 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-regressive Image Synthesis with Integrated Quantization
Jul 21, 2022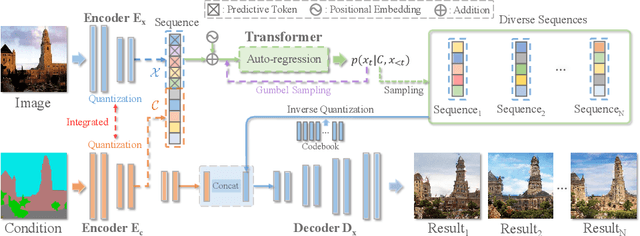

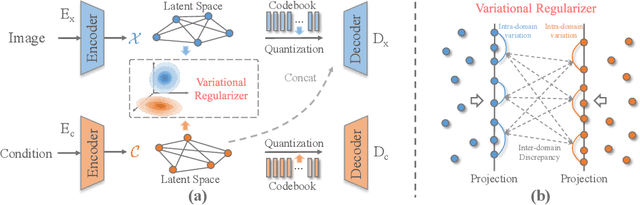

Deep generative models have achieved conspicuous progress in realistic image synthesis with multifarious conditional inputs, while generating diverse yet high-fidelity images remains a grand challenge in conditional image generation. This paper presents a versatile framework for conditional image generation which incorporates the inductive bias of CNNs and powerful sequence modeling of auto-regression that naturally leads to diverse image generation. Instead of independently quantizing the features of multiple domains as in prior research, we design an integrated quantization scheme with a variational regularizer that mingles the feature discretization in multiple domains, and markedly boosts the auto-regressive modeling performance. Notably, the variational regularizer enables to regularize feature distributions in incomparable latent spaces by penalizing the intra-domain variations of distributions. In addition, we design a Gumbel sampling strategy that allows to incorporate distribution uncertainty into the auto-regressive training procedure. The Gumbel sampling substantially mitigates the exposure bias that often incurs misalignment between the training and inference stages and severely impairs the inference performance. Extensive experiments over multiple conditional image generation tasks show that our method achieves superior diverse image generation performance qualitatively and quantitatively as compared with the state-of-the-art.
Marginal Contrastive Correspondence for Guided Image Generation
Apr 01, 2022

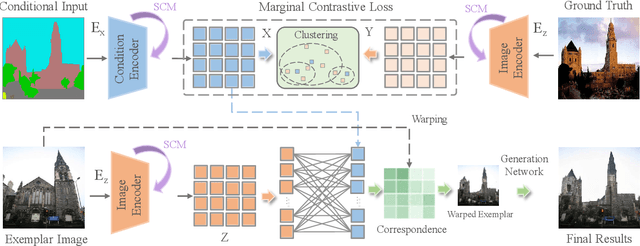

Exemplar-based image translation establishes dense correspondences between a conditional input and an exemplar (from two different domains) for leveraging detailed exemplar styles to achieve realistic image translation. Existing work builds the cross-domain correspondences implicitly by minimizing feature-wise distances across the two domains. Without explicit exploitation of domain-invariant features, this approach may not reduce the domain gap effectively which often leads to sub-optimal correspondences and image translation. We design a Marginal Contrastive Learning Network (MCL-Net) that explores contrastive learning to learn domain-invariant features for realistic exemplar-based image translation. Specifically, we design an innovative marginal contrastive loss that guides to establish dense correspondences explicitly. Nevertheless, building correspondence with domain-invariant semantics alone may impair the texture patterns and lead to degraded texture generation. We thus design a Self-Correlation Map (SCM) that incorporates scene structures as auxiliary information which improves the built correspondences substantially. Quantitative and qualitative experiments on multifarious image translation tasks show that the proposed method outperforms the state-of-the-art consistently.
Conditional Directed Graph Convolution for 3D Human Pose Estimation
Aug 04, 2021
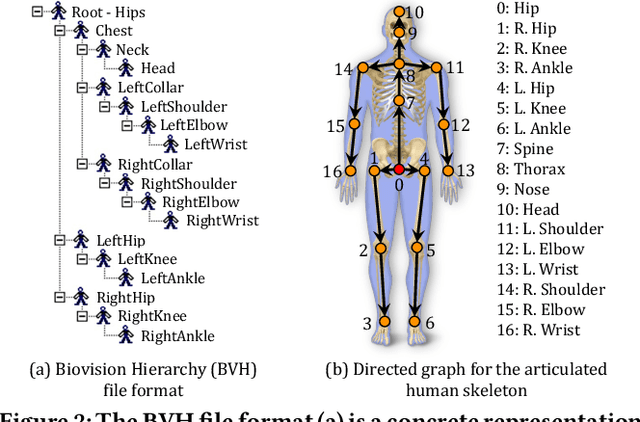
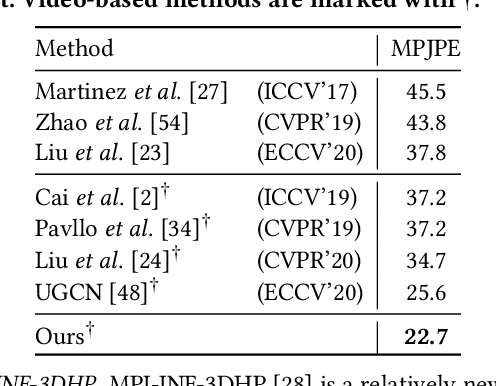

Graph convolutional networks have significantly improved 3D human pose estimation by representing the human skeleton as an undirected graph. However, this representation fails to reflect the articulated characteristic of human skeletons as the hierarchical orders among the joints are not explicitly presented. In this paper, we propose to represent the human skeleton as a directed graph with the joints as nodes and bones as edges that are directed from parent joints to child joints. By so doing, the directions of edges can explicitly reflect the hierarchical relationships among the nodes. Based on this representation, we further propose a spatial-temporal conditional directed graph convolution to leverage varying non-local dependence for different poses by conditioning the graph topology on input poses. Altogether, we form a U-shaped network, named U-shaped Conditional Directed Graph Convolutional Network, for 3D human pose estimation from monocular videos. To evaluate the effectiveness of our method, we conducted extensive experiments on two challenging large-scale benchmarks: Human3.6M and MPI-INF-3DHP. Both quantitative and qualitative results show that our method achieves top performance. Also, ablation studies show that directed graphs can better exploit the hierarchy of articulated human skeletons than undirected graphs, and the conditional connections can yield adaptive graph topologies for different poses.
Sparse Needlets for Lighting Estimation with Spherical Transport Loss
Jun 24, 2021


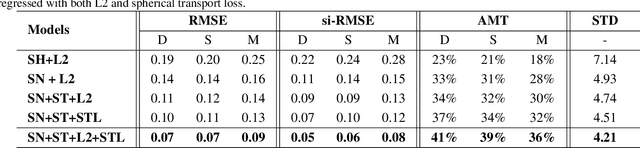
Accurate lighting estimation is challenging yet critical to many computer vision and computer graphics tasks such as high-dynamic-range (HDR) relighting. Existing approaches model lighting in either frequency domain or spatial domain which is insufficient to represent the complex lighting conditions in scenes and tends to produce inaccurate estimation. This paper presents NeedleLight, a new lighting estimation model that represents illumination with needlets and allows lighting estimation in both frequency domain and spatial domain jointly. An optimal thresholding function is designed to achieve sparse needlets which trims redundant lighting parameters and demonstrates superior localization properties for illumination representation. In addition, a novel spherical transport loss is designed based on optimal transport theory which guides to regress lighting representation parameters with consideration of the spatial information. Furthermore, we propose a new metric that is concise yet effective by directly evaluating the estimated illumination maps rather than rendered images. Extensive experiments show that NeedleLight achieves superior lighting estimation consistently across multiple evaluation metrics as compared with state-of-the-art methods.
Unbalanced Feature Transport for Exemplar-based Image Translation
Jun 19, 2021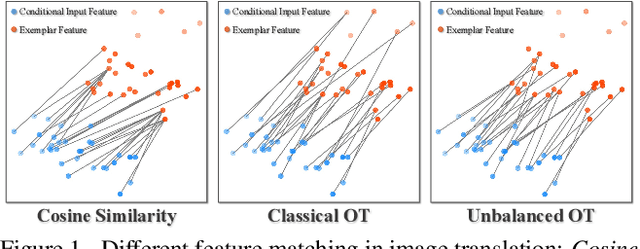
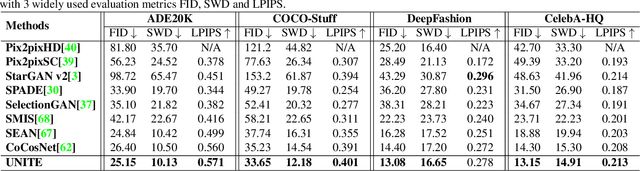
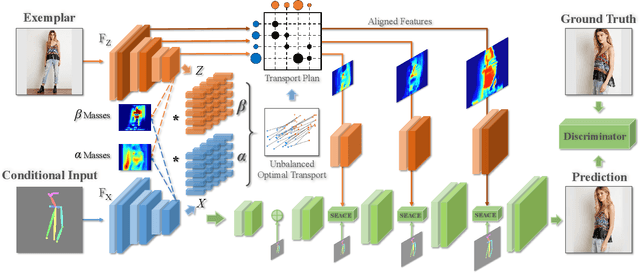
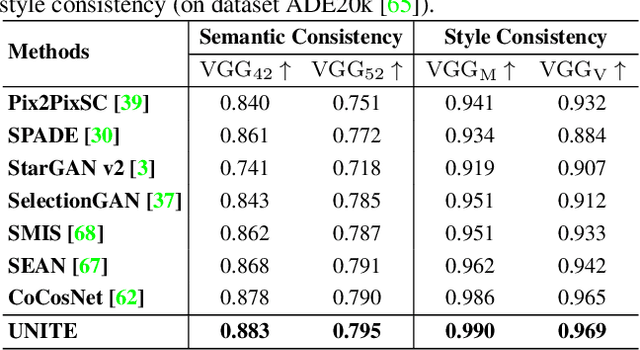
Despite the great success of GANs in images translation with different conditioned inputs such as semantic segmentation and edge maps, generating high-fidelity realistic images with reference styles remains a grand challenge in conditional image-to-image translation. This paper presents a general image translation framework that incorporates optimal transport for feature alignment between conditional inputs and style exemplars in image translation. The introduction of optimal transport mitigates the constraint of many-to-one feature matching significantly while building up accurate semantic correspondences between conditional inputs and exemplars. We design a novel unbalanced optimal transport to address the transport between features with deviational distributions which exists widely between conditional inputs and exemplars. In addition, we design a semantic-activation normalization scheme that injects style features of exemplars into the image translation process successfully. Extensive experiments over multiple image translation tasks show that our method achieves superior image translation qualitatively and quantitatively as compared with the state-of-the-art.
Deep Monocular 3D Human Pose Estimation via Cascaded Dimension-Lifting
Apr 08, 2021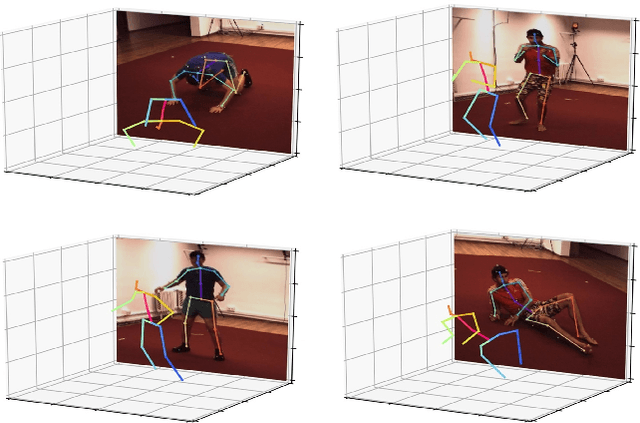
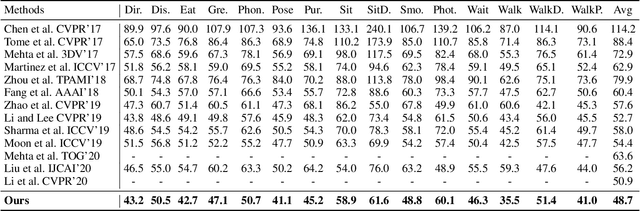


The 3D pose estimation from a single image is a challenging problem due to depth ambiguity. One type of the previous methods lifts 2D joints, obtained by resorting to external 2D pose detectors, to the 3D space. However, this type of approaches discards the contextual information of images which are strong cues for 3D pose estimation. Meanwhile, some other methods predict the joints directly from monocular images but adopt a 2.5D output representation $P^{2.5D} = (u,v,z^{r}) $ where both $u$ and $v$ are in the image space but $z^{r}$ in root-relative 3D space. Thus, the ground-truth information (e.g., the depth of root joint from the camera) is normally utilized to transform the 2.5D output to the 3D space, which limits the applicability in practice. In this work, we propose a novel end-to-end framework that not only exploits the contextual information but also produces the output directly in the 3D space via cascaded dimension-lifting. Specifically, we decompose the task of lifting pose from 2D image space to 3D spatial space into several sequential sub-tasks, 1) kinematic skeletons \& individual joints estimation in 2D space, 2) root-relative depth estimation, and 3) lifting to the 3D space, each of which employs direct supervisions and contextual image features to guide the learning process. Extensive experiments show that the proposed framework achieves state-of-the-art performance on two widely used 3D human pose datasets (Human3.6M, MuPoTS-3D).
GMLight: Lighting Estimation via Geometric Distribution Approximation
Feb 20, 2021



Lighting estimation from a single image is an essential yet challenging task in computer vision and computer graphics. Existing works estimate lighting by regressing representative illumination parameters or generating illumination maps directly. However, these methods often suffer from poor accuracy and generalization. This paper presents Geometric Mover's Light (GMLight), a lighting estimation framework that employs a regression network and a generative projector for effective illumination estimation. We parameterize illumination scenes in terms of the geometric light distribution, light intensity, ambient term, and auxiliary depth, and estimate them as a pure regression task. Inspired by the earth mover's distance, we design a novel geometric mover's loss to guide the accurate regression of light distribution parameters. With the estimated lighting parameters, the generative projector synthesizes panoramic illumination maps with realistic appearance and frequency. Extensive experiments show that GMLight achieves accurate illumination estimation and superior fidelity in relighting for 3D object insertion.
EMLight: Lighting Estimation via Spherical Distribution Approximation
Dec 21, 2020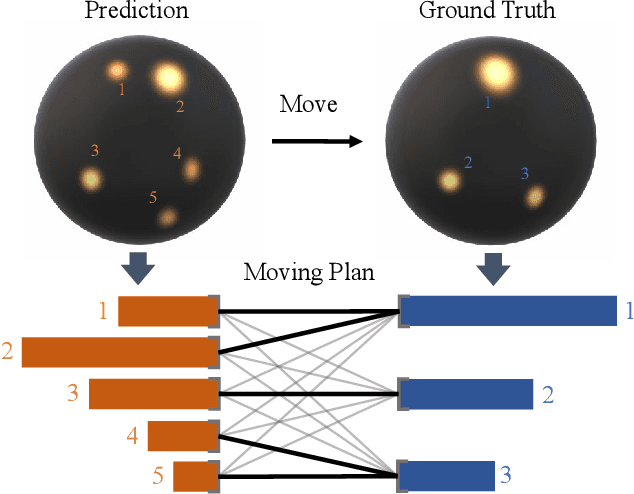


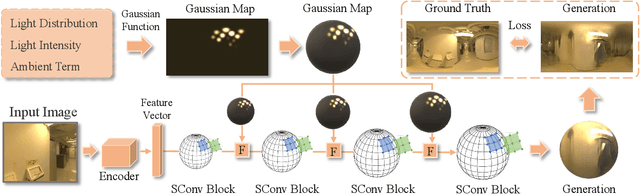
Illumination estimation from a single image is critical in 3D rendering and it has been investigated extensively in the computer vision and computer graphic research community. On the other hand, existing works estimate illumination by either regressing light parameters or generating illumination maps that are often hard to optimize or tend to produce inaccurate predictions. We propose Earth Mover Light (EMLight), an illumination estimation framework that leverages a regression network and a neural projector for accurate illumination estimation. We decompose the illumination map into spherical light distribution, light intensity and the ambient term, and define the illumination estimation as a parameter regression task for the three illumination components. Motivated by the Earth Mover distance, we design a novel spherical mover's loss that guides to regress light distribution parameters accurately by taking advantage of the subtleties of spherical distribution. Under the guidance of the predicted spherical distribution, light intensity and ambient term, the neural projector synthesizes panoramic illumination maps with realistic light frequency. Extensive experiments show that EMLight achieves accurate illumination estimation and the generated relighting in 3D object embedding exhibits superior plausibility and fidelity as compared with state-of-the-art methods.
Adversarial Image Composition with Auxiliary Illumination
Sep 17, 2020


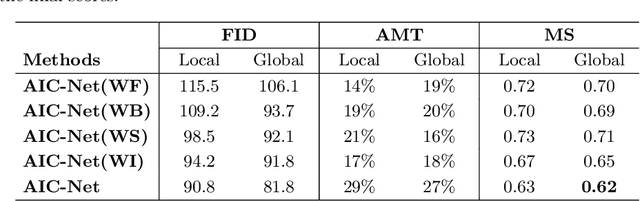
Dealing with the inconsistency between a foreground object and a background image is a challenging task in high-fidelity image composition. State-of-the-art methods strive to harmonize the composed image by adapting the style of foreground objects to be compatible with the background image, whereas the potential shadow of foreground objects within the composed image which is critical to the composition realism is largely neglected. In this paper, we propose an Adversarial Image Composition Net (AIC-Net) that achieves realistic image composition by considering potential shadows that the foreground object projects in the composed image. A novel branched generation mechanism is proposed, which disentangles the generation of shadows and the transfer of foreground styles for optimal accomplishment of the two tasks simultaneously. A differentiable spatial transformation module is designed which bridges the local harmonization and the global harmonization to achieve their joint optimization effectively. Extensive experiments on pedestrian and car composition tasks show that the proposed AIC-Net achieves superior composition performance qualitatively and quantitatively.
Towards Realistic 3D Embedding via View Alignment
Jul 14, 2020

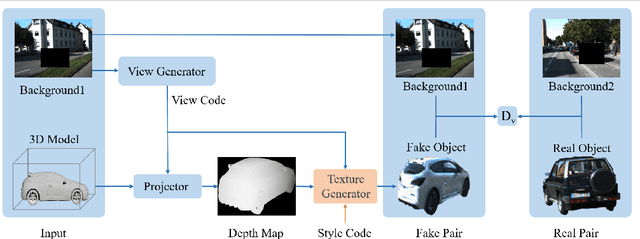

Recent advances in generative adversarial networks (GANs) have achieved great success in automated image composition that generates new images by embedding interested foreground objects into background images automatically. On the other hand, most existing works deal with foreground objects in two-dimensional (2D) images though foreground objects in three-dimensional (3D) models are more flexible with 360-degree view freedom. This paper presents an innovative View Alignment GAN (VA-GAN) that composes new images by embedding 3D models into 2D background images realistically and automatically. VA-GAN consists of a texture generator and a differential discriminator that are inter-connected and end-to-end trainable. The differential discriminator guides to learn geometric transformation from background images so that the composed 3D models can be aligned with the background images with realistic poses and views. The texture generator adopts a novel view encoding mechanism for generating accurate object textures for the 3D models under the estimated views. Extensive experiments over two synthesis tasks (car synthesis with KITTI and pedestrian synthesis with Cityscapes) show that VA-GAN achieves high-fidelity composition qualitatively and quantitatively as compared with state-of-the-art generation methods.