 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Transformer: Towards High Fidelity and Accurate Face Swapping
Apr 05, 2023Face swapping aims to generate swapped images that fuse the identity of source faces and the attributes of target faces. Most existing works address this challenging task through 3D modelling or generation using generative adversarial networks (GANs), but 3D modelling suffers from limited reconstruction accuracy and GANs often struggle in preserving subtle yet important identity details of source faces (e.g., skin colors, face features) and structural attributes of target faces (e.g., face shapes, facial expressions). This paper presents Face Transformer, a novel face swapping network that can accurately preserve source identities and target attributes simultaneously in the swapped face images. We introduce a transformer network for the face swapping task, which learns high-quality semantic-aware correspondence between source and target faces and maps identity features of source faces to the corresponding region in target faces. The high-quality semantic-aware correspondence enables smooth and accurate transfer of source identity information with minimal modification of target shapes and expressions. In addition, our Face Transformer incorporates a multi-scale transformation mechanism for preserving the rich fine facial details. Extensive experiments show that our Face Transformer achieves superior face swapping performance qualitatively and quantitatively.
KD-DLGAN: Data Limited Image Generation via Knowledge Distillation
Mar 30, 2023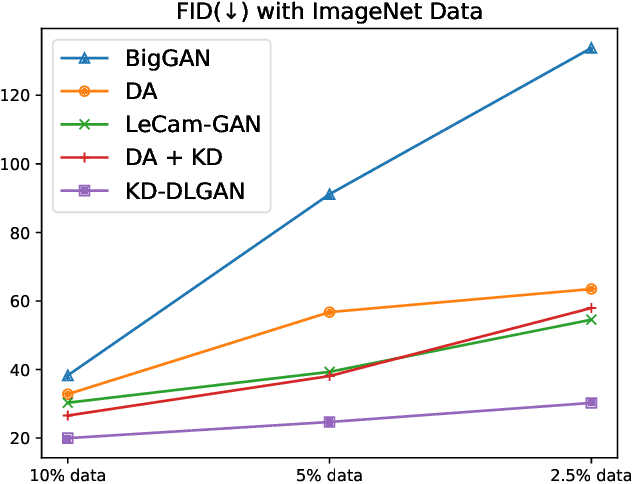
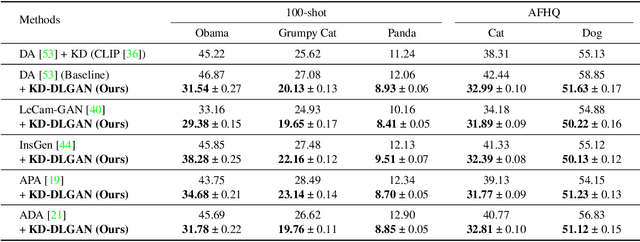
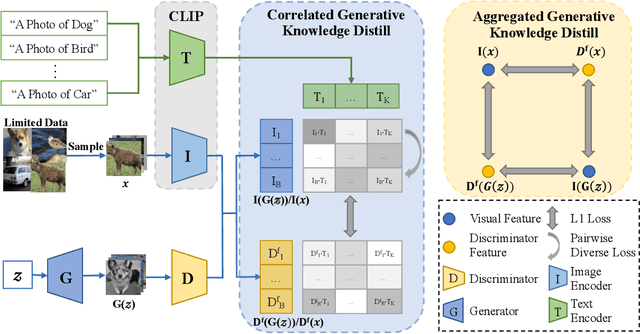
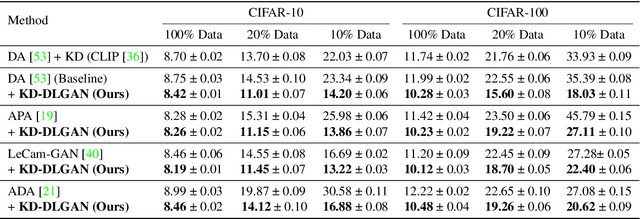
Generative Adversarial Networks (GANs) rely heavily on large-scale training data for training high-quality image generation models. With limited training data, the GAN discriminator often suffers from severe overfitting which directly leads to degraded generation especially in generation diversity. Inspired by the recent advances in knowledge distillation (KD), we propose KD-DLGAN, a knowledge-distillation based generation framework that introduces pre-trained vision-language models for training effective data-limited generation models. KD-DLGAN consists of two innovative designs. The first is aggregated generative KD that mitigates the discriminator overfitting by challenging the discriminator with harder learning tasks and distilling more generalizable knowledge from the pre-trained models. The second is correlated generative KD that improves the generation diversity by distilling and preserving the diverse image-text correlation within the pre-trained models. Extensive experiments over multiple benchmarks show that KD-DLGAN achieves superior image generation with limited training data. In addition, KD-DLGAN complements the state-of-the-art with consistent and substantial performance gains.
PolarMix: A General Data Augmentation Technique for LiDAR Point Clouds
Jul 30, 2022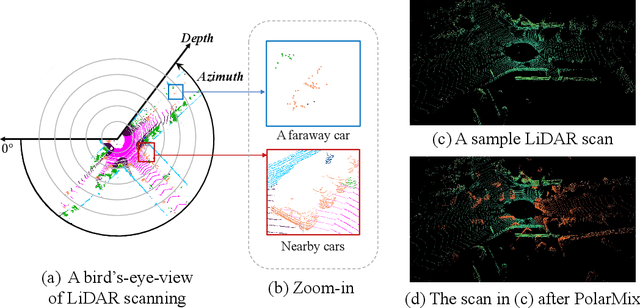
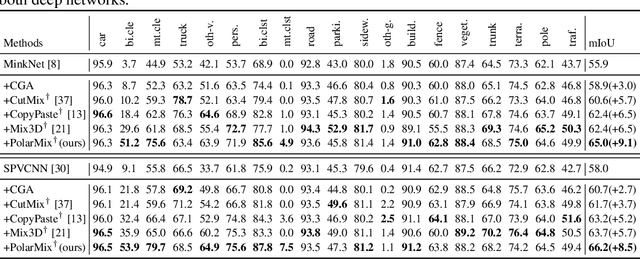
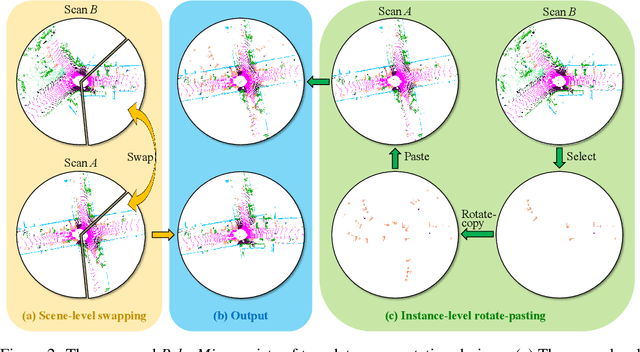

LiDAR point clouds, which are usually scanned by rotating LiDAR sensors continuously, capture precise geometry of the surrounding environment and are crucial to many autonomous detection and navigation tasks. Though many 3D deep architectures have been developed, efficient collection and annotation of large amounts of point clouds remain one major challenge in the analytic and understanding of point cloud data. This paper presents PolarMix, a point cloud augmentation technique that is simple and generic but can mitigate the data constraint effectively across different perception tasks and scenarios. PolarMix enriches point cloud distributions and preserves point cloud fidelity via two cross-scan augmentation strategies that cut, edit, and mix point clouds along the scanning direction. The first is scene-level swapping which exchanges point cloud sectors of two LiDAR scans that are cut along the azimuth axis. The second is instance-level rotation and paste which crops point instances from one LiDAR scan, rotates them by multiple angles (to create multiple copies), and paste the rotated point instances into other scans. Extensive experiments show that PolarMix achieves superior performance consistently across different perception tasks and scenarios. In addition, it can work as plug-and-play for various 3D deep architectures and also performs well for unsupervised domain adaptation.
Meta-DETR: Image-Level Few-Shot Detection with Inter-Class Correlation Exploitation
Jul 30, 2022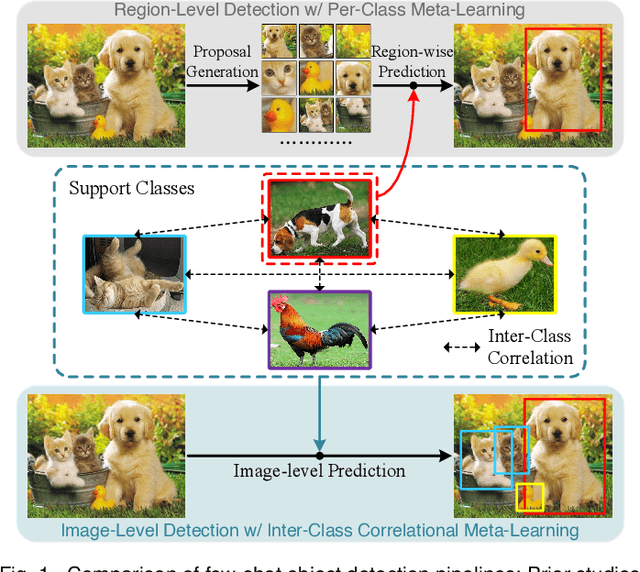

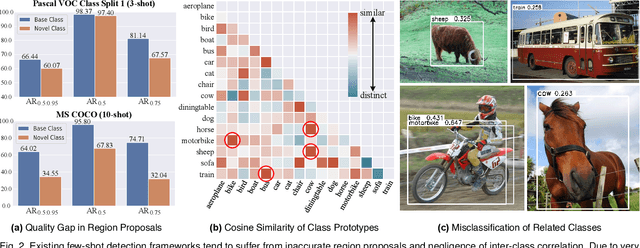
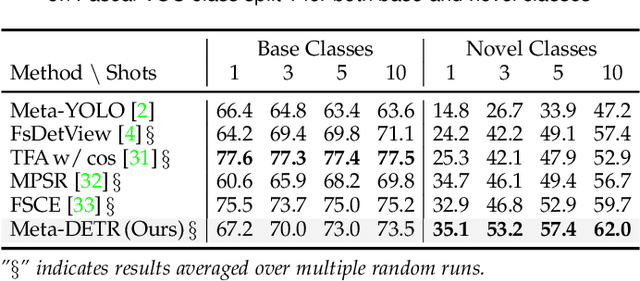
Few-shot object detection has been extensively investigated by incorporating meta-learning into region-based detection frameworks. Despite its success, the said paradigm is still constrained by several factors, such as (i) low-quality region proposals for novel classes and (ii) negligence of the inter-class correlation among different classes. Such limitations hinder the generalization of base-class knowledge for the detection of novel-class objects. In this work, we design Meta-DETR, which (i) is the first image-level few-shot detector, and (ii) introduces a novel inter-class correlational meta-learning strategy to capture and leverage the correlation among different classes for robust and accurate few-shot object detection. Meta-DETR works entirely at image level without any region proposals, which circumvents the constraint of inaccurate proposals in prevalent few-shot detection frameworks. In addition, the introduced correlational meta-learning enables Meta-DETR to simultaneously attend to multiple support classes within a single feedforward, which allows to capture the inter-class correlation among different classes, thus significantly reducing the misclassification over similar classes and enhancing knowledge generalization to novel classes. Experiments over multiple few-shot object detection benchmarks show that the proposed Meta-DETR outperforms state-of-the-art methods by large margins. The implementation codes are available at https://github.com/ZhangGongjie/Meta-DETR.
Semantic-Aligned Matching for Enhanced DETR Convergence and Multi-Scale Feature Fusion
Jul 28, 2022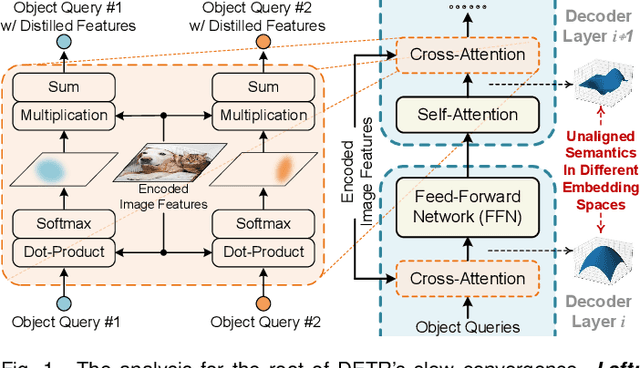
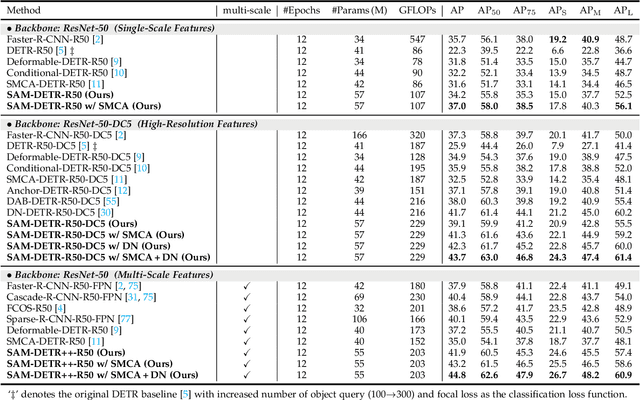

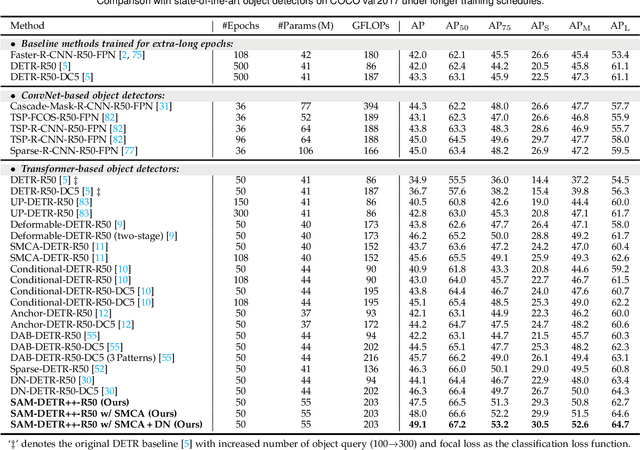
The recently proposed DEtection TRansformer (DETR) has established a fully end-to-end paradigm for object detection. However, DETR suffers from slow training convergence, which hinders its applicability to various detection tasks. We observe that DETR's slow convergence is largely attributed to the difficulty in matching object queries to relevant regions due to the unaligned semantics between object queries and encoded image features. With this observation, we design Semantic-Aligned-Matching DETR++ (SAM-DETR++) to accelerate DETR's convergence and improve detection performance. The core of SAM-DETR++ is a plug-and-play module that projects object queries and encoded image features into the same feature embedding space, where each object query can be easily matched to relevant regions with similar semantics. Besides, SAM-DETR++ searches for multiple representative keypoints and exploits their features for semantic-aligned matching with enhanced representation capacity. Furthermore, SAM-DETR++ can effectively fuse multi-scale features in a coarse-to-fine manner on the basis of the designed semantic-aligned matching. Extensive experiments show that the proposed SAM-DETR++ achieves superior convergence speed and competitive detection accuracy. Additionally, as a plug-and-play method, SAM-DETR++ can complement existing DETR convergence solutions with even better performance, achieving 44.8% AP with merely 12 training epochs and 49.1% AP with 50 training epochs on COCO val2017 with ResNet-50. Codes are available at https://github.com/ZhangGongjie/SAM-DETR .
Auto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022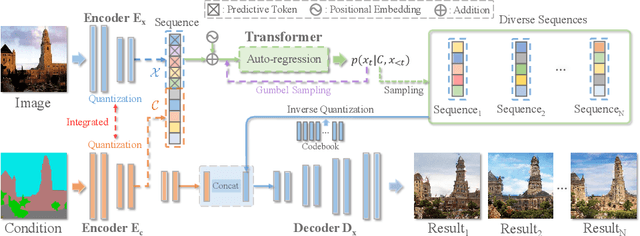

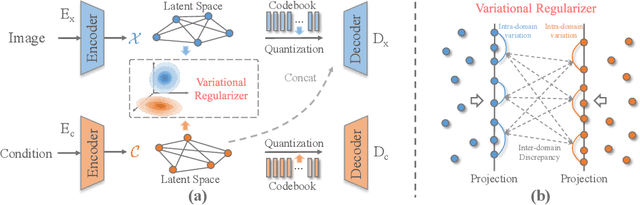

Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
Accelerating DETR Convergence via Semantic-Aligned Matching
Mar 14, 2022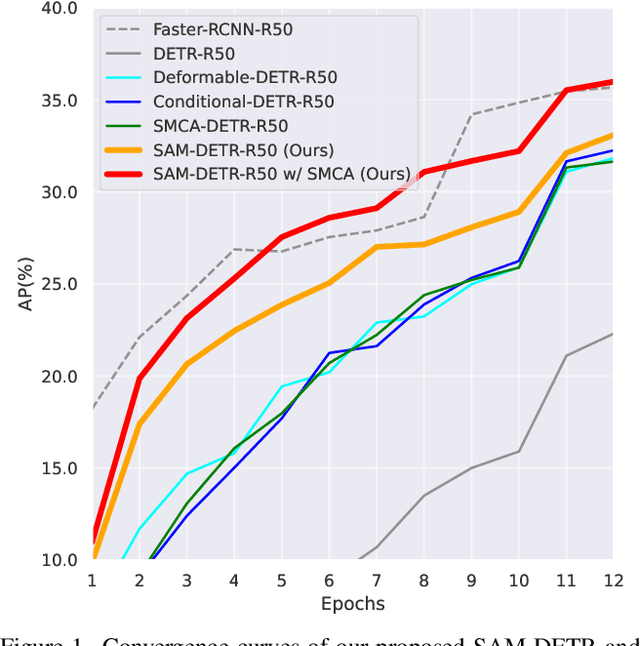
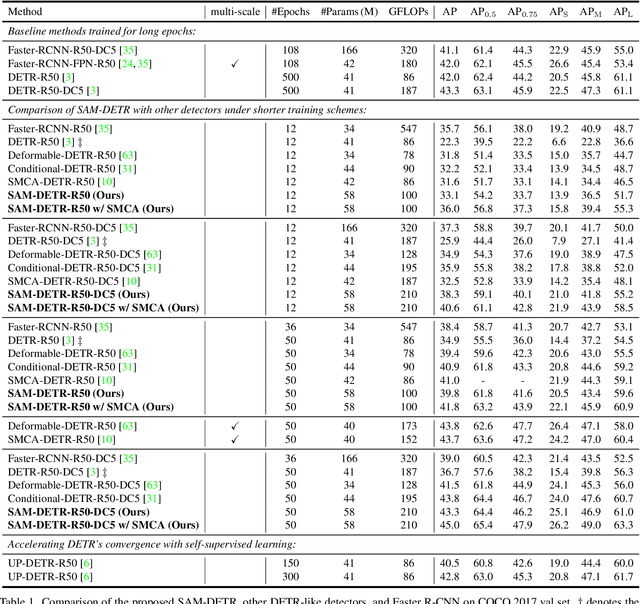
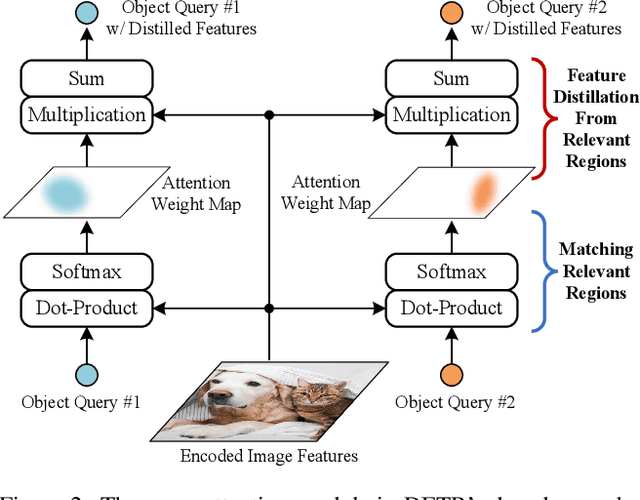
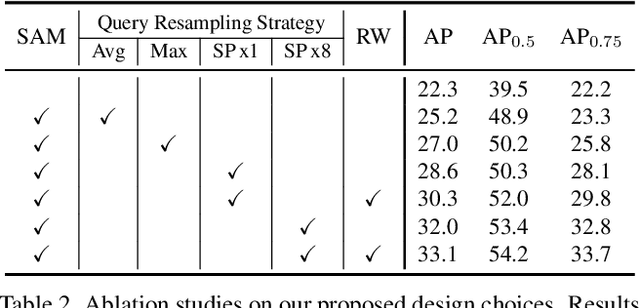
The recently developed DEtection TRansformer (DETR) establishes a new object detection paradigm by eliminating a series of hand-crafted components. However, DETR suffers from extremely slow convergence, which increases the training cost significantly. We observe that the slow convergence is largely attributed to the complication in matching object queries with target features in different feature embedding spaces. This paper presents SAM-DETR, a Semantic-Aligned-Matching DETR that greatly accelerates DETR's convergence without sacrificing its accuracy. SAM-DETR addresses the convergence issue from two perspectives. First, it projects object queries into the same embedding space as encoded image features, where the matching can be accomplished efficiently with aligned semantics. Second, it explicitly searches salient points with the most discriminative features for semantic-aligned matching, which further speeds up the convergence and boosts detection accuracy as well. Being like a plug and play, SAM-DETR complements existing convergence solutions well yet only introduces slight computational overhead. Extensive experiments show that the proposed SAM-DETR achieves superior convergence as well as competitive detection accuracy. The implementation codes are available at https://github.com/ZhangGongjie/SAM-DETR.
GenCo: Generative Co-training on Data-Limited Image Generation
Oct 04, 2021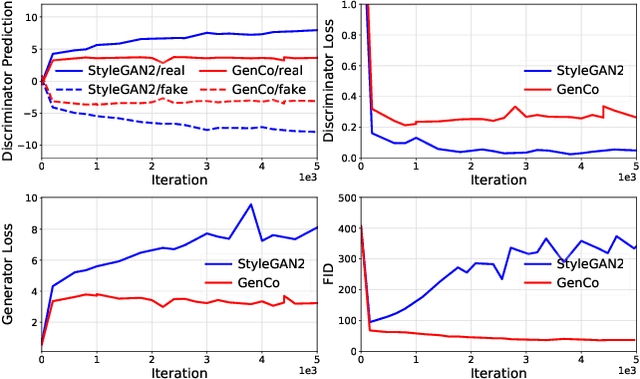

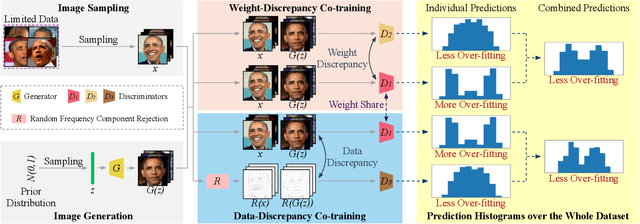
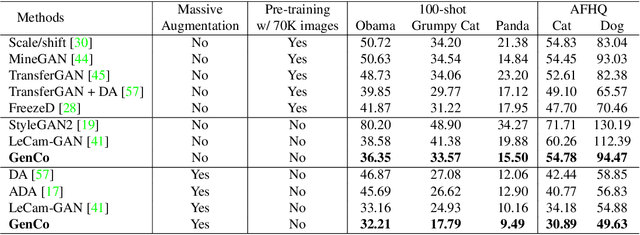
Training effective Generative Adversarial Networks (GANs) requires large amounts of training data, without which the trained models are usually sub-optimal with discriminator over-fitting. Several prior studies address this issue by expanding the distribution of the limited training data via massive and hand-crafted data augmentation. We handle data-limited image generation from a very different perspective. Specifically, we design GenCo, a Generative Co-training network that mitigates the discriminator over-fitting issue by introducing multiple complementary discriminators that provide diverse supervision from multiple distinctive views in training. We instantiate the idea of GenCo in two ways. The first way is Weight-Discrepancy Co-training (WeCo) which co-trains multiple distinctive discriminators by diversifying their parameters. The second way is Data-Discrepancy Co-training (DaCo) which achieves co-training by feeding discriminators with different views of the input images (e.g., different frequency components of the input images). Extensive experiments over multiple benchmarks show that GenCo achieves superior generation with limited training data. In addition, GenCo also complements the augmentation approach with consistent and clear performance gains when combined.
FBC-GAN: Diverse and Flexible Image Synthesis via Foreground-Background Composition
Jul 07, 2021
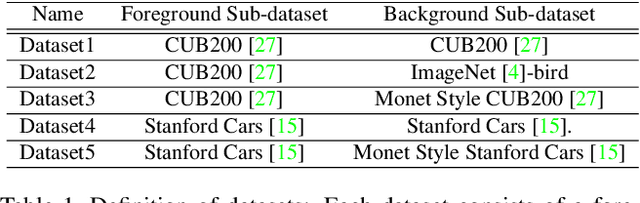


Generative Adversarial Networks (GANs) have become the de-facto standard in image synthesis. However, without considering the foreground-background decomposition, existing GANs tend to capture excessive content correlation between foreground and background, thus constraining the diversity in image generation. This paper presents a novel Foreground-Background Composition GAN (FBC-GAN) that performs image generation by generating foreground objects and background scenes concurrently and independently, followed by composing them with style and geometrical consistency. With this explicit design, FBC-GAN can generate images with foregrounds and backgrounds that are mutually independent in contents, thus lifting the undesirably learned content correlation constraint and achieving superior diversity. It also provides excellent flexibility by allowing the same foreground object with different background scenes, the same background scene with varying foreground objects, or the same foreground object and background scene with different object positions, sizes and poses. It can compose foreground objects and background scenes sampled from different datasets as well. Extensive experiments over multiple datasets show that FBC-GAN achieves competitive visual realism and superior diversity as compared with state-of-the-art methods.
Bi-level Feature Alignment for Versatile Image Translation and Manipulation
Jul 07, 2021
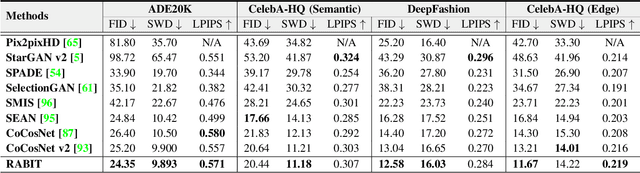
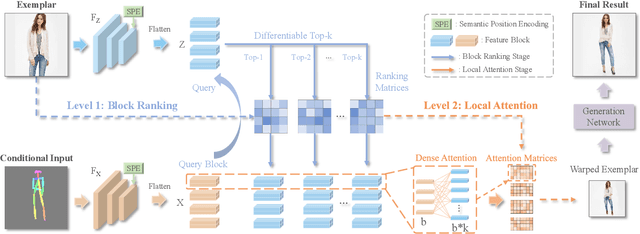

Generative adversarial networks (GANs) have achieved great success in image translation and manipulation. However, high-fidelity image generation with faithful style control remains a grand challenge in computer vision. This paper presents a versatile image translation and manipulation framework that achieves accurate semantic and style guidance in image generation by explicitly building a correspondence. To handle the quadratic complexity incurred by building the dense correspondences, we introduce a bi-level feature alignment strategy that adopts a top-$k$ operation to rank block-wise features followed by dense attention between block features which reduces memory cost substantially. As the top-$k$ operation involves index swapping which precludes the gradient propagation, we propose to approximate the non-differentiable top-$k$ operation with a regularized earth mover's problem so that its gradient can be effectively back-propagated. In addition, we design a novel semantic position encoding mechanism that builds up coordinate for each individual semantic region to preserve texture structures while building correspondences. Further, we design a novel confidence feature injection module which mitigates mismatch problem by fusing features adaptively according to the reliability of built correspondences. Extensive experiments show that our method achieves superior performance qualitatively and quantitatively as compared with the state-of-the-art. The code is available at \href{https://github.com/fnzhan/RABIT}{https://github.com/fnzhan/RABIT}.