 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Hierarchical Alignment Reasoning Network for Text-3D Retrieval
Nov 14, 2025With the daily influx of 3D data on the internet, text-3D retrieval has gained increasing attention. However, current methods face two major challenges: Hierarchy Representation Collapse (HRC) and Redundancy-Induced Saliency Dilution (RISD). HRC compresses abstract-to-specific and whole-to-part hierarchies in Euclidean embeddings, while RISD averages noisy fragments, obscuring critical semantic cues and diminishing the model's ability to distinguish hard negatives. To address these challenges, we introduce the Hyperbolic Hierarchical Alignment Reasoning Network (H$^{2}$ARN) for text-3D retrieval. H$^{2}$ARN embeds both text and 3D data in a Lorentz-model hyperbolic space, where exponential volume growth inherently preserves hierarchical distances. A hierarchical ordering loss constructs a shrinking entailment cone around each text vector, ensuring that the matched 3D instance falls within the cone, while an instance-level contrastive loss jointly enforces separation from non-matching samples. To tackle RISD, we propose a contribution-aware hyperbolic aggregation module that leverages Lorentzian distance to assess the relevance of each local feature and applies contribution-weighted aggregation guided by hyperbolic geometry, enhancing discriminative regions while suppressing redundancy without additional supervision. We also release the expanded T3DR-HIT v2 benchmark, which contains 8,935 text-to-3D pairs, 2.6 times the original size, covering both fine-grained cultural artefacts and complex indoor scenes. Our codes are available at https://github.com/liwrui/H2ARN.
Learning an Adaptive Fall Recovery Controller for Quadrupeds on Complex Terrains
Dec 22, 2024Legged robots have shown promise in locomotion complex environments, but recovery from falls on challenging terrains remains a significant hurdle. This paper presents an Adaptive Fall Recovery (AFR) controller for quadrupedal robots on challenging terrains such as rocky, breams, steep slopes, and irregular stones. We leverage deep reinforcement learning to train the AFR, which can adapt to a wide range of terrain geometries and physical properties. Our method demonstrates improvements over existing approaches, showing promising results in recovery scenarios on challenging terrains. We trained our method in Isaac Gym using the Go1 and directly transferred it to several mainstream quadrupedal platforms, such as Spot and ANYmal. Additionally, we validated the controller's effectiveness in Gazebo. Our results indicate that the AFR controller generalizes well to complex terrains and outperforms baseline methods in terms of success rate and recovery speed.
Digging into Intrinsic Contextual Information for High-fidelity 3D Point Cloud Completion
Dec 11, 2024



The common occurrence of occlusion-induced incompleteness in point clouds has made point cloud completion (PCC) a highly-concerned task in the field of geometric processing. Existing PCC methods typically produce complete point clouds from partial point clouds in a coarse-to-fine paradigm, with the coarse stage generating entire shapes and the fine stage improving texture details. Though diffusion models have demonstrated effectiveness in the coarse stage, the fine stage still faces challenges in producing high-fidelity results due to the ill-posed nature of PCC. The intrinsic contextual information for texture details in partial point clouds is the key to solving the challenge. In this paper, we propose a high-fidelity PCC method that digs into both short and long-range contextual information from the partial point cloud in the fine stage. Specifically, after generating the coarse point cloud via a diffusion-based coarse generator, a mixed sampling module introduces short-range contextual information from partial point clouds into the fine stage. A surface freezing modules safeguards points from noise-free partial point clouds against disruption. As for the long-range contextual information, we design a similarity modeling module to derive similarity with rigid transformation invariance between points, conducting effective matching of geometric manifold features globally. In this way, the high-quality components present in the partial point cloud serve as valuable references for refining the coarse point cloud with high fidelity. Extensive experiments have demonstrated the superiority of the proposed method over SOTA competitors. Our code is available at https://github.com/JS-CHU/ContextualCompletion.
Riemann-based Multi-scale Attention Reasoning Network for Text-3D Retrieval
Aug 25, 2024
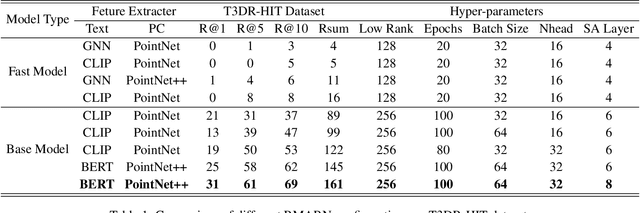


Due to the challenges in acquiring paired Text-3D data and the inherent irregularity of 3D data structures, combined representation learning of 3D point clouds and text remains unexplored. In this paper, we propose a novel Riemann-based Multi-scale Attention Reasoning Network (RMARN) for text-3D retrieval. Specifically, the extracted text and point cloud features are refined by their respective Adaptive Feature Refiner (AFR). Furthermore, we introduce the innovative Riemann Local Similarity (RLS) module and the Global Pooling Similarity (GPS) module. However, as 3D point cloud data and text data often possess complex geometric structures in high-dimensional space, the proposed RLS employs a novel Riemann Attention Mechanism to reflect the intrinsic geometric relationships of the data. Without explicitly defining the manifold, RMARN learns the manifold parameters to better represent the distances between text-point cloud samples. To address the challenges of lacking paired text-3D data, we have created the large-scale Text-3D Retrieval dataset T3DR-HIT, which comprises over 3,380 pairs of text and point cloud data. T3DR-HIT contains coarse-grained indoor 3D scenes and fine-grained Chinese artifact scenes, consisting of 1,380 and over 2,000 text-3D pairs, respectively. Experiments on our custom datasets demonstrate the superior performance of the proposed method. Our code and proposed datasets are available at \url{https://github.com/liwrui/RMARN}.