 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Diversity Collapse in RLVR via the Lens of Overtraining
Jun 13, 2026Reinforcement learning with verifiable rewards (RLVR) has become a key approach for enhancing the reasoning abilities of large language models. However, RLVR often suffers from \emph{diversity collapse}: Pass@$1$ improves while high-$k$ Pass@$k$ degrades, which is viewed as a narrowing of the model's reasoning boundary. We formalize this diversity collapse through the lens of \emph{overtraining}: once a problem's contribution to the reference metric has effectively saturated, further updates no longer expand what the model can solve but still concentrate probability mass on the trajectories favored by on-policy sampling. Under a standard setup with few rollouts per problem, even a single observed success places a problem in a nearly saturated regime for high-$k$ Pass@$k$, so most updates in standard RLVR are overtraining from the boundary perspective. This perspective also suggests a reading of whether RLVR can expand the model's reasoning abilities beyond the base model: since RLVR is structurally biased against high-$k$ Pass@$k$, its aggregate decline does not by itself mean that no new reasoning gains occurred. Interventionally, restricting updates to problems with zero observed success lifts Pass@$256$ above the base model on difficult benchmarks; observationally, a non-trivial fraction of initially unsolvable problems become solvable during standard RLVR training. Building on these findings, we propose \emph{Bayesian Boundary Gating} (BBG), which redirects optimization away from overtraining by estimating each problem's marginal contribution to the reasoning boundary. Across multiple reasoning benchmarks, BBG improves average Pass@$k$ across a wide range of $k$.
Model Forensics in AI-Native Wireless Networks: Taxonomy, Applications, and Case Study
May 14, 2026As artificial intelligence (AI) is increasingly embedded in wireless networks, models are becoming core components that influence signal processing, resource scheduling and network control. However, model anomalies, tampering and malicious functions also introduce new security risks. In this article, we focus on model forensics in AI-native wireless networks. Specifically, we first discuss key problems including model authenticity verification, malicious function identification and accountability tracing, and summarize the main categories of model forensics. We then explain the role of model forensics in AI-native wireless networks and review representative application scenarios. In the case study, we use RF fingerprinting as an example and present two concrete workflows based on watermark authentication and backdoor detection, illustrating how provenance authentication and malicious behavior identification can be implemented in practice. The results show that model forensics can provide important support for anomaly assessment, provenance tracing and trustworthy operation in AI-native wireless networks. Finally, we outline several promising directions for future research in this emerging area.
Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation
Apr 27, 2026Unified multimodal models typically rely on pretrained vision encoders and use separate visual representations for understanding and generation, creating misalignment between the two tasks and preventing fully end-to-end optimization from raw pixels. We introduce Tuna-2, a native unified multimodal model that performs visual understanding and generation directly based on pixel embeddings. Tuna-2 drastically simplifies the model architecture by employing simple patch embedding layers to encode visual input, completely discarding the modular vision encoder designs such as the VAE or the representation encoder. Experiments show that Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modelling can fully compete with latent-space approaches for high-quality image generation. Moreover, while the encoder-based variant converges faster in early pretraining, Tuna-2's encoder-free design achieves stronger multimodal understanding at scale, particularly on tasks requiring fine-grained visual perception. These results show that pretrained vision encoders are not necessary for multimodal modelling, and end-to-end pixel-space learning offers a scalable path toward stronger visual representations for both generation and perception.
Rays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Apr 10, 2026Recovering camera parameters from images and rendering scenes from novel viewpoints have long been treated as separate tasks in computer vision and graphics. This separation breaks down when image coverage is sparse or poses are ambiguous, since each task needs what the other produces. We propose Rays as Pixels, a Video Diffusion Model (VDM) that learns a joint distribution over videos and camera trajectories. We represent each camera as dense ray pixels (raxels) and denoise them jointly with video frames through Decoupled Self-Cross Attention mechanism. A single trained model handles three tasks: predicting camera trajectories from video, jointly generating video and camera trajectory from input images, and generating video from input images along a target camera trajectory. Because the model can both predict trajectories from a video and generate views conditioned on its own predictions, we evaluate it through a closed-loop self-consistency test, demonstrating that its forward and inverse predictions agree. Notably, trajectory prediction requires far fewer denoising steps than video generation, even a few denoising steps suffice for self-consistency. We report results on pose estimation and camera-controlled video generation.
Intelligent Forensics in Next-Generation Mobile Networks: Evidence, Methods, and Applications
Mar 31, 2026This survey examines intelligent forensics in next-generation mobile networks, arguing that future wireless security must move beyond real-time detection toward accountable post-incident reconstruction. Unlike traditional digital forensics, wireless investigations rely on short-lived, distributed, and heterogeneous evidence, including radio waveforms, channel measurements, device-side artifacts, and network telemetry, affected by calibration, timing uncertainty, privacy constraints, and adversarial manipulation. To address this limitation, this paper develops an evidence-centric framework that treats wireless measurements as first-class forensic artifacts and organizes the field through a unified taxonomy spanning physical-layer, device-layer, network-layer, and cross-layer forensics. We further systematize the forensic workflow into readiness and preservation-by-design, acquisition, correlation and analysis, and reporting and reproducibility, while comparing the complementary roles of traditional methods and artificial intelligence-assisted techniques. Subsequently, we review major application areas, including anomaly discovery, attribution, provenance and localization, authenticity verification, and timeline reconstruction. Finally, we identify key open challenges, including domain shift, resource-aware evidence capture, and the benefits and admissibility risks of generative evidence. Overall, this paper positions wireless forensics as a foundational capability for trustworthy, auditable, and reproducible security in next-generation wireless systems. Readers can understand and streamline wireless forensics processes for specific applications, such as low-altitude wireless networks, vehicular communications, and edge general intelligence.
TransText: Alpha-as-RGB Representation for Transparent Text Animation
Mar 19, 2026We introduce the first method, to the best of our knowledge, for adapting image-to-video models to layer-aware text (glyph) animation, a capability critical for practical dynamic visual design. Existing approaches predominantly handle the transparency-encoding (alpha channel) as an extra latent dimension appended to the RGB space, necessitating the reconstruction of the underlying RGB-centric variational autoencoder (VAE). However, given the scarcity of high-quality transparent glyph data, retraining the VAE is computationally expensive and may erode the robust semantic priors learned from massive RGB corpora, potentially leading to latent pattern mixing. To mitigate these limitations, we propose TransText, a framework based on a novel Alpha-as-RGB paradigm to jointly model appearance and transparency without modifying the pre-trained generative manifold. TransText embeds the alpha channel as an RGB-compatible visual signal through latent spatial concatenation, explicitly ensuring strict cross-modal (RGB-and-Alpha) consistency while preventing feature entanglement. Our experiments demonstrate that TransText significantly outperforms baselines, generating coherent, high-fidelity transparent animations with diverse, fine-grained effects.
VecGlypher: Unified Vector Glyph Generation with Language Models
Feb 25, 2026Vector glyphs are the atomic units of digital typography, yet most learning-based pipelines still depend on carefully curated exemplar sheets and raster-to-vector postprocessing, which limits accessibility and editability. We introduce VecGlypher, a single multimodal language model that generates high-fidelity vector glyphs directly from text descriptions or image exemplars. Given a style prompt, optional reference glyph images, and a target character, VecGlypher autoregressively emits SVG path tokens, avoiding raster intermediates and producing editable, watertight outlines in one pass. A typography-aware data and training recipe makes this possible: (i) a large-scale continuation stage on 39K noisy Envato fonts to master SVG syntax and long-horizon geometry, followed by (ii) post-training on 2.5K expert-annotated Google Fonts with descriptive tags and exemplars to align language and imagery with geometry; preprocessing normalizes coordinate frames, canonicalizes paths, de-duplicates families, and quantizes coordinates for stable long-sequence decoding. On cross-family OOD evaluation, VecGlypher substantially outperforms both general-purpose LLMs and specialized vector-font baselines for text-only generation, while image-referenced generation reaches a state-of-the-art performance, with marked gains over DeepVecFont-v2 and DualVector. Ablations show that model scale and the two-stage recipe are critical and that absolute-coordinate serialization yields the best geometry. VecGlypher lowers the barrier to font creation by letting users design with words or exemplars, and provides a scalable foundation for future multimodal design tools.
HiStream: Efficient High-Resolution Video Generation via Redundancy-Eliminated Streaming
Dec 24, 2025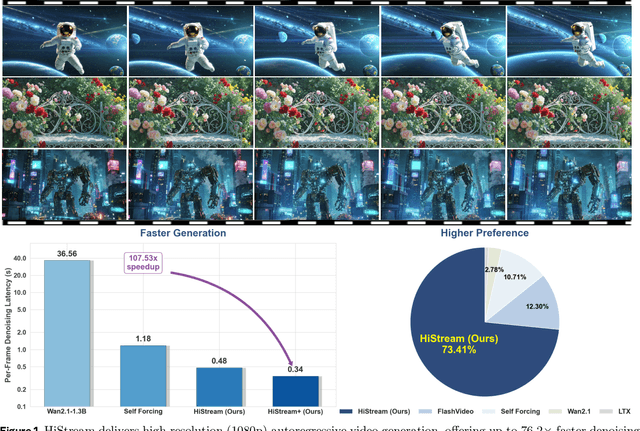
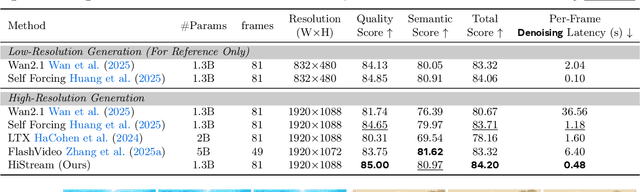
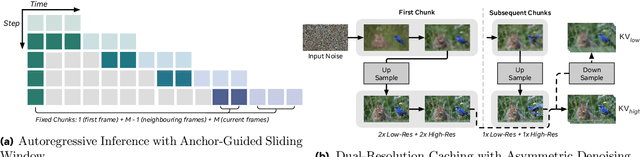
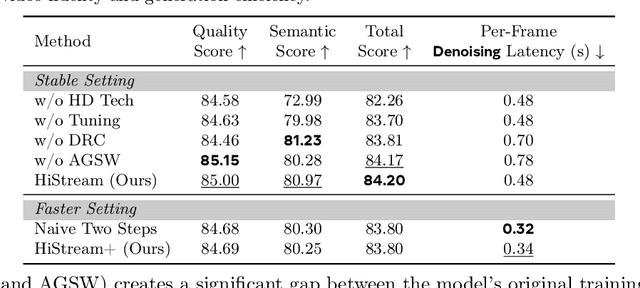
High-resolution video generation, while crucial for digital media and film, is computationally bottlenecked by the quadratic complexity of diffusion models, making practical inference infeasible. To address this, we introduce HiStream, an efficient autoregressive framework that systematically reduces redundancy across three axes: i) Spatial Compression: denoising at low resolution before refining at high resolution with cached features; ii) Temporal Compression: a chunk-by-chunk strategy with a fixed-size anchor cache, ensuring stable inference speed; and iii) Timestep Compression: applying fewer denoising steps to subsequent, cache-conditioned chunks. On 1080p benchmarks, our primary HiStream model (i+ii) achieves state-of-the-art visual quality while demonstrating up to 76.2x faster denoising compared to the Wan2.1 baseline and negligible quality loss. Our faster variant, HiStream+, applies all three optimizations (i+ii+iii), achieving a 107.5x acceleration over the baseline, offering a compelling trade-off between speed and quality, thereby making high-resolution video generation both practical and scalable.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
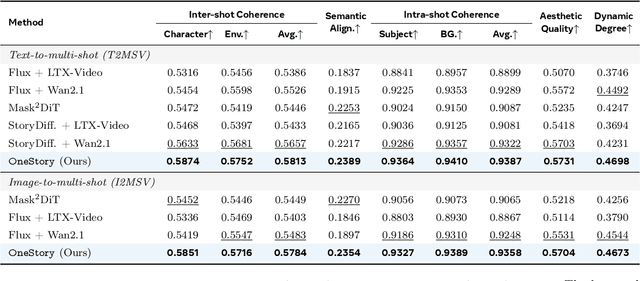
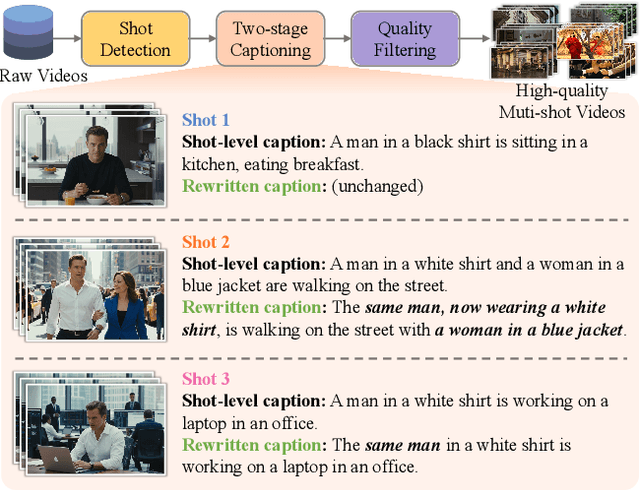

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.