 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE.M.Ground: A Temporal Grounding Vid-LLM with Holistic Event Perception and Matching
Feb 05, 2026Despite recent advances in Video Large Language Models (Vid-LLMs), Temporal Video Grounding (TVG), which aims to precisely localize time segments corresponding to query events, remains a significant challenge. Existing methods often match start and end frames by comparing frame features with two separate tokens, relying heavily on exact timestamps. However, this approach fails to capture the event's semantic continuity and integrity, leading to ambiguities. To address this, we propose E.M.Ground, a novel Vid-LLM for TVG that focuses on holistic and coherent event perception. E.M.Ground introduces three key innovations: (i) a special <event> token that aggregates information from all frames of a query event, preserving semantic continuity for accurate event matching; (ii) Savitzky-Golay smoothing to reduce noise in token-to-frame similarities across timestamps, improving prediction accuracy; (iii) multi-grained frame feature aggregation to enhance matching reliability and temporal understanding, compensating for compression-induced information loss. Extensive experiments on benchmark datasets show that E.M.Ground consistently outperforms state-of-the-art Vid-LLMs by significant margins.
RoboSVG: A Unified Framework for Interactive SVG Generation with Multi-modal Guidance
Oct 26, 2025Scalable Vector Graphics (SVGs) are fundamental to digital design and robot control, encoding not only visual structure but also motion paths in interactive drawings. In this work, we introduce RoboSVG, a unified multimodal framework for generating interactive SVGs guided by textual, visual, and numerical signals. Given an input query, the RoboSVG model first produces multimodal guidance, then synthesizes candidate SVGs through dedicated generation modules, and finally refines them under numerical guidance to yield high-quality outputs. To support this framework, we construct RoboDraw, a large-scale dataset of one million examples, each pairing an SVG generation condition (e.g., text, image, and partial SVG) with its corresponding ground-truth SVG code. RoboDraw dataset enables systematic study of four tasks, including basic generation (Text-to-SVG, Image-to-SVG) and interactive generation (PartialSVG-to-SVG, PartialImage-to-SVG). Extensive experiments demonstrate that RoboSVG achieves superior query compliance and visual fidelity across tasks, establishing a new state of the art in versatile SVG generation. The dataset and source code of this project will be publicly available soon.
GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
Sep 19, 2025Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.
MMRel: A Relation Understanding Dataset and Benchmark in the MLLM Era
Jun 13, 2024



Despite the recent advancements in Multi-modal Large Language Models (MLLMs), understanding inter-object relations, i.e., interactions or associations between distinct objects, remains a major challenge for such models. This issue significantly hinders their advanced reasoning capabilities and is primarily due to the lack of large-scale, high-quality, and diverse multi-modal data essential for training and evaluating MLLMs. In this paper, we provide a taxonomy of inter-object relations and introduce Multi-Modal Relation Understanding (MMRel), a comprehensive dataset designed to bridge this gap by providing large-scale, high-quality and diverse data for studying inter-object relations with MLLMs. MMRel features three distinctive attributes: (i) It includes over 15K question-answer pairs, which are sourced from three distinct domains, ensuring large scale and high diversity; (ii) It contains a subset featuring highly unusual relations, on which MLLMs often fail due to hallucinations, thus are very challenging; (iii) It provides manually verified high-quality labels for inter-object relations. Thanks to these features, MMRel is ideal for evaluating MLLMs on relation understanding, as well as being used to fine-tune MLLMs to enhance relation understanding and even benefit overall performance in various vision-language tasks. Extensive experiments on various popular MLLMs validate the effectiveness of MMRel. Both MMRel dataset and the complete labeling scripts have been made publicly available.
Cross-Domain Few-Shot Segmentation via Iterative Support-Query Correspondence Mining
Jan 16, 2024



Cross-Domain Few-Shot Segmentation (CD-FSS) poses the challenge of segmenting novel categories from a distinct domain using only limited exemplars. In this paper, we undertake a comprehensive study of CD-FSS and uncover two crucial insights: (i) the necessity of a fine-tuning stage to effectively transfer the learned meta-knowledge across domains, and (ii) the overfitting risk during the na\"ive fine-tuning due to the scarcity of novel category examples. With these insights, we propose a novel cross-domain fine-tuning strategy that addresses the challenging CD-FSS tasks. We first design Bi-directional Few-shot Prediction (BFP), which establishes support-query correspondence in a bi-directional manner, crafting augmented supervision to reduce the overfitting risk. Then we further extend BFP into Iterative Few-shot Adaptor (IFA), which is a recursive framework to capture the support-query correspondence iteratively, targeting maximal exploitation of supervisory signals from the sparse novel category samples. Extensive empirical evaluations show that our method significantly outperforms the state-of-the-arts (+7.8\%), which verifies that IFA tackles the cross-domain challenges and mitigates the overfitting simultaneously. Code will be made available.
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
Jun 18, 2023



Vectorized high-definition (HD) map is essential for autonomous driving, providing detailed and precise environmental information for advanced perception and planning. However, current map vectorization methods often exhibit deviations, and the existing evaluation metric for map vectorization lacks sufficient sensitivity to detect these deviations. To address these limitations, we propose integrating the philosophy of rasterization into map vectorization. Specifically, we introduce a new rasterization-based evaluation metric, which has superior sensitivity and is better suited to real-world autonomous driving scenarios. Furthermore, we propose MapVR (Map Vectorization via Rasterization), a novel framework that applies differentiable rasterization to vectorized outputs and then performs precise and geometry-aware supervision on rasterized HD maps. Notably, MapVR designs tailored rasterization strategies for various geometric shapes, enabling effective adaptation to a wide range of map elements. Experiments show that incorporating rasterization into map vectorization greatly enhances performance with no extra computational cost during inference, leading to more accurate map perception and ultimately promoting safer autonomous driving.
Modeling Continuous Motion for 3D Point Cloud Object Tracking
Mar 14, 2023The task of 3D single object tracking (SOT) with LiDAR point clouds is crucial for various applications, such as autonomous driving and robotics. However, existing approaches have primarily relied on appearance matching or motion modeling within only two successive frames, thereby overlooking the long-range continuous motion property of objects in 3D space. To address this issue, this paper presents a novel approach that views each tracklet as a continuous stream: at each timestamp, only the current frame is fed into the network to interact with multi-frame historical features stored in a memory bank, enabling efficient exploitation of sequential information. To achieve effective cross-frame message passing, a hybrid attention mechanism is designed to account for both long-range relation modeling and local geometric feature extraction. Furthermore, to enhance the utilization of multi-frame features for robust tracking, a contrastive sequence enhancement strategy is designed, which uses ground truth tracklets to augment training sequences and promote discrimination against false positives in a contrastive manner. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art method by significant margins (approximately 8%, 6%, and 12% improvements in the success performance on KITTI, nuScenes, and Waymo, respectively).
DETR4D: Direct Multi-View 3D Object Detection with Sparse Attention
Dec 15, 20223D object detection with surround-view images is an essential task for autonomous driving. In this work, we propose DETR4D, a Transformer-based framework that explores sparse attention and direct feature query for 3D object detection in multi-view images. We design a novel projective cross-attention mechanism for query-image interaction to address the limitations of existing methods in terms of geometric cue exploitation and information loss for cross-view objects. In addition, we introduce a heatmap generation technique that bridges 3D and 2D spaces efficiently via query initialization. Furthermore, unlike the common practice of fusing intermediate spatial features for temporal aggregation, we provide a new perspective by introducing a novel hybrid approach that performs cross-frame fusion over past object queries and image features, enabling efficient and robust modeling of temporal information. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of the proposed DETR4D.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Aug 24, 2022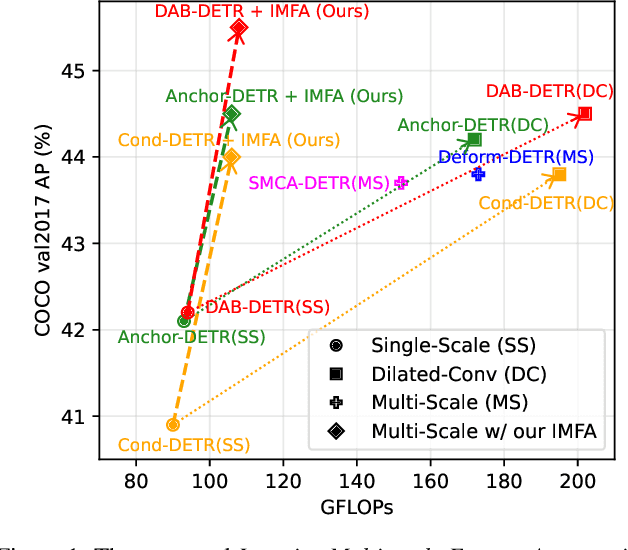
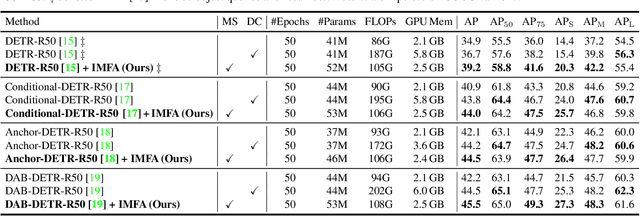
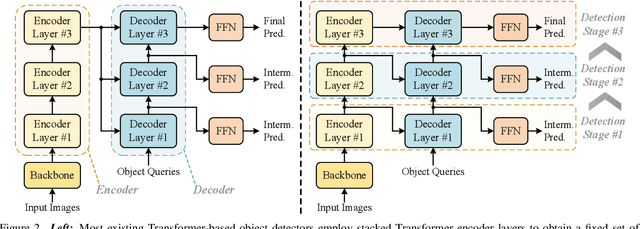
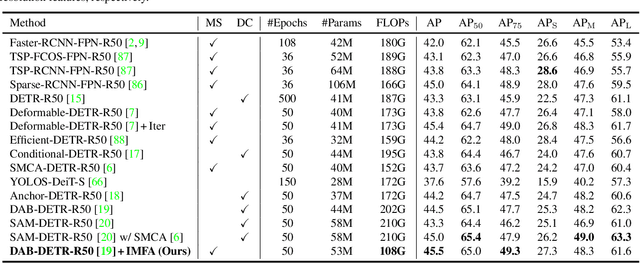
Multi-scale features have been proven highly effective for object detection, and most ConvNet-based object detectors adopt Feature Pyramid Network (FPN) as a basic component for exploiting multi-scale features. However, for the recently proposed Transformer-based object detectors, directly incorporating multi-scale features leads to prohibitive computational overhead due to the high complexity of the attention mechanism for processing high-resolution features. This paper presents Iterative Multi-scale Feature Aggregation (IMFA) -- a generic paradigm that enables the efficient use of multi-scale features in Transformer-based object detectors. The core idea is to exploit sparse multi-scale features from just a few crucial locations, and it is achieved with two novel designs. First, IMFA rearranges the Transformer encoder-decoder pipeline so that the encoded features can be iteratively updated based on the detection predictions. Second, IMFA sparsely samples scale-adaptive features for refined detection from just a few keypoint locations under the guidance of prior detection predictions. As a result, the sampled multi-scale features are sparse yet still highly beneficial for object detection. Extensive experiments show that the proposed IMFA boosts the performance of multiple Transformer-based object detectors significantly yet with slight computational overhead. Project page: https://github.com/ZhangGongjie/IMFA.
Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022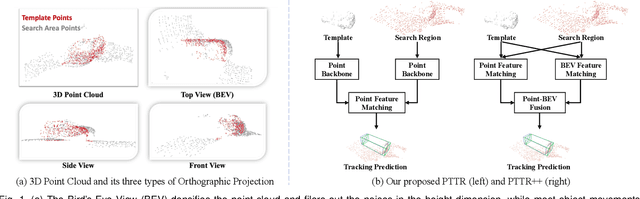
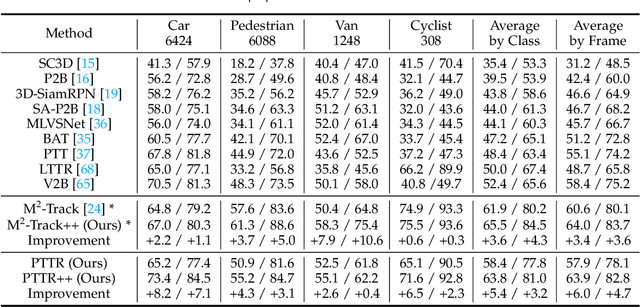
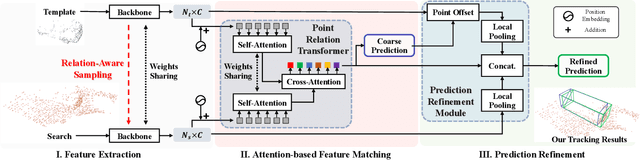
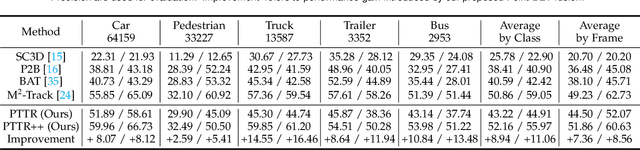
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.