 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural at ArchEHR-QA 2025: Agentic Prompt Optimization for Evidence-Grounded Clinical Question Answering
Jun 12, 2025Automated question answering (QA) over electronic health records (EHRs) can bridge critical information gaps for clinicians and patients, yet it demands both precise evidence retrieval and faithful answer generation under limited supervision. In this work, we present Neural, the runner-up in the BioNLP 2025 ArchEHR-QA shared task on evidence-grounded clinical QA. Our proposed method decouples the task into (1) sentence-level evidence identification and (2) answer synthesis with explicit citations. For each stage, we automatically explore the prompt space with DSPy's MIPROv2 optimizer, jointly tuning instructions and few-shot demonstrations on the development set. A self-consistency voting scheme further improves evidence recall without sacrificing precision. On the hidden test set, our method attains an overall score of 51.5, placing second stage while outperforming standard zero-shot and few-shot prompting by over 20 and 10 points, respectively. These results indicate that data-driven prompt optimization is a cost-effective alternative to model fine-tuning for high-stakes clinical QA, advancing the reliability of AI assistants in healthcare.
LETS Forecast: Learning Embedology for Time Series Forecasting
Jun 06, 2025Real-world time series are often governed by complex nonlinear dynamics. Understanding these underlying dynamics is crucial for precise future prediction. While deep learning has achieved major success in time series forecasting, many existing approaches do not explicitly model the dynamics. To bridge this gap, we introduce DeepEDM, a framework that integrates nonlinear dynamical systems modeling with deep neural networks. Inspired by empirical dynamic modeling (EDM) and rooted in Takens' theorem, DeepEDM presents a novel deep model that learns a latent space from time-delayed embeddings, and employs kernel regression to approximate the underlying dynamics, while leveraging efficient implementation of softmax attention and allowing for accurate prediction of future time steps. To evaluate our method, we conduct comprehensive experiments on synthetic data of nonlinear dynamical systems as well as real-world time series across domains. Our results show that DeepEDM is robust to input noise, and outperforms state-of-the-art methods in forecasting accuracy. Our code is available at: https://abrarmajeedi.github.io/deep_edm.
Freestyle Sketch-in-the-Loop Image Segmentation
Jan 27, 2025In this paper, we expand the domain of sketch research into the field of image segmentation, aiming to establish freehand sketches as a query modality for subjective image segmentation. Our innovative approach introduces a "sketch-in-the-loop" image segmentation framework, enabling the segmentation of visual concepts partially, completely, or in groupings - a truly "freestyle" approach - without the need for a purpose-made dataset (i.e., mask-free). This framework capitalises on the synergy between sketch-based image retrieval (SBIR) models and large-scale pre-trained models (CLIP or DINOv2). The former provides an effective training signal, while fine-tuned versions of the latter execute the subjective segmentation. Additionally, our purpose-made augmentation strategy enhances the versatility of our sketch-guided mask generation, allowing segmentation at multiple granularity levels. Extensive evaluations across diverse benchmark datasets underscore the superior performance of our method in comparison to existing approaches across various evaluation scenarios.
RICA2: Rubric-Informed, Calibrated Assessment of Actions
Aug 06, 2024



The ability to quantify how well an action is carried out, also known as action quality assessment (AQA), has attracted recent interest in the vision community. Unfortunately, prior methods often ignore the score rubric used by human experts and fall short of quantifying the uncertainty of the model prediction. To bridge the gap, we present RICA^2 - a deep probabilistic model that integrates score rubric and accounts for prediction uncertainty for AQA. Central to our method lies in stochastic embeddings of action steps, defined on a graph structure that encodes the score rubric. The embeddings spread probabilistic density in the latent space and allow our method to represent model uncertainty. The graph encodes the scoring criteria, based on which the quality scores can be decoded. We demonstrate that our method establishes new state of the art on public benchmarks, including FineDiving, MTL-AQA, and JIGSAWS, with superior performance in score prediction and uncertainty calibration. Our code is available at https://abrarmajeedi.github.io/rica2_aqa/
Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches
Mar 28, 2022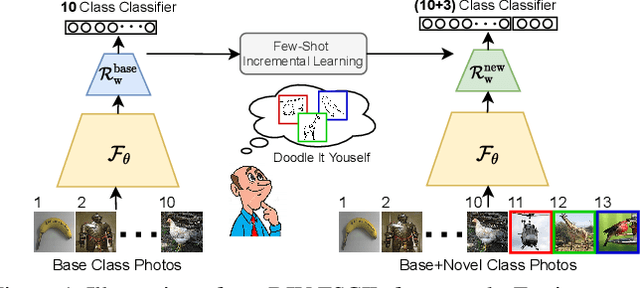
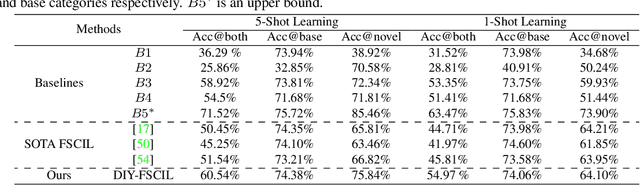
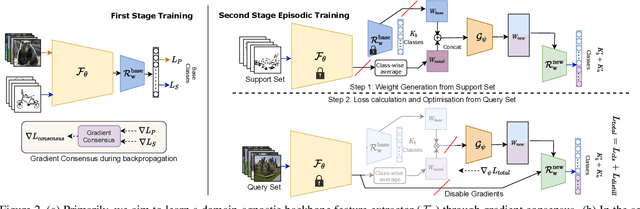
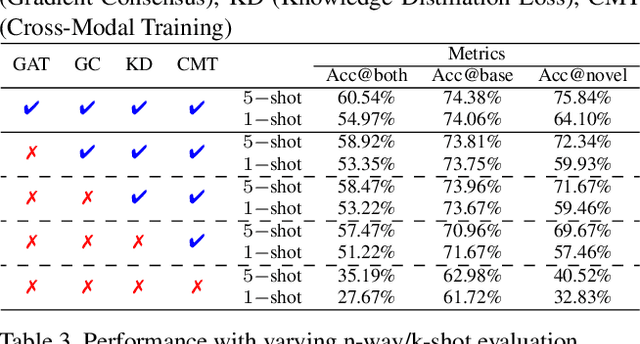
The human visual system is remarkable in learning new visual concepts from just a few examples. This is precisely the goal behind few-shot class incremental learning (FSCIL), where the emphasis is additionally placed on ensuring the model does not suffer from "forgetting". In this paper, we push the boundary further for FSCIL by addressing two key questions that bottleneck its ubiquitous application (i) can the model learn from diverse modalities other than just photo (as humans do), and (ii) what if photos are not readily accessible (due to ethical and privacy constraints). Our key innovation lies in advocating the use of sketches as a new modality for class support. The product is a "Doodle It Yourself" (DIY) FSCIL framework where the users can freely sketch a few examples of a novel class for the model to learn to recognize photos of that class. For that, we present a framework that infuses (i) gradient consensus for domain invariant learning, (ii) knowledge distillation for preserving old class information, and (iii) graph attention networks for message passing between old and novel classes. We experimentally show that sketches are better class support than text in the context of FSCIL, echoing findings elsewhere in the sketching literature.
Partially Does It: Towards Scene-Level FG-SBIR with Partial Input
Mar 28, 2022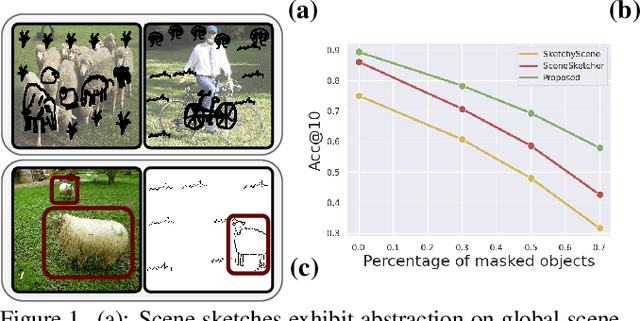
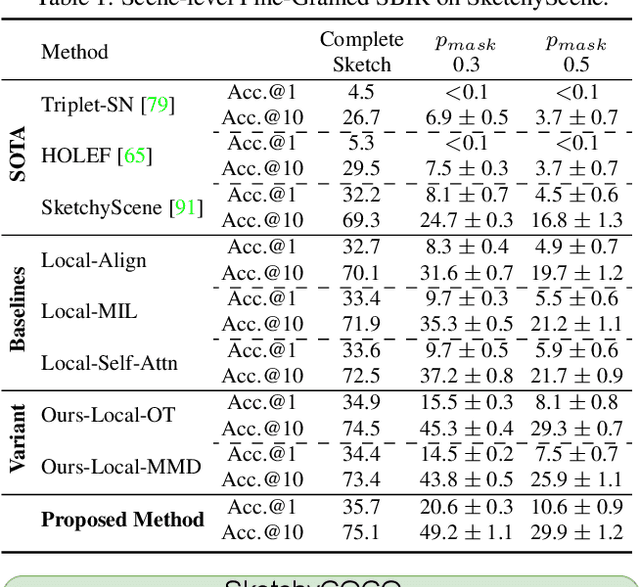

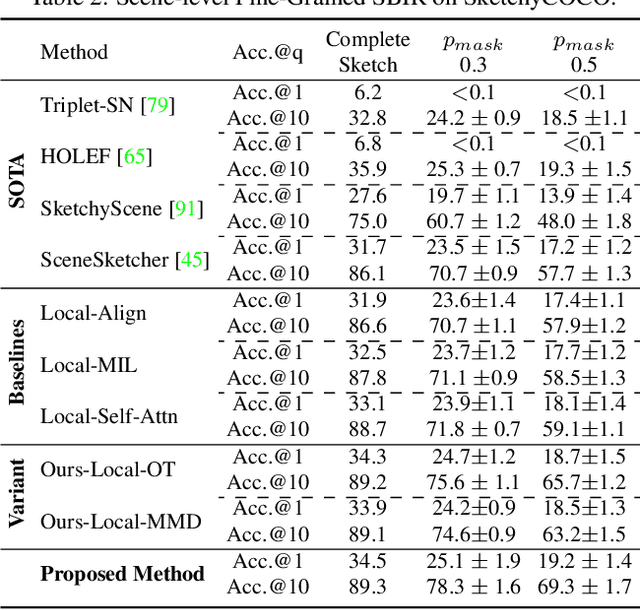
We scrutinise an important observation plaguing scene-level sketch research -- that a significant portion of scene sketches are "partial". A quick pilot study reveals: (i) a scene sketch does not necessarily contain all objects in the corresponding photo, due to the subjective holistic interpretation of scenes, (ii) there exists significant empty (white) regions as a result of object-level abstraction, and as a result, (iii) existing scene-level fine-grained sketch-based image retrieval methods collapse as scene sketches become more partial. To solve this "partial" problem, we advocate for a simple set-based approach using optimal transport (OT) to model cross-modal region associativity in a partially-aware fashion. Importantly, we improve upon OT to further account for holistic partialness by comparing intra-modal adjacency matrices. Our proposed method is not only robust to partial scene-sketches but also yields state-of-the-art performance on existing datasets.
MERANet: Facial Micro-Expression Recognition using 3D Residual Attention Network
Dec 07, 2020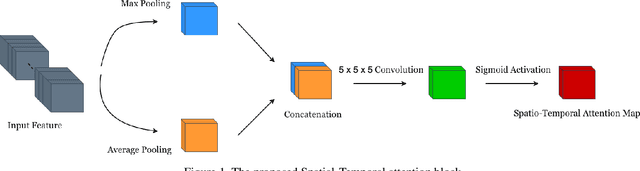
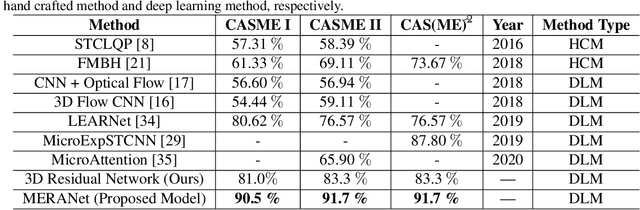

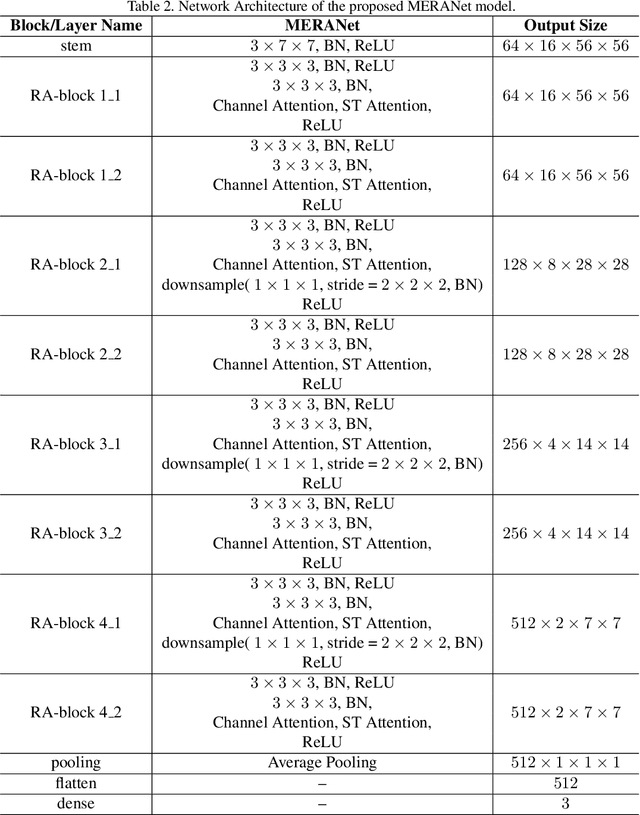
We propose a facial micro-expression recognition model using 3D residual attention network called MERANet. The proposed model takes advantage of spatial-temporal attention and channel attention together, to learn deeper fine-grained subtle features for classification of emotions. The proposed model also encompasses both spatial and temporal information simultaneously using the 3D kernels and residual connections. Moreover, the channel features and spatio-temporal features are re-calibrated using the channel and spatio-temporal attentions, respectively in each residual module. The experiments are conducted on benchmark facial micro-expression datasets. A superior performance is observed as compared to the state-of-the-art for facial micro-expression recognition.