 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Single Panoramic 3D Detection: A Semantic Gaussian Centric Approach
May 14, 2026Three-dimensional object detection in panoramic imagery is crucial for comprehensive scene understanding, yet accurately mapping 2D features to 3D remains a significant challenge. Prevailing methods often project 2D features onto discrete 3D grids, which break geometric continuity and limit representation efficiency. To overcome this limitation, this paper proposes PanoGSDet, a monocular panoramic 3D detection framework built upon continuous semantic 3D Gaussian representations. The proposed framework comprises a panoramic depth estimation component and a semantic Gaussian component. The panoramic depth estimation component extracts the equirectangular semantic and depth features from the monocular panorama input. The semantic Gaussian component includes a semantic Gaussian lifting module that projects spherical features into 3D semantic Gaussians, a semantic Gaussian optimization module that refines these semantic Gaussians, and a Gaussian guided prediction head that generates 3D bounding boxes from optimized Gaussian representations. Extensive experiments on the Structured3D dataset demonstrate that our method significantly outperforms existing methods.
Hyperbolic Distillation: Geometry-Guided Cross-Modal Transfer for Robust 3D Object Detection
May 11, 2026Cross-modal knowledge distillation has emerged as an effective strategy for integrating point cloud and image features in 3D perception tasks. However, the modality heterogeneity, spatial misalignment, and the representation crisis of multiple modalities often limit the efficient of these cross-modal distillation methods. To address these limitations in existing approaches, we propose a hyperbolic constrained cross-modal distillation method for multimodal 3D object detection (HGC-Det). The proposed HGC-Det framework includes an image branch and a point cloud branch to extract semantic features from two different modalities. The point cloud branch comprises three core components: a 2D semantic-guided voxel optimization component (SGVO), a hyperbolic geometry constrained cross-modal feature transfer component (HFT), and a feature aggregation-based geometry optimization component (FAGO). Specifically, the SGVO component adaptively refines the spatial representation of the 3D branch by leveraging semantic cues from the image branch, thereby mitigating the issue of inadequate representation fusion. The HFT component exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features. Finally, the FAGO compensates for potential spatial feature degradation introduced by the 2D semantic-guided voxel optimization component. Extensive experiments on indoor datasets (SUN RGB-D, ARKitScenes) and outdoor datasets (KITTI, nuScenes) demonstrate that our method achieves a better trade-off between detection accuracy and computational cost.
Just Noticeable Difference Modeling for Deep Visual Features
Jan 29, 2026Deep visual features are increasingly used as the interface in vision systems, motivating the need to describe feature characteristics and control feature quality for machine perception. Just noticeable difference (JND) characterizes the maximum imperceptible distortion for images under human or machine vision. Extending it to deep visual features naturally meets the above demand by providing a task-aligned tolerance boundary in feature space, offering a practical reference for controlling feature quality under constrained resources. We propose FeatJND, a task-aligned JND formulation that predicts the maximum tolerable per-feature perturbation map while preserving downstream task performance. We propose a FeatJND estimator at standardized split points and validate it across image classification, detection, and instance segmentation. Under matched distortion strength, FeatJND-based distortions consistently preserve higher task performance than unstructured Gaussian perturbations, and attribution visualizations suggest FeatJND can suppress non-critical feature regions. As an application, we further apply FeatJND to token-wise dynamic quantization and show that FeatJND-guided step-size allocation yields clear gains over random step-size permutation and global uniform step size under the same noise budget. Our code will be released after publication.
RoamScene3D: Immersive Text-to-3D Scene Generation via Adaptive Object-aware Roaming
Jan 27, 2026Generating immersive 3D scenes from texts is a core task in computer vision, crucial for applications in virtual reality and game development. Despite the promise of leveraging 2D diffusion priors, existing methods suffer from spatial blindness and rely on predefined trajectories that fail to exploit the inner relationships among salient objects. Consequently, these approaches are unable to comprehend the semantic layout, preventing them from exploring the scene adaptively to infer occluded content. Moreover, current inpainting models operate in 2D image space, struggling to plausibly fill holes caused by camera motion. To address these limitations, we propose RoamScene3D, a novel framework that bridges the gap between semantic guidance and spatial generation. Our method reasons about the semantic relations among objects and produces consistent and photorealistic scenes. Specifically, we employ a vision-language model (VLM) to construct a scene graph that encodes object relations, guiding the camera to perceive salient object boundaries and plan an adaptive roaming trajectory. Furthermore, to mitigate the limitations of static 2D priors, we introduce a Motion-Injected Inpainting model that is fine-tuned on a synthetic panoramic dataset integrating authentic camera trajectories, making it adaptive to camera motion. Extensive experiments demonstrate that with semantic reasoning and geometric constraints, our method significantly outperforms state-of-the-art approaches in producing consistent and photorealistic scenes. Our code is available at https://github.com/JS-CHU/RoamScene3D.
All-in-One Video Restoration under Smoothly Evolving Unknown Weather Degradations
Jan 02, 2026All-in-one image restoration aims to recover clean images from diverse unknown degradations using a single model. But extending this task to videos faces unique challenges. Existing approaches primarily focus on frame-wise degradation variation, overlooking the temporal continuity that naturally exists in real-world degradation processes. In practice, degradation types and intensities evolve smoothly over time, and multiple degradations may coexist or transition gradually. In this paper, we introduce the Smoothly Evolving Unknown Degradations (SEUD) scenario, where both the active degradation set and degradation intensity change continuously over time. To support this scenario, we design a flexible synthesis pipeline that generates temporally coherent videos with single, compound, and evolving degradations. To address the challenges in the SEUD scenario, we propose an all-in-One Recurrent Conditional and Adaptive prompting Network (ORCANet). First, a Coarse Intensity Estimation Dehazing (CIED) module estimates haze intensity using physical priors and provides coarse dehazed features as initialization. Second, a Flow Prompt Generation (FPG) module extracts degradation features. FPG generates both static prompts that capture segment-level degradation types and dynamic prompts that adapt to frame-level intensity variations. Furthermore, a label-aware supervision mechanism improves the discriminability of static prompt representations under different degradations. Extensive experiments show that ORCANet achieves superior restoration quality, temporal consistency, and robustness over image and video-based baselines. Code is available at https://github.com/Friskknight/ORCANet-SEUD.
Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement
Nov 14, 2025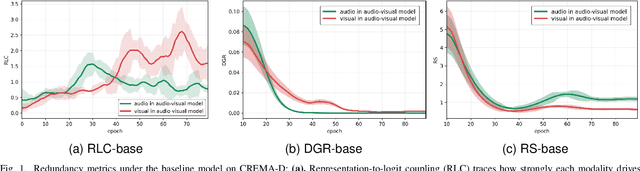
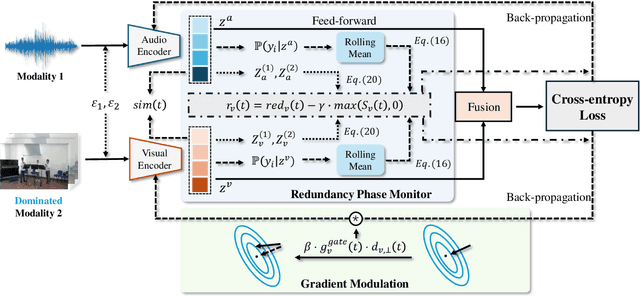
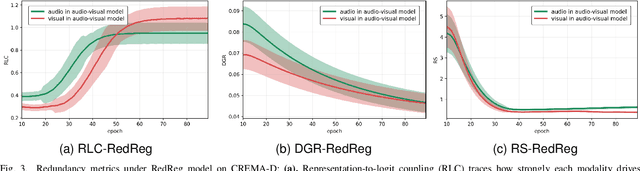
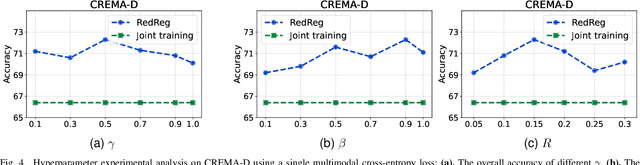
Multimodal learning aims to improve performance by leveraging data from multiple sources. During joint multimodal training, due to modality bias, the advantaged modality often dominates backpropagation, leading to imbalanced optimization. Existing methods still face two problems: First, the long-term dominance of the dominant modality weakens representation-output coupling in the late stages of training, resulting in the accumulation of redundant information. Second, previous methods often directly and uniformly adjust the gradients of the advantaged modality, ignoring the semantics and directionality between modalities. To address these limitations, we propose Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement (RedReg), which is inspired by information bottleneck principle. Specifically, we construct a redundancy phase monitor that uses a joint criterion of effective gain growth rate and redundancy to trigger intervention only when redundancy is high. Furthermore, we design a co-information gating mechanism to estimate the contribution of the current dominant modality based on cross-modal semantics. When the task primarily relies on a single modality, the suppression term is automatically disabled to preserve modality-specific information. Finally, we project the gradient of the dominant modality onto the orthogonal complement of the joint multimodal gradient subspace and suppress the gradient according to redundancy. Experiments show that our method demonstrates superiority among current major methods in most scenarios. Ablation experiments verify the effectiveness of our method. The code is available at https://github.com/xia-zhe/RedReg.git
Language-Guided Graph Representation Learning for Video Summarization
Nov 14, 2025With the rapid growth of video content on social media, video summarization has become a crucial task in multimedia processing. However, existing methods face challenges in capturing global dependencies in video content and accommodating multimodal user customization. Moreover, temporal proximity between video frames does not always correspond to semantic proximity. To tackle these challenges, we propose a novel Language-guided Graph Representation Learning Network (LGRLN) for video summarization. Specifically, we introduce a video graph generator that converts video frames into a structured graph to preserve temporal order and contextual dependencies. By constructing forward, backward and undirected graphs, the video graph generator effectively preserves the sequentiality and contextual relationships of video content. We designed an intra-graph relational reasoning module with a dual-threshold graph convolution mechanism, which distinguishes semantically relevant frames from irrelevant ones between nodes. Additionally, our proposed language-guided cross-modal embedding module generates video summaries with specific textual descriptions. We model the summary generation output as a mixture of Bernoulli distribution and solve it with the EM algorithm. Experimental results show that our method outperforms existing approaches across multiple benchmarks. Moreover, we proposed LGRLN reduces inference time and model parameters by 87.8% and 91.7%, respectively. Our codes and pre-trained models are available at https://github.com/liwrui/LGRLN.
Hyperbolic Hierarchical Alignment Reasoning Network for Text-3D Retrieval
Nov 14, 2025With the daily influx of 3D data on the internet, text-3D retrieval has gained increasing attention. However, current methods face two major challenges: Hierarchy Representation Collapse (HRC) and Redundancy-Induced Saliency Dilution (RISD). HRC compresses abstract-to-specific and whole-to-part hierarchies in Euclidean embeddings, while RISD averages noisy fragments, obscuring critical semantic cues and diminishing the model's ability to distinguish hard negatives. To address these challenges, we introduce the Hyperbolic Hierarchical Alignment Reasoning Network (H$^{2}$ARN) for text-3D retrieval. H$^{2}$ARN embeds both text and 3D data in a Lorentz-model hyperbolic space, where exponential volume growth inherently preserves hierarchical distances. A hierarchical ordering loss constructs a shrinking entailment cone around each text vector, ensuring that the matched 3D instance falls within the cone, while an instance-level contrastive loss jointly enforces separation from non-matching samples. To tackle RISD, we propose a contribution-aware hyperbolic aggregation module that leverages Lorentzian distance to assess the relevance of each local feature and applies contribution-weighted aggregation guided by hyperbolic geometry, enhancing discriminative regions while suppressing redundancy without additional supervision. We also release the expanded T3DR-HIT v2 benchmark, which contains 8,935 text-to-3D pairs, 2.6 times the original size, covering both fine-grained cultural artefacts and complex indoor scenes. Our codes are available at https://github.com/liwrui/H2ARN.
MRT: Learning Compact Representations with Mixed RWKV-Transformer for Extreme Image Compression
Nov 14, 2025Recent advances in extreme image compression have revealed that mapping pixel data into highly compact latent representations can significantly improve coding efficiency. However, most existing methods compress images into 2-D latent spaces via convolutional neural networks (CNNs) or Swin Transformers, which tend to retain substantial spatial redundancy, thereby limiting overall compression performance. In this paper, we propose a novel Mixed RWKV-Transformer (MRT) architecture that encodes images into more compact 1-D latent representations by synergistically integrating the complementary strengths of linear-attention-based RWKV and self-attention-based Transformer models. Specifically, MRT partitions each image into fixed-size windows, utilizing RWKV modules to capture global dependencies across windows and Transformer blocks to model local redundancies within each window. The hierarchical attention mechanism enables more efficient and compact representation learning in the 1-D domain. To further enhance compression efficiency, we introduce a dedicated RWKV Compression Model (RCM) tailored to the structure characteristics of the intermediate 1-D latent features in MRT. Extensive experiments on standard image compression benchmarks validate the effectiveness of our approach. The proposed MRT framework consistently achieves superior reconstruction quality at bitrates below 0.02 bits per pixel (bpp). Quantitative results based on the DISTS metric show that MRT significantly outperforms the state-of-the-art 2-D architecture GLC, achieving bitrate savings of 43.75%, 30.59% on the Kodak and CLIC2020 test datasets, respectively.
Interpretable Clustering with Adaptive Heterogeneous Causal Structure Learning in Mixed Observational Data
Sep 04, 2025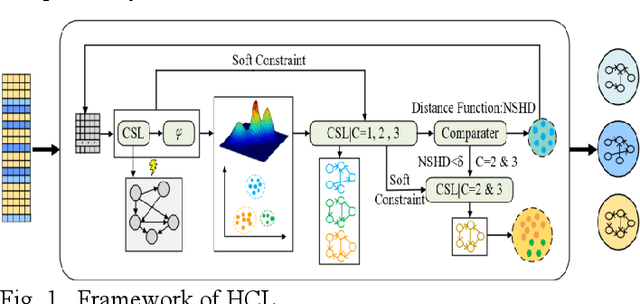
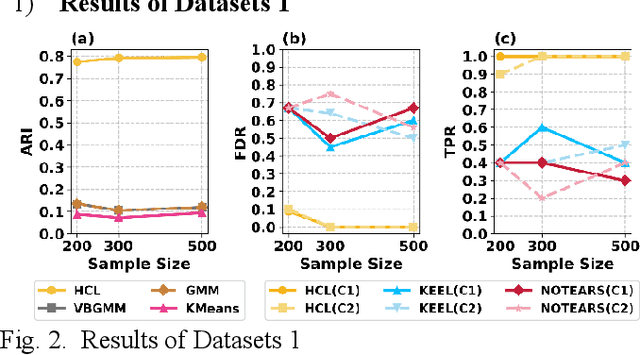
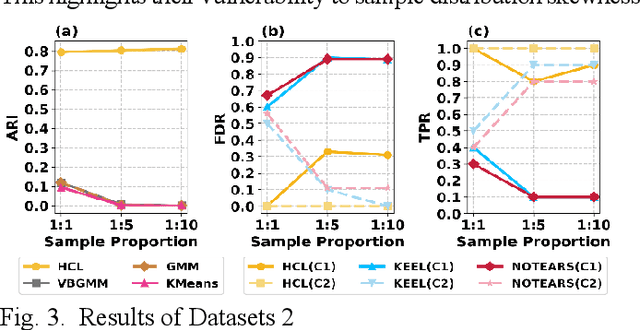
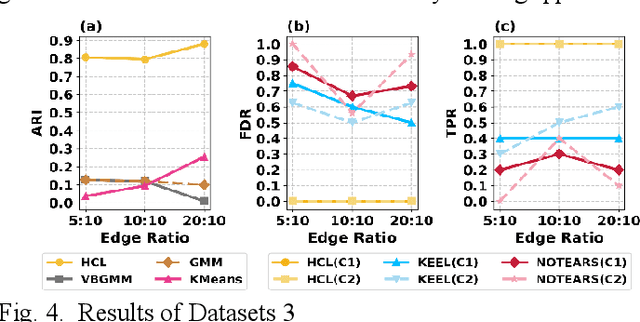
Understanding causal heterogeneity is essential for scientific discovery in domains such as biology and medicine. However, existing methods lack causal awareness, with insufficient modeling of heterogeneity, confounding, and observational constraints, leading to poor interpretability and difficulty distinguishing true causal heterogeneity from spurious associations. We propose an unsupervised framework, HCL (Interpretable Causal Mechanism-Aware Clustering with Adaptive Heterogeneous Causal Structure Learning), that jointly infers latent clusters and their associated causal structures from mixed-type observational data without requiring temporal ordering, environment labels, interventions or other prior knowledge. HCL relaxes the homogeneity and sufficiency assumptions by introducing an equivalent representation that encodes both structural heterogeneity and confounding. It further develops a bi-directional iterative strategy to alternately refine causal clustering and structure learning, along with a self-supervised regularization that balance cross-cluster universality and specificity. Together, these components enable convergence toward interpretable, heterogeneous causal patterns. Theoretically, we show identifiability of heterogeneous causal structures under mild conditions. Empirically, HCL achieves superior performance in both clustering and structure learning tasks, and recovers biologically meaningful mechanisms in real-world single-cell perturbation data, demonstrating its utility for discovering interpretable, mechanism-level causal heterogeneity.