 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniShotCut: Holistic Relational Shot Boundary Detection with Shot-Query Transformer
Apr 27, 2026Shot Boundary Detection (SBD) aims to automatically identify shot changes and divide a video into coherent shots. While SBD was widely studied in the literature, existing state-of-the-art methods often produce non-interpretable boundaries on transitions, miss subtle yet harmful discontinuities, and rely on noisy, low-diversity annotations and outdated benchmarks. To alleviate these limitations, we propose OmniShotCut to formulate SBD as structured relational prediction, jointly estimating shot ranges with intra-shot relations and inter-shot relations, by a shot query-based dense video Transformer. To avoid imprecise manual labeling, we adopt a fully synthetic transition synthesis pipeline that automatically reproduces major transition families with precise boundaries and parameterized variants. We also introduce OmniShotCutBench, a modern wide-domain benchmark enabling holistic and diagnostic evaluation.
PepBenchmark: A Standardized Benchmark for Peptide Machine Learning
Apr 12, 2026Peptide therapeutics are widely regarded as the "third generation" of drugs, yet progress in peptide Machine Learning (ML) are hindered by the absence of standardized benchmarks. Here we present PepBenchmark, which unifies datasets, preprocessing, and evaluation protocols for peptide drug discovery. PepBenchmark comprises three components: (1) PepBenchData, a well-curated collection comprising 29 canonical-peptide and 6 non-canonical-peptide datasets across 7 groups, systematically covering key aspects of peptide drug development, representing, to the best of our knowledge, the most comprehensive AI-ready dataset resource to date; (2) PepBenchPipeline, a standardized preprocessing pipeline that ensures consistent dataset cleaning, construction, splitting, and feature transformation, mitigating quality issues common in ad hoc pipelines; and (3) PepBenchLeaderboard, a unified evaluation protocol and leaderboard with strong baselines across 4 major methodological families: Fingerprint-based, GNN-based, PLM-based, and SMILES-based models. Together, PepBenchmark provides the first standardized and comparable foundation for peptide drug discovery, facilitating methodological advances and translation into real-world applications. The data and code are publicly available at https://github.com/ZGCI-AI4S-Pep/PepBenchmark/.
Robometer: Scaling General-Purpose Robotic Reward Models via Trajectory Comparisons
Mar 02, 2026General-purpose robot reward models are typically trained to predict absolute task progress from expert demonstrations, providing only local, frame-level supervision. While effective for expert demonstrations, this paradigm scales poorly to large-scale robotics datasets where failed and suboptimal trajectories are abundant and assigning dense progress labels is ambiguous. We introduce Robometer, a scalable reward modeling framework that combines intra-trajectory progress supervision with inter-trajectory preference supervision. Robometer is trained with a dual objective: a frame-level progress loss that anchors reward magnitude on expert data, and a trajectory-comparison preference loss that imposes global ordering constraints across trajectories of the same task, enabling effective learning from both real and augmented failed trajectories. To support this formulation at scale, we curate RBM-1M, a reward-learning dataset comprising over one million trajectories spanning diverse robot embodiments and tasks, including substantial suboptimal and failure data. Across benchmarks and real-world evaluations, Robometer learns more generalizable reward functions than prior methods and improves robot learning performance across a diverse set of downstream applications. Code, model weights, and videos at https://robometer.github.io/.
Co-jump: Cooperative Jumping with Quadrupedal Robots via Multi-Agent Reinforcement Learning
Feb 11, 2026While single-agent legged locomotion has witnessed remarkable progress, individual robots remain fundamentally constrained by physical actuation limits. To transcend these boundaries, we introduce Co-jump, a cooperative task where two quadrupedal robots synchronize to execute jumps far beyond their solo capabilities. We tackle the high-impulse contact dynamics of this task under a decentralized setting, achieving synchronization without explicit communication or pre-specified motion primitives. Our framework leverages Multi-Agent Proximal Policy Optimization (MAPPO) enhanced by a progressive curriculum strategy, which effectively overcomes the sparse-reward exploration challenges inherent in mechanically coupled systems. We demonstrate robust performance in simulation and successful transfer to physical hardware, executing multi-directional jumps onto platforms up to 1.5 m in height. Specifically, one of the robots achieves a foot-end elevation of 1.1 m, which represents a 144% improvement over the 0.45 m jump height of a standalone quadrupedal robot, demonstrating superior vertical performance. Notably, this precise coordination is achieved solely through proprioceptive feedback, establishing a foundation for communication-free collaborative locomotion in constrained environments.
Learning Human-Like Badminton Skills for Humanoid Robots
Feb 09, 2026Realizing versatile and human-like performance in high-demand sports like badminton remains a formidable challenge for humanoid robotics. Unlike standard locomotion or static manipulation, this task demands a seamless integration of explosive whole-body coordination and precise, timing-critical interception. While recent advances have achieved lifelike motion mimicry, bridging the gap between kinematic imitation and functional, physics-aware striking without compromising stylistic naturalness is non-trivial. To address this, we propose Imitation-to-Interaction, a progressive reinforcement learning framework designed to evolve a robot from a "mimic" to a capable "striker." Our approach establishes a robust motor prior from human data, distills it into a compact, model-based state representation, and stabilizes dynamics via adversarial priors. Crucially, to overcome the sparsity of expert demonstrations, we introduce a manifold expansion strategy that generalizes discrete strike points into a dense interaction volume. We validate our framework through the mastery of diverse skills, including lifts and drop shots, in simulation. Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot, successfully replicating the kinetic elegance and functional precision of human athletes in the physical world.
HT-GNN: Hyper-Temporal Graph Neural Network for Customer Lifetime Value Prediction in Baidu Ads
Jan 19, 2026Lifetime value (LTV) prediction is crucial for news feed advertising, enabling platforms to optimize bidding and budget allocation for long-term revenue growth. However, it faces two major challenges: (1) demographic-based targeting creates segment-specific LTV distributions with large value variations across user groups; and (2) dynamic marketing strategies generate irregular behavioral sequences where engagement patterns evolve rapidly. We propose a Hyper-Temporal Graph Neural Network (HT-GNN), which jointly models demographic heterogeneity and temporal dynamics through three key components: (i) a hypergraph-supervised module capturing inter-segment relationships; (ii) a transformer-based temporal encoder with adaptive weighting; and (iii) a task-adaptive mixture-of-experts with dynamic prediction towers for multi-horizon LTV forecasting. Experiments on \textit{Baidu Ads} with 15 million users demonstrate that HT-GNN consistently outperforms state-of-the-art methods across all metrics and prediction horizons.
Bohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
Chemistry-Enhanced Diffusion-Based Framework for Small-to-Large Molecular Conformation Generation
Nov 15, 2025Obtaining 3D conformations of realistic polyatomic molecules at the quantum chemistry level remains challenging, and although recent machine learning advances offer promise, predicting large-molecule structures still requires substantial computational effort. Here, we introduce StoL, a diffusion model-based framework that enables rapid and knowledge-free generation of large molecular structures from small-molecule data. Remarkably, StoL assembles molecules in a LEGO-style fashion from scratch, without seeing the target molecules or any structures of comparable size during training. Given a SMILES input, it decomposes the molecule into chemically valid fragments, generates their 3D structures with a diffusion model trained on small molecules, and assembles them into diverse conformations. This fragment-based strategy eliminates the need for large-molecule training data while maintaining high scalability and transferability. By embedding chemical principles into key steps, StoL ensures faster convergence, chemically rational structures, and broad configurational coverage, as confirmed against DFT calculations.
ReWiND: Language-Guided Rewards Teach Robot Policies without New Demonstrations
May 16, 2025

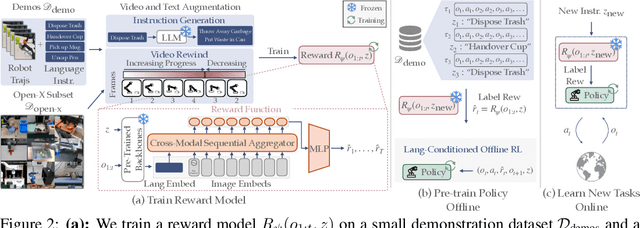
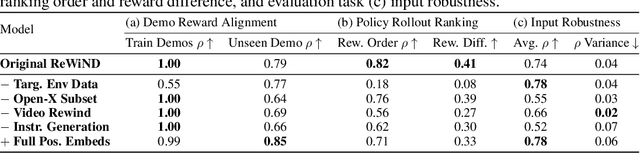
We introduce ReWiND, a framework for learning robot manipulation tasks solely from language instructions without per-task demonstrations. Standard reinforcement learning (RL) and imitation learning methods require expert supervision through human-designed reward functions or demonstrations for every new task. In contrast, ReWiND starts from a small demonstration dataset to learn: (1) a data-efficient, language-conditioned reward function that labels the dataset with rewards, and (2) a language-conditioned policy pre-trained with offline RL using these rewards. Given an unseen task variation, ReWiND fine-tunes the pre-trained policy using the learned reward function, requiring minimal online interaction. We show that ReWiND's reward model generalizes effectively to unseen tasks, outperforming baselines by up to 2.4x in reward generalization and policy alignment metrics. Finally, we demonstrate that ReWiND enables sample-efficient adaptation to new tasks, beating baselines by 2x in simulation and improving real-world pretrained bimanual policies by 5x, taking a step towards scalable, real-world robot learning. See website at https://rewind-reward.github.io/.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
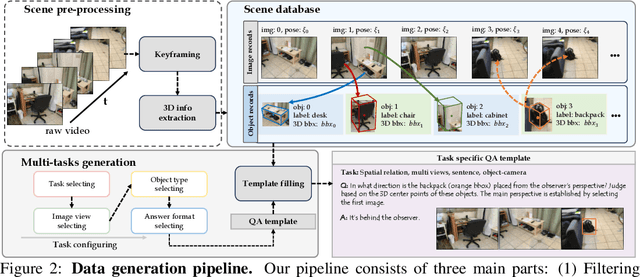
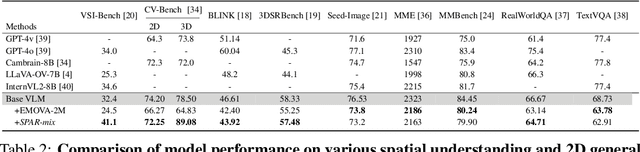

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.