 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural at ArchEHR-QA 2026: One Method Fits All: Unified Prompt Optimization for Clinical QA over EHRs
May 11, 2026Automated question answering (QA) over electronic health records (EHRs) demands precise evidence retrieval, faithful answer generation, and explicit grounding of answers in clinical notes. In this work, we present Neural1.5, our method for the ArchEHR-QA 2026 shared task at CL4Health@LREC 2026, which comprises four subtasks: question interpretation, evidence identification, answer generation, and evidence alignment. Our approach decouples the task into independent, modular stages and employs DSPy"s MIPROv2 optimizer to automatically discover high-performing prompts, jointly tuning instructions and few-shot demonstrations for each stage. Within every stage, self-consistency voting over multiple stochastic inference runs suppresses spurious errors and improves reliability, while stage-specific verification mechanisms (e.g., self-reflection and chain-of-verification for alignment) further refine output quality. Among all teams that participated in all four subtasks, our method ranks second overall (mean rank 4.00), placing 4th, 1st, 4th, and 7th on Subtasks 1-4, respectively. These results demonstrate that systematic, per-stage prompt optimization combined with self-consistency mechanisms is a cost-effective alternative to model fine-tuning for multifaceted clinical QA.
DUALVISION: RGB-Infrared Multimodal Large Language Models for Robust Visual Reasoning
Apr 20, 2026Multimodal large language models (MLLMs) have achieved impressive performance on visual perception and reasoning tasks with RGB imagery, yet they remain fragile under common degradations, such as fog, blur, or low-light conditions. Infrared (IR) imaging, a well-established complement to RGB, offers inherent robustness in these conditions, but its integration into MLLMs remains underexplored. To bridge this gap, we propose DUALVISION, a lightweight fusion module that efficiently incorporates IR-RGB information into MLLMs via patch-level localized cross-attention. To support training and evaluation and to facilitate future research, we also introduce DV-204K, a dataset of ~25K publicly available aligned IR-RGB image pairs with 204K modality-specific QA annotations, and DV-500, a benchmark of 500 IR-RGB image pairs with 500 QA pairs designed for evaluating cross-modal reasoning. Leveraging these datasets, we benchmark both open- and closed-source MLLMs and demonstrate that DUALVISION delivers strong empirical performance under a wide range of visual degradations. Our code and dataset are available at https://abrarmajeedi.github.io/dualvision.
SimpleCall: A Lightweight Image Restoration Agent in Label-Free Environments with MLLM Perceptual Feedback
Dec 21, 2025Complex image restoration aims to recover high-quality images from inputs affected by multiple degradations such as blur, noise, rain, and compression artifacts. Recent restoration agents, powered by vision-language models and large language models, offer promising restoration capabilities but suffer from significant efficiency bottlenecks due to reflection, rollback, and iterative tool searching. Moreover, their performance heavily depends on degradation recognition models that require extensive annotations for training, limiting their applicability in label-free environments. To address these limitations, we propose a policy optimization-based restoration framework that learns an lightweight agent to determine tool-calling sequences. The agent operates in a sequential decision process, selecting the most appropriate restoration operation at each step to maximize final image quality. To enable training within label-free environments, we introduce a novel reward mechanism driven by multimodal large language models, which act as human-aligned evaluator and provide perceptual feedback for policy improvement. Once trained, our agent executes a deterministic restoration plans without redundant tool invocations, significantly accelerating inference while maintaining high restoration quality. Extensive experiments show that despite using no supervision, our method matches SOTA performance on full-reference metrics and surpasses existing approaches on no-reference metrics across diverse degradation scenarios.
Neural at ArchEHR-QA 2025: Agentic Prompt Optimization for Evidence-Grounded Clinical Question Answering
Jun 12, 2025Automated question answering (QA) over electronic health records (EHRs) can bridge critical information gaps for clinicians and patients, yet it demands both precise evidence retrieval and faithful answer generation under limited supervision. In this work, we present Neural, the runner-up in the BioNLP 2025 ArchEHR-QA shared task on evidence-grounded clinical QA. Our proposed method decouples the task into (1) sentence-level evidence identification and (2) answer synthesis with explicit citations. For each stage, we automatically explore the prompt space with DSPy's MIPROv2 optimizer, jointly tuning instructions and few-shot demonstrations on the development set. A self-consistency voting scheme further improves evidence recall without sacrificing precision. On the hidden test set, our method attains an overall score of 51.5, placing second stage while outperforming standard zero-shot and few-shot prompting by over 20 and 10 points, respectively. These results indicate that data-driven prompt optimization is a cost-effective alternative to model fine-tuning for high-stakes clinical QA, advancing the reliability of AI assistants in healthcare.
LETS Forecast: Learning Embedology for Time Series Forecasting
Jun 06, 2025



Real-world time series are often governed by complex nonlinear dynamics. Understanding these underlying dynamics is crucial for precise future prediction. While deep learning has achieved major success in time series forecasting, many existing approaches do not explicitly model the dynamics. To bridge this gap, we introduce DeepEDM, a framework that integrates nonlinear dynamical systems modeling with deep neural networks. Inspired by empirical dynamic modeling (EDM) and rooted in Takens' theorem, DeepEDM presents a novel deep model that learns a latent space from time-delayed embeddings, and employs kernel regression to approximate the underlying dynamics, while leveraging efficient implementation of softmax attention and allowing for accurate prediction of future time steps. To evaluate our method, we conduct comprehensive experiments on synthetic data of nonlinear dynamical systems as well as real-world time series across domains. Our results show that DeepEDM is robust to input noise, and outperforms state-of-the-art methods in forecasting accuracy. Our code is available at: https://abrarmajeedi.github.io/deep_edm.
RICA2: Rubric-Informed, Calibrated Assessment of Actions
Aug 06, 2024



The ability to quantify how well an action is carried out, also known as action quality assessment (AQA), has attracted recent interest in the vision community. Unfortunately, prior methods often ignore the score rubric used by human experts and fall short of quantifying the uncertainty of the model prediction. To bridge the gap, we present RICA^2 - a deep probabilistic model that integrates score rubric and accounts for prediction uncertainty for AQA. Central to our method lies in stochastic embeddings of action steps, defined on a graph structure that encodes the score rubric. The embeddings spread probabilistic density in the latent space and allow our method to represent model uncertainty. The graph encodes the scoring criteria, based on which the quality scores can be decoded. We demonstrate that our method establishes new state of the art on public benchmarks, including FineDiving, MTL-AQA, and JIGSAWS, with superior performance in score prediction and uncertainty calibration. Our code is available at https://abrarmajeedi.github.io/rica2_aqa/
Full Reference Video Quality Assessment for Machine Learning-Based Video Codecs
Sep 02, 2023



Machine learning-based video codecs have made significant progress in the past few years. A critical area in the development of ML-based video codecs is an accurate evaluation metric that does not require an expensive and slow subjective test. We show that existing evaluation metrics that were designed and trained on DSP-based video codecs are not highly correlated to subjective opinion when used with ML video codecs due to the video artifacts being quite different between ML and video codecs. We provide a new dataset of ML video codec videos that have been accurately labeled for quality. We also propose a new full reference video quality assessment (FRVQA) model that achieves a Pearson Correlation Coefficient (PCC) of 0.99 and a Spearman's Rank Correlation Coefficient (SRCC) of 0.99 at the model level. We make the dataset and FRVQA model open source to help accelerate research in ML video codecs, and so that others can further improve the FRVQA model.
A Supervised Learning Methodology for Real-Time Disguised Face Recognition in the Wild
Sep 08, 2018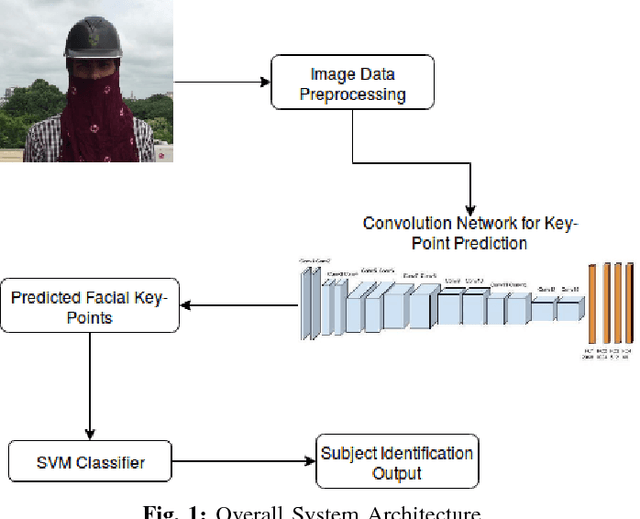



Facial recognition has always been a challeng- ing task for computer vision scientists and experts. Despite complexities arising due to variations in camera parameters, illumination and face orientations, significant progress has been made in the field with deep learning algorithms now competing with human-level accuracy. But in contrast to the recent advances in face recognition techniques, Disguised Facial Identification continues to be a tougher challenge in the field of computer vision. The modern day scenario, where security is of prime concern, regular face identification techniques do not perform as required when the faces are disguised, which calls for a different approach to handle situations where intruders have their faces masked. Along the same lines, we propose a deep learning architecture for disguised facial recognition (DFR). The algorithm put forward in this paper detects 20 facial key-points in the first stage, using a 14-layered convolutional neural network (CNN). These facial key-points are later utilized by a support vector machine (SVM) for classifying the disguised faces based on the euclidean distance ratios and angles between different facial key-points. This overall architecture imparts a basic intelligence to our system. Our key-point feature prediction accuracy is 65% while the classification rate is 72.4%. Moreover, the architecture works at 19 FPS, thereby performing in almost real-time. The efficiency of our approach is also compared with the state-of-the-art Disguised Facial Identification methods.