 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCABiNet: Efficient Context Aggregation Network for Low-Latency Semantic Segmentation
Nov 02, 2020
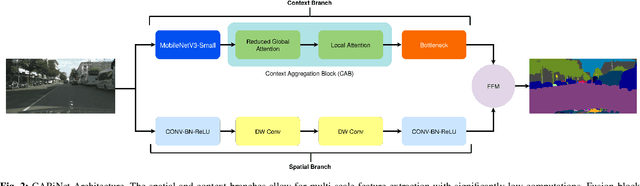
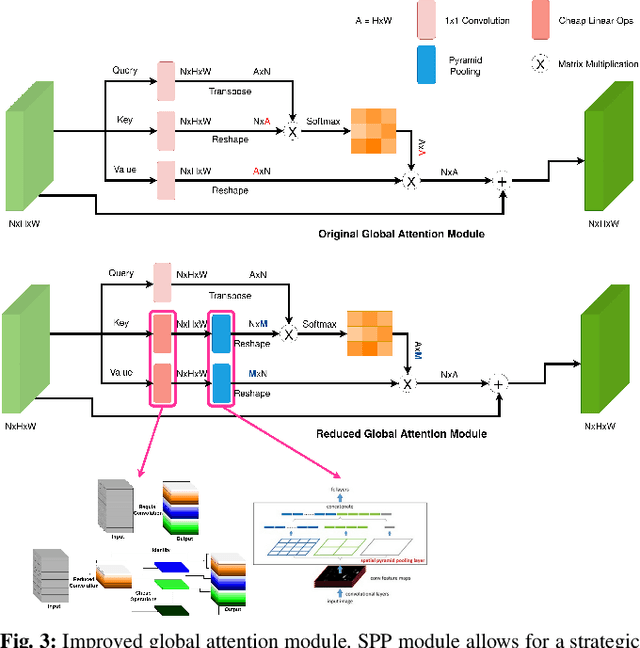
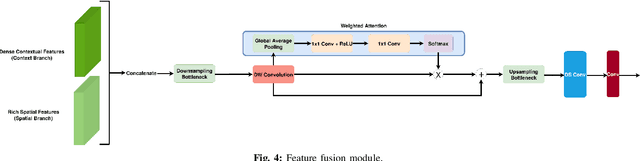
With the increasing demand of autonomous machines, pixel-wise semantic segmentation for visual scene understanding needs to be not only accurate but also efficient for any potential real-time applications. In this paper, we propose CABiNet (Context Aggregated Bi-lateral Network), a dual branch convolutional neural network (CNN), with significantly lower computational costs as compared to the state-of-the-art, while maintaining a competitive prediction accuracy. Building upon the existing multi-branch architectures for high-speed semantic segmentation, we design a cheap high resolution branch for effective spatial detailing and a context branch with light-weight versions of global aggregation and local distribution blocks, potent to capture both long-range and local contextual dependencies required for accurate semantic segmentation, with low computational overheads. Specifically, we achieve 76.6% and 75.9% mIOU on Cityscapes validation and test sets respectively, at 76 FPS on an NVIDIA RTX 2080Ti and 8 FPS on a Jetson Xavier NX. Codes and training models will be made publicly available.
A Supervised Learning Methodology for Real-Time Disguised Face Recognition in the Wild
Sep 08, 2018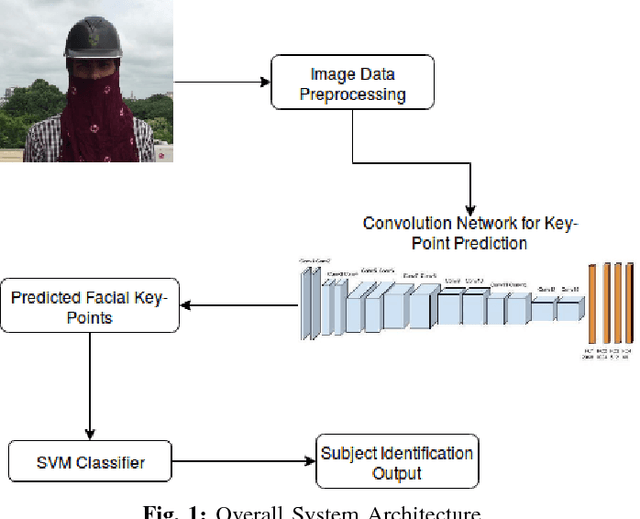



Facial recognition has always been a challeng- ing task for computer vision scientists and experts. Despite complexities arising due to variations in camera parameters, illumination and face orientations, significant progress has been made in the field with deep learning algorithms now competing with human-level accuracy. But in contrast to the recent advances in face recognition techniques, Disguised Facial Identification continues to be a tougher challenge in the field of computer vision. The modern day scenario, where security is of prime concern, regular face identification techniques do not perform as required when the faces are disguised, which calls for a different approach to handle situations where intruders have their faces masked. Along the same lines, we propose a deep learning architecture for disguised facial recognition (DFR). The algorithm put forward in this paper detects 20 facial key-points in the first stage, using a 14-layered convolutional neural network (CNN). These facial key-points are later utilized by a support vector machine (SVM) for classifying the disguised faces based on the euclidean distance ratios and angles between different facial key-points. This overall architecture imparts a basic intelligence to our system. Our key-point feature prediction accuracy is 65% while the classification rate is 72.4%. Moreover, the architecture works at 19 FPS, thereby performing in almost real-time. The efficiency of our approach is also compared with the state-of-the-art Disguised Facial Identification methods.
Learning to Navigate Autonomously in Outdoor Environments : MAVNet
Sep 02, 2018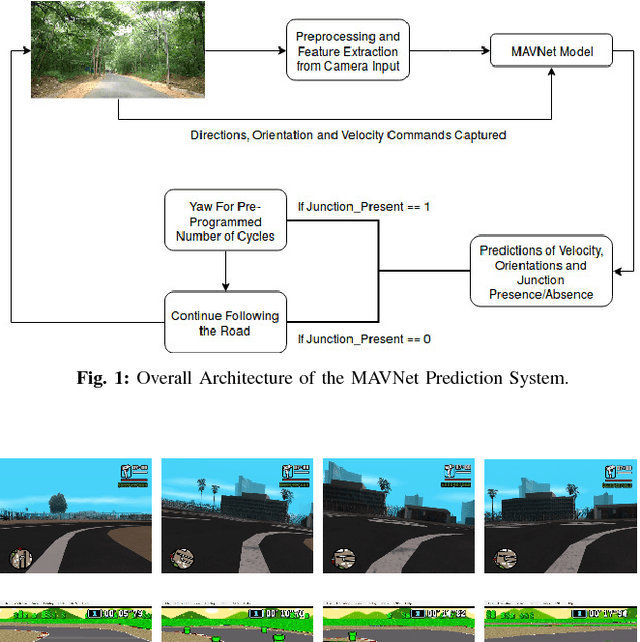
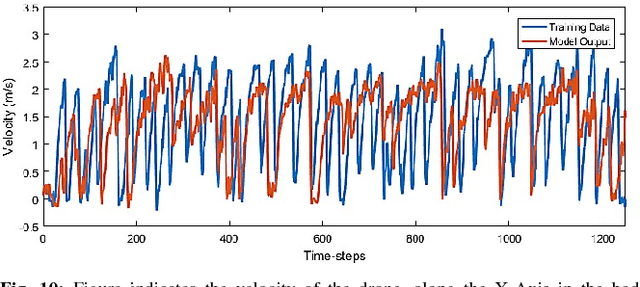
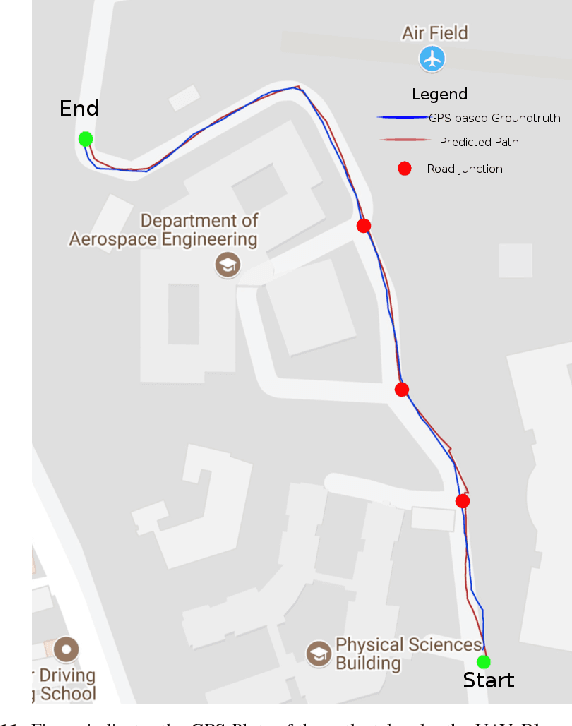

In the modern era of automation and robotics, autonomous vehicles are currently the focus of academic and industrial research. With the ever increasing number of unmanned aerial vehicles getting involved in activities in the civilian and commercial domain, there is an increased need for autonomy in these systems too. Due to guidelines set by the governments regarding the operation ceiling of civil drones, road-tracking based navigation is garnering interest . In an attempt to achieve the above mentioned tasks, we propose an imitation learning based, data-driven solution to UAV autonomy for navigating through city streets by learning to fly by imitating an expert pilot. Derived from the classic image classification algorithms, our classifier has been constructed in the form of a fast 39-layered Inception model, that evaluates the presence of roads using the tomographic reconstructions of the input frames. Based on the Inception-v3 architecture, our system performs better in terms of processing complexity and accuracy than many existing models for imitation learning. The data used for training the system has been captured from the drone, by flying it in and around urban and semi-urban streets, by experts having at least 6-8 years of flying experience. Permissions were taken from required authorities who made sure that minimal risk (to pedestrians) is involved in the data collection process. With the extensive amount of drone data that we collected, we have been able to navigate successfully through roads without crashing or overshooting, with an accuracy of 98.44%. The computational efficiency of MAVNet enables the drone to fly at high speeds of upto 6m/sec. We present the same results in this research and compare them with other state-of-the-art methods of vision and learning based navigation.
A Real-time Control Approach for Unmanned Aerial Vehicles using Brain-computer Interface
Sep 02, 2018

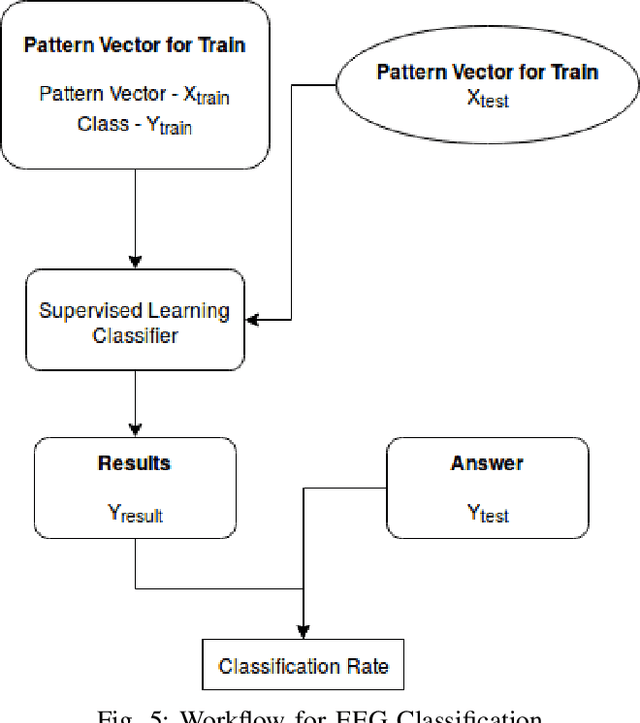
Brain-computer interfacing (BCI) is a technology that is almost four decades old and it was developed solely for the purpose of developing and enhancing the impact of neuroprosthetics. However, in the recent times, with the commercialization of non-invasive electroencephalogram (EEG) headsets, the technology has seen a wide variety of applications like home automation, wheelchair control, vehicle steering etc. One of the latest developed applications is the mind-controlled quadrotor unmanned aerial vehicle. These applications, how- ever, do not require a very high-speed response and give satisfactory results when standard classification methods like Support Vector Machine (SVM) and Multi-Layer Perceptron (MLPC). Issues are faced when there is a requirement for high-speed control in the case of fixed-wing unmanned aerial vehicles where such methods are rendered unreliable due to the low speed of classification. Such an application requires the system to classify data at high speeds in order to retain the con- trollability of the vehicle. This paper proposes a novel method of classification which uses a combination of Common Spatial Paradigm and Linear Discriminant Analysis that provides an improved classification accuracy in real time. A non-linear SVM based classification technique has also been discussed. Further, this paper discusses the implementation of the proposed method on a fixed-wing and VTOL unmanned aerial vehicles.
JuncNet: A Deep Neural Network for Road Junction Disambiguation for Autonomous Vehicles
Aug 31, 2018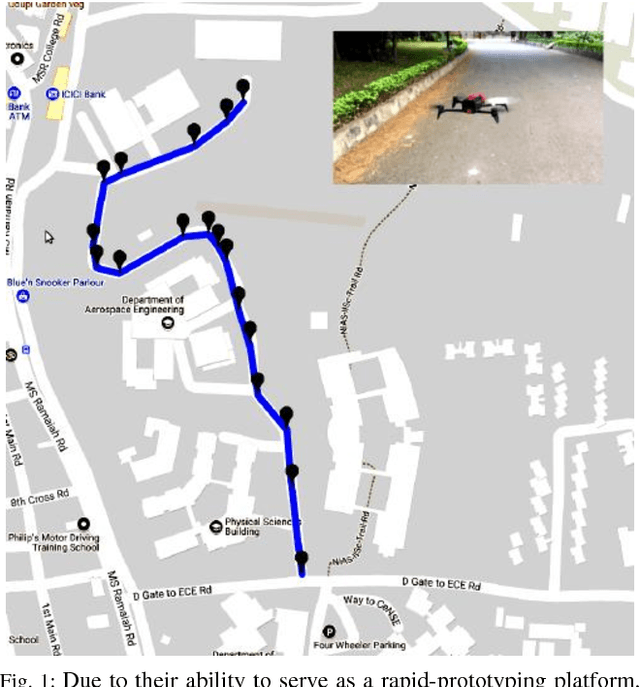

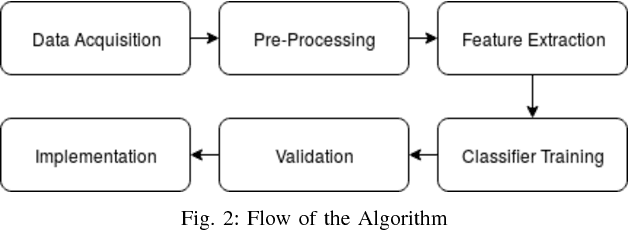

With a great amount of research going on in the field of autonomous vehicles or self-driving cars, there has been considerable progress in road detection and tracking algorithms. Most of these algorithms use GPS to handle road junctions and its subsequent decisions. However, there are places in the urban environment where it becomes difficult to get GPS fixes which render the junction decision handling erroneous or possibly risky. Vision-based junction detection, however, does not have such problems. This paper proposes a novel deep convolutional neural network architecture for disambiguation of junctions from roads with a high degree of accuracy. This network is benchmarked against other well known classifying network architectures like AlexNet and VGGnet. Further, we discuss a potential road navigation methodology which uses the proposed network model. We conclude by performing an experimental validation of the trained network and the navigational method on the roads of the Indian Institute of Science (IISc).