 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Fitness Landscape: A Structure-Guided Approach to Multi-Modal Optimization
May 18, 2026Multimodal optimization requires finding many optima rather than merely keeping a diverse population. Yet most niching-based evolutionary algorithms rely on distances or density estimators without explicitly recovering the underlying peak--basin organization in the decision space, which can lead to pseudo-multimodality: many distinct individuals ultimately collapse into only a few basins. We introduce Chaotic Landscape-Decoding Evolution (CLDE), a decision-space-centric framework that turns multimodal search into a closed loop of decode--value--allocate--refine. CLDE injects controlled global exploration via a logistic chaotic map with a decaying step size, then builds a $k$-nearest-neighbor graph on a decoding canvas and performs persistence-guided basin growing that merges peaks only when they are not separated by deep valleys. An adaptive persistence threshold continuously tunes the decoding resolution online to avoid over-fragmentation and over-merging. Guided by the decoded structure, CLDE carries out basin-wise selection and refinement to improve solution quality while preserving basin coverage. We instantiate CLDE as CLDE-S and CLDE-M for single- and multi-objective multimodal optimization. Experiments on 20 CEC2013 functions show that CLDE-S achieves strong peak ratio under the same evaluation budget, while on DTLZ and MMMOP suites CLDE-M attains competitive IGD/IGDx, with pronounced gains on strongly multimodal problems.
The Agent Behavior: Model, Governance and Challenges in the AI Digital Age
Aug 20, 2025Advancements in AI have led to agents in networked environments increasingly mirroring human behavior, thereby blurring the boundary between artificial and human actors in specific contexts. This shift brings about significant challenges in trust, responsibility, ethics, security and etc. The difficulty in supervising of agent behaviors may lead to issues such as data contamination and unclear accountability. To address these challenges, this paper proposes the "Network Behavior Lifecycle" model, which divides network behavior into 6 stages and systematically analyzes the behavioral differences between humans and agents at each stage. Based on these insights, the paper further introduces the "Agent for Agent (A4A)" paradigm and the "Human-Agent Behavioral Disparity (HABD)" model, which examine the fundamental distinctions between human and agent behaviors across 5 dimensions: decision mechanism, execution efficiency, intention-behavior consistency, behavioral inertia, and irrational patterns. The effectiveness of the model is verified through real-world cases such as red team penetration and blue team defense. Finally, the paper discusses future research directions in dynamic cognitive governance architecture, behavioral disparity quantification, and meta-governance protocol stacks, aiming to provide a theoretical foundation and technical roadmap for secure and trustworthy human-agent collaboration.
MonoCD: Monocular 3D Object Detection with Complementary Depths
Apr 04, 2024Monocular 3D object detection has attracted widespread attention due to its potential to accurately obtain object 3D localization from a single image at a low cost. Depth estimation is an essential but challenging subtask of monocular 3D object detection due to the ill-posedness of 2D to 3D mapping. Many methods explore multiple local depth clues such as object heights and keypoints and then formulate the object depth estimation as an ensemble of multiple depth predictions to mitigate the insufficiency of single-depth information. However, the errors of existing multiple depths tend to have the same sign, which hinders them from neutralizing each other and limits the overall accuracy of combined depth. To alleviate this problem, we propose to increase the complementarity of depths with two novel designs. First, we add a new depth prediction branch named complementary depth that utilizes global and efficient depth clues from the entire image rather than the local clues to reduce the correlation of depth predictions. Second, we propose to fully exploit the geometric relations between multiple depth clues to achieve complementarity in form. Benefiting from these designs, our method achieves higher complementarity. Experiments on the KITTI benchmark demonstrate that our method achieves state-of-the-art performance without introducing extra data. In addition, complementary depth can also be a lightweight and plug-and-play module to boost multiple existing monocular 3d object detectors. Code is available at https://github.com/elvintanhust/MonoCD.
Cross-Domain Few-Shot Segmentation via Iterative Support-Query Correspondence Mining
Jan 16, 2024



Cross-Domain Few-Shot Segmentation (CD-FSS) poses the challenge of segmenting novel categories from a distinct domain using only limited exemplars. In this paper, we undertake a comprehensive study of CD-FSS and uncover two crucial insights: (i) the necessity of a fine-tuning stage to effectively transfer the learned meta-knowledge across domains, and (ii) the overfitting risk during the na\"ive fine-tuning due to the scarcity of novel category examples. With these insights, we propose a novel cross-domain fine-tuning strategy that addresses the challenging CD-FSS tasks. We first design Bi-directional Few-shot Prediction (BFP), which establishes support-query correspondence in a bi-directional manner, crafting augmented supervision to reduce the overfitting risk. Then we further extend BFP into Iterative Few-shot Adaptor (IFA), which is a recursive framework to capture the support-query correspondence iteratively, targeting maximal exploitation of supervisory signals from the sparse novel category samples. Extensive empirical evaluations show that our method significantly outperforms the state-of-the-arts (+7.8\%), which verifies that IFA tackles the cross-domain challenges and mitigates the overfitting simultaneously. Code will be made available.
Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4
Dec 13, 2023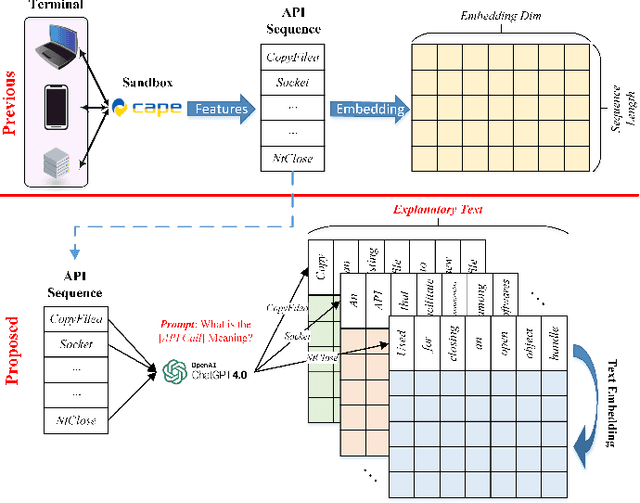
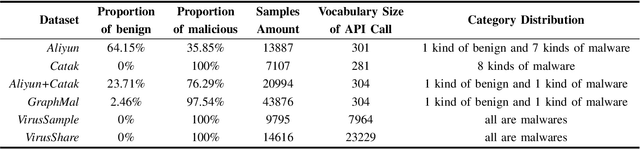
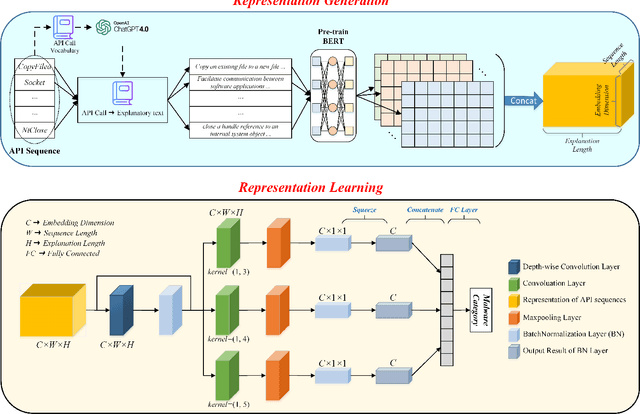
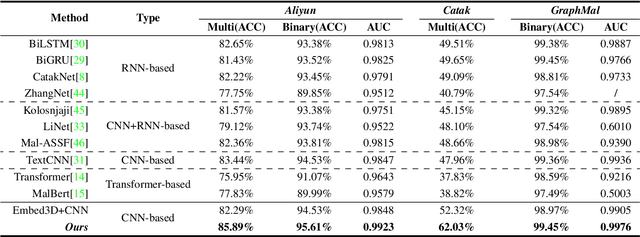
Dynamic analysis methods effectively identify shelled, wrapped, or obfuscated malware, thereby preventing them from invading computers. As a significant representation of dynamic malware behavior, the API (Application Programming Interface) sequence, comprised of consecutive API calls, has progressively become the dominant feature of dynamic analysis methods. Though there have been numerous deep learning models for malware detection based on API sequences, the quality of API call representations produced by those models is limited. These models cannot generate representations for unknown API calls, which weakens both the detection performance and the generalization. Further, the concept drift phenomenon of API calls is prominent. To tackle these issues, we introduce a prompt engineering-assisted malware dynamic analysis using GPT-4. In this method, GPT-4 is employed to create explanatory text for each API call within the API sequence. Afterward, the pre-trained language model BERT is used to obtain the representation of the text, from which we derive the representation of the API sequence. Theoretically, this proposed method is capable of generating representations for all API calls, excluding the necessity for dataset training during the generation process. Utilizing the representation, a CNN-based detection model is designed to extract the feature. We adopt five benchmark datasets to validate the performance of the proposed model. The experimental results reveal that the proposed detection algorithm performs better than the state-of-the-art method (TextCNN). Specifically, in cross-database experiments and few-shot learning experiments, the proposed model achieves excellent detection performance and almost a 100% recall rate for malware, verifying its superior generalization performance. The code is available at: github.com/yan-scnu/Prompted_Dynamic_Detection.
Unsupervised convolutional neural network fusion approach for change detection in remote sensing images
Nov 07, 2023



With the rapid development of deep learning, a variety of change detection methods based on deep learning have emerged in recent years. However, these methods usually require a large number of training samples to train the network model, so it is very expensive. In this paper, we introduce a completely unsupervised shallow convolutional neural network (USCNN) fusion approach for change detection. Firstly, the bi-temporal images are transformed into different feature spaces by using convolution kernels of different sizes to extract multi-scale information of the images. Secondly, the output features of bi-temporal images at the same convolution kernels are subtracted to obtain the corresponding difference images, and the difference feature images at the same scale are fused into one feature image by using 1 * 1 convolution layer. Finally, the output features of different scales are concatenated and a 1 * 1 convolution layer is used to fuse the multi-scale information of the image. The model parameters are obtained by a redesigned sparse function. Our model has three features: the entire training process is conducted in an unsupervised manner, the network architecture is shallow, and the objective function is sparse. Thus, it can be seen as a kind of lightweight network model. Experimental results on four real remote sensing datasets indicate the feasibility and effectiveness of the proposed approach.
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity
Jul 11, 2021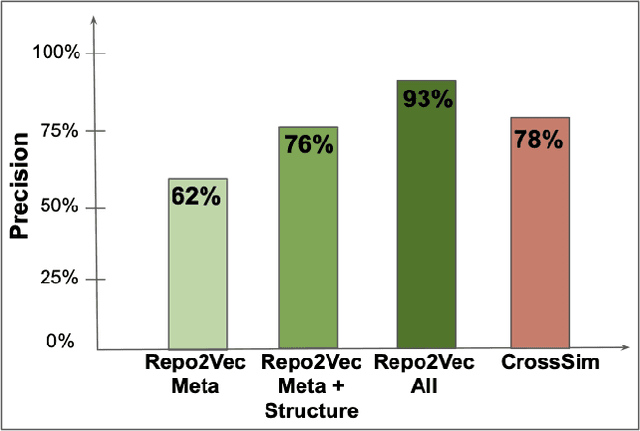
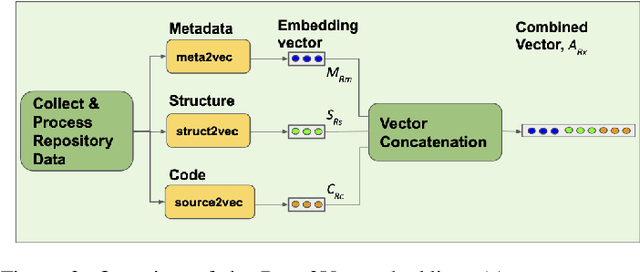
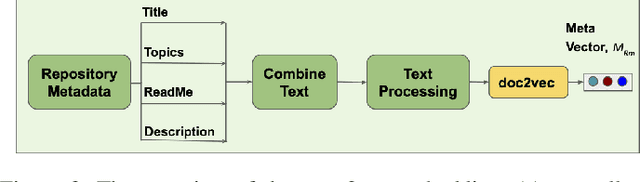
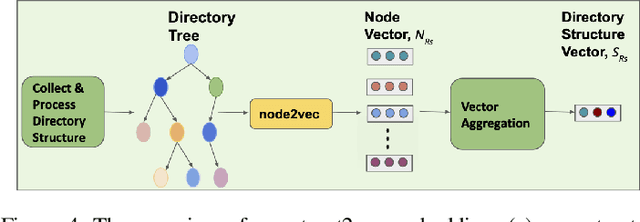
How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determiningrepository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by MLalgorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a)metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93%vs 78%), with nearly twice as many Strongly Similar repositories and 30% fewer False Positives. Second, we show how Repo2Vecprovides a solid basis for: (a) distinguishing between malware and benign repositories, and (b) identifying a meaningful hierarchical clustering. For example, we achieve 98% precision and 96%recall in distinguishing malware and benign repositories. Overall, our work is a fundamental building block for enabling many repository analysis functions such as repository categorization by target platform or intention, detecting code-reuse and clones, and identifying lineage and evolution.
Unsupervised Learning Framework of Interest Point Via Properties Optimization
Jul 26, 2019



This paper presents an entirely unsupervised interest point training framework by jointly learning detector and descriptor, which takes an image as input and outputs a probability and a description for every image point. The objective of the training framework is formulated as joint probability distribution of the properties of the extracted points. The essential properties are selected as sparsity, repeatability and discriminability which are formulated by the probabilities. To maximize the objective efficiently, latent variable is introduced to represent the probability of that a point satisfies the required properties. Therefore, original maximization can be optimized with Expectation Maximization algorithm (EM). Considering high computation cost of EM on large scale image set, we implement the optimization process with an efficient strategy as Mini-Batch approximation of EM (MBEM). In the experiments both detector and descriptor are instantiated with fully convolutional network which is named as Property Network (PN). The experiments demonstrate that PN outperforms state-of-the-art methods on a number of image matching benchmarks without need of retraining. PN also reveals that the proposed training framework has high flexibility to adapt to diverse types of scenes.