 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoamScene3D: Immersive Text-to-3D Scene Generation via Adaptive Object-aware Roaming
Jan 27, 2026Generating immersive 3D scenes from texts is a core task in computer vision, crucial for applications in virtual reality and game development. Despite the promise of leveraging 2D diffusion priors, existing methods suffer from spatial blindness and rely on predefined trajectories that fail to exploit the inner relationships among salient objects. Consequently, these approaches are unable to comprehend the semantic layout, preventing them from exploring the scene adaptively to infer occluded content. Moreover, current inpainting models operate in 2D image space, struggling to plausibly fill holes caused by camera motion. To address these limitations, we propose RoamScene3D, a novel framework that bridges the gap between semantic guidance and spatial generation. Our method reasons about the semantic relations among objects and produces consistent and photorealistic scenes. Specifically, we employ a vision-language model (VLM) to construct a scene graph that encodes object relations, guiding the camera to perceive salient object boundaries and plan an adaptive roaming trajectory. Furthermore, to mitigate the limitations of static 2D priors, we introduce a Motion-Injected Inpainting model that is fine-tuned on a synthetic panoramic dataset integrating authentic camera trajectories, making it adaptive to camera motion. Extensive experiments demonstrate that with semantic reasoning and geometric constraints, our method significantly outperforms state-of-the-art approaches in producing consistent and photorealistic scenes. Our code is available at https://github.com/JS-CHU/RoamScene3D.
ATATA: One Algorithm to Align Them All
Jan 16, 2026We suggest a new multi-modal algorithm for joint inference of paired structurally aligned samples with Rectified Flow models. While some existing methods propose a codependent generation process, they do not view the problem of joint generation from a structural alignment perspective. Recent work uses Score Distillation Sampling to generate aligned 3D models, but SDS is known to be time-consuming, prone to mode collapse, and often provides cartoonish results. By contrast, our suggested approach relies on the joint transport of a segment in the sample space, yielding faster computation at inference time. Our approach can be built on top of an arbitrary Rectified Flow model operating on the structured latent space. We show the applicability of our method to the domains of image, video, and 3D shape generation using state-of-the-art baselines and evaluate it against both editing-based and joint inference-based competing approaches. We demonstrate a high degree of structural alignment for the sample pairs obtained with our method and a high visual quality of the samples. Our method improves the state-of-the-art for image and video generation pipelines. For 3D generation, it is able to show comparable quality while working orders of magnitude faster.
All-in-One Video Restoration under Smoothly Evolving Unknown Weather Degradations
Jan 02, 2026All-in-one image restoration aims to recover clean images from diverse unknown degradations using a single model. But extending this task to videos faces unique challenges. Existing approaches primarily focus on frame-wise degradation variation, overlooking the temporal continuity that naturally exists in real-world degradation processes. In practice, degradation types and intensities evolve smoothly over time, and multiple degradations may coexist or transition gradually. In this paper, we introduce the Smoothly Evolving Unknown Degradations (SEUD) scenario, where both the active degradation set and degradation intensity change continuously over time. To support this scenario, we design a flexible synthesis pipeline that generates temporally coherent videos with single, compound, and evolving degradations. To address the challenges in the SEUD scenario, we propose an all-in-One Recurrent Conditional and Adaptive prompting Network (ORCANet). First, a Coarse Intensity Estimation Dehazing (CIED) module estimates haze intensity using physical priors and provides coarse dehazed features as initialization. Second, a Flow Prompt Generation (FPG) module extracts degradation features. FPG generates both static prompts that capture segment-level degradation types and dynamic prompts that adapt to frame-level intensity variations. Furthermore, a label-aware supervision mechanism improves the discriminability of static prompt representations under different degradations. Extensive experiments show that ORCANet achieves superior restoration quality, temporal consistency, and robustness over image and video-based baselines. Code is available at https://github.com/Friskknight/ORCANet-SEUD.
Language-Guided Graph Representation Learning for Video Summarization
Nov 14, 2025With the rapid growth of video content on social media, video summarization has become a crucial task in multimedia processing. However, existing methods face challenges in capturing global dependencies in video content and accommodating multimodal user customization. Moreover, temporal proximity between video frames does not always correspond to semantic proximity. To tackle these challenges, we propose a novel Language-guided Graph Representation Learning Network (LGRLN) for video summarization. Specifically, we introduce a video graph generator that converts video frames into a structured graph to preserve temporal order and contextual dependencies. By constructing forward, backward and undirected graphs, the video graph generator effectively preserves the sequentiality and contextual relationships of video content. We designed an intra-graph relational reasoning module with a dual-threshold graph convolution mechanism, which distinguishes semantically relevant frames from irrelevant ones between nodes. Additionally, our proposed language-guided cross-modal embedding module generates video summaries with specific textual descriptions. We model the summary generation output as a mixture of Bernoulli distribution and solve it with the EM algorithm. Experimental results show that our method outperforms existing approaches across multiple benchmarks. Moreover, we proposed LGRLN reduces inference time and model parameters by 87.8% and 91.7%, respectively. Our codes and pre-trained models are available at https://github.com/liwrui/LGRLN.
Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement
Nov 14, 2025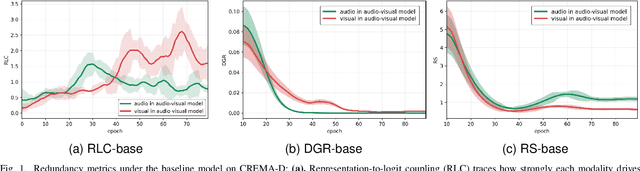
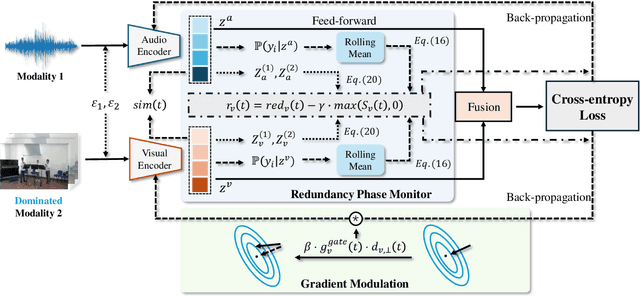
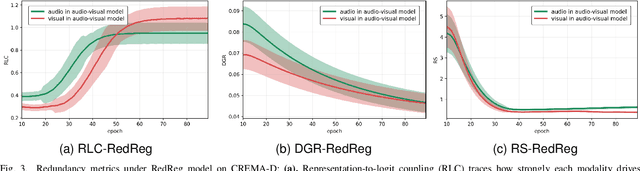
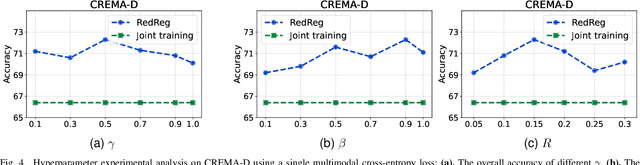
Multimodal learning aims to improve performance by leveraging data from multiple sources. During joint multimodal training, due to modality bias, the advantaged modality often dominates backpropagation, leading to imbalanced optimization. Existing methods still face two problems: First, the long-term dominance of the dominant modality weakens representation-output coupling in the late stages of training, resulting in the accumulation of redundant information. Second, previous methods often directly and uniformly adjust the gradients of the advantaged modality, ignoring the semantics and directionality between modalities. To address these limitations, we propose Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement (RedReg), which is inspired by information bottleneck principle. Specifically, we construct a redundancy phase monitor that uses a joint criterion of effective gain growth rate and redundancy to trigger intervention only when redundancy is high. Furthermore, we design a co-information gating mechanism to estimate the contribution of the current dominant modality based on cross-modal semantics. When the task primarily relies on a single modality, the suppression term is automatically disabled to preserve modality-specific information. Finally, we project the gradient of the dominant modality onto the orthogonal complement of the joint multimodal gradient subspace and suppress the gradient according to redundancy. Experiments show that our method demonstrates superiority among current major methods in most scenarios. Ablation experiments verify the effectiveness of our method. The code is available at https://github.com/xia-zhe/RedReg.git
Hyperbolic Hierarchical Alignment Reasoning Network for Text-3D Retrieval
Nov 14, 2025With the daily influx of 3D data on the internet, text-3D retrieval has gained increasing attention. However, current methods face two major challenges: Hierarchy Representation Collapse (HRC) and Redundancy-Induced Saliency Dilution (RISD). HRC compresses abstract-to-specific and whole-to-part hierarchies in Euclidean embeddings, while RISD averages noisy fragments, obscuring critical semantic cues and diminishing the model's ability to distinguish hard negatives. To address these challenges, we introduce the Hyperbolic Hierarchical Alignment Reasoning Network (H$^{2}$ARN) for text-3D retrieval. H$^{2}$ARN embeds both text and 3D data in a Lorentz-model hyperbolic space, where exponential volume growth inherently preserves hierarchical distances. A hierarchical ordering loss constructs a shrinking entailment cone around each text vector, ensuring that the matched 3D instance falls within the cone, while an instance-level contrastive loss jointly enforces separation from non-matching samples. To tackle RISD, we propose a contribution-aware hyperbolic aggregation module that leverages Lorentzian distance to assess the relevance of each local feature and applies contribution-weighted aggregation guided by hyperbolic geometry, enhancing discriminative regions while suppressing redundancy without additional supervision. We also release the expanded T3DR-HIT v2 benchmark, which contains 8,935 text-to-3D pairs, 2.6 times the original size, covering both fine-grained cultural artefacts and complex indoor scenes. Our codes are available at https://github.com/liwrui/H2ARN.
Perceptual Quality Assessment of 3D Gaussian Splatting: A Subjective Dataset and Prediction Metric
Nov 11, 2025
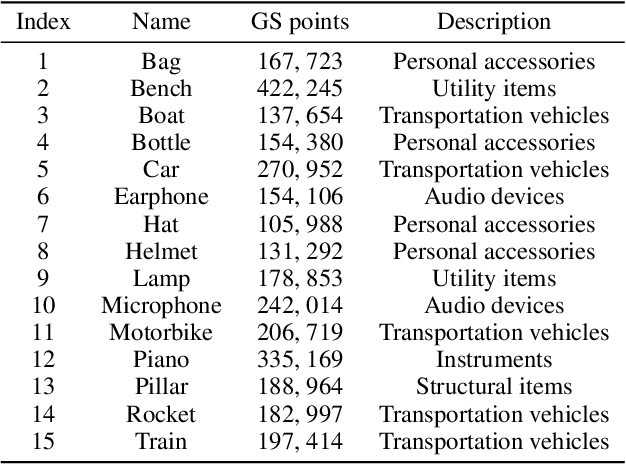
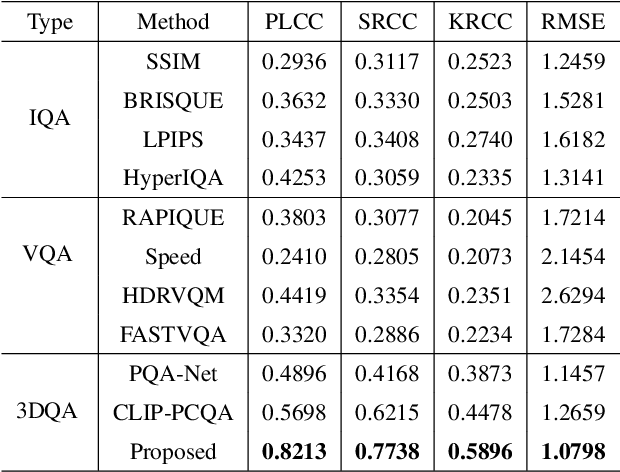
With the rapid advancement of 3D visualization, 3D Gaussian Splatting (3DGS) has emerged as a leading technique for real-time, high-fidelity rendering. While prior research has emphasized algorithmic performance and visual fidelity, the perceptual quality of 3DGS-rendered content, especially under varying reconstruction conditions, remains largely underexplored. In practice, factors such as viewpoint sparsity, limited training iterations, point downsampling, noise, and color distortions can significantly degrade visual quality, yet their perceptual impact has not been systematically studied. To bridge this gap, we present 3DGS-QA, the first subjective quality assessment dataset for 3DGS. It comprises 225 degraded reconstructions across 15 object types, enabling a controlled investigation of common distortion factors. Based on this dataset, we introduce a no-reference quality prediction model that directly operates on native 3D Gaussian primitives, without requiring rendered images or ground-truth references. Our model extracts spatial and photometric cues from the Gaussian representation to estimate perceived quality in a structure-aware manner. We further benchmark existing quality assessment methods, spanning both traditional and learning-based approaches. Experimental results show that our method consistently achieves superior performance, highlighting its robustness and effectiveness for 3DGS content evaluation. The dataset and code are made publicly available at https://github.com/diaoyn/3DGSQA to facilitate future research in 3DGS quality assessment.
An End-to-End Room Geometry Constrained Depth Estimation Framework for Indoor Panorama Images
Oct 09, 2025Predicting spherical pixel depth from monocular $360^{\circ}$ indoor panoramas is critical for many vision applications. However, existing methods focus on pixel-level accuracy, causing oversmoothed room corners and noise sensitivity. In this paper, we propose a depth estimation framework based on room geometry constraints, which extracts room geometry information through layout prediction and integrates those information into the depth estimation process through background segmentation mechanism. At the model level, our framework comprises a shared feature encoder followed by task-specific decoders for layout estimation, depth estimation, and background segmentation. The shared encoder extracts multi-scale features, which are subsequently processed by individual decoders to generate initial predictions: a depth map, a room layout map, and a background segmentation map. Furthermore, our framework incorporates two strategies: a room geometry-based background depth resolving strategy and a background-segmentation-guided fusion mechanism. The proposed room-geometry-based background depth resolving strategy leverages the room layout and the depth decoder's output to generate the corresponding background depth map. Then, a background-segmentation-guided fusion strategy derives fusion weights for the background and coarse depth maps from the segmentation decoder's predictions. Extensive experimental results on the Stanford2D3D, Matterport3D and Structured3D datasets show that our proposed methods can achieve significantly superior performance than current open-source methods. Our code is available at https://github.com/emiyaning/RGCNet.
Feature-aligned Motion Transformation for Efficient Dynamic Point Cloud Compression
Sep 18, 2025Dynamic point clouds are widely used in applications such as immersive reality, robotics, and autonomous driving. Efficient compression largely depends on accurate motion estimation and compensation, yet the irregular structure and significant local variations of point clouds make this task highly challenging. Current methods often rely on explicit motion estimation, whose encoded vectors struggle to capture intricate dynamics and fail to fully exploit temporal correlations. To overcome these limitations, we introduce a Feature-aligned Motion Transformation (FMT) framework for dynamic point cloud compression. FMT replaces explicit motion vectors with a spatiotemporal alignment strategy that implicitly models continuous temporal variations, using aligned features as temporal context within a latent-space conditional encoding framework. Furthermore, we design a random access (RA) reference strategy that enables bidirectional motion referencing and layered encoding, thereby supporting frame-level parallel compression. Extensive experiments demonstrate that our method surpasses D-DPCC and AdaDPCC in both encoding and decoding efficiency, while also achieving BD-Rate reductions of 20% and 9.4%, respectively. These results highlight the effectiveness of FMT in jointly improving compression efficiency and processing performance.
Region-Level Context-Aware Multimodal Understanding
Aug 17, 2025Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding -- an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects' visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC\&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM