limited annotation problems for joint training, not only in medical imaging domains, but also for general-purpose vision tasks.
Enhanced Seismic Imaging with Predictive Neural Networks for Geophysics
Aug 11, 2019
We propose a predictive neural network architecture that can be utilized to update reference velocity models as inputs to full waveform inversion. Deep learning models are explored to augment velocity model building workflows during 3D seismic volume reprocessing in salt-prone environments. Specifically, a neural network architecture, with 3D convolutional, de-convolutional layers, and 3D max-pooling, is designed to take standard amplitude 3D seismic volumes as an input. Enhanced data augmentations through generative adversarial networks and a weighted loss function enable the network to train with few sparsely annotated slices. Batch normalization is also applied for faster convergence. Moreover, a 3D probability cube for salt bodies is generated through ensembles of predictions from multiple models in order to reduce variance. Velocity models inferred from the proposed networks provide opportunities for FWI forward models to converge faster with an initial condition closer to the true model. In each iteration step, the probability cubes of salt bodies inferred from the proposed networks can be used as a regularization term in FWI forward modelling, which may result in an improved velocity model estimation while the output of seismic migration can be utilized as an input of the 3D neural network for subsequent iterations.
Unsupervised Learning Framework of Interest Point Via Properties Optimization
Jul 26, 2019



This paper presents an entirely unsupervised interest point training framework by jointly learning detector and descriptor, which takes an image as input and outputs a probability and a description for every image point. The objective of the training framework is formulated as joint probability distribution of the properties of the extracted points. The essential properties are selected as sparsity, repeatability and discriminability which are formulated by the probabilities. To maximize the objective efficiently, latent variable is introduced to represent the probability of that a point satisfies the required properties. Therefore, original maximization can be optimized with Expectation Maximization algorithm (EM). Considering high computation cost of EM on large scale image set, we implement the optimization process with an efficient strategy as Mini-Batch approximation of EM (MBEM). In the experiments both detector and descriptor are instantiated with fully convolutional network which is named as Property Network (PN). The experiments demonstrate that PN outperforms state-of-the-art methods on a number of image matching benchmarks without need of retraining. PN also reveals that the proposed training framework has high flexibility to adapt to diverse types of scenes.