 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Multi-scale Attention Networks for Semantic Segmentation of Oblique UAV Imagery
Feb 05, 2021

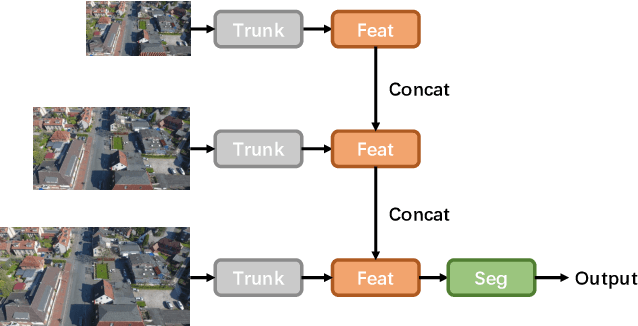

Semantic segmentation for aerial platforms has been one of the fundamental scene understanding task for the earth observation. Most of the semantic segmentation research focused on scenes captured in nadir view, in which objects have relatively smaller scale variation compared with scenes captured in oblique view. The huge scale variation of objects in oblique images limits the performance of deep neural networks (DNN) that process images in a single scale fashion. In order to tackle the scale variation issue, in this paper, we propose the novel bidirectional multi-scale attention networks, which fuse features from multiple scales bidirectionally for more adaptive and effective feature extraction. The experiments are conducted on the UAVid2020 dataset and have shown the effectiveness of our method. Our model achieved the state-of-the-art (SOTA) result with a mean intersection over union (mIoU) score of 70.80%.
CABiNet: Efficient Context Aggregation Network for Low-Latency Semantic Segmentation
Nov 02, 2020
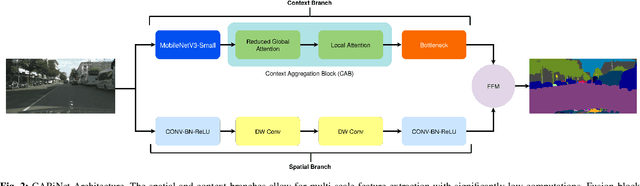
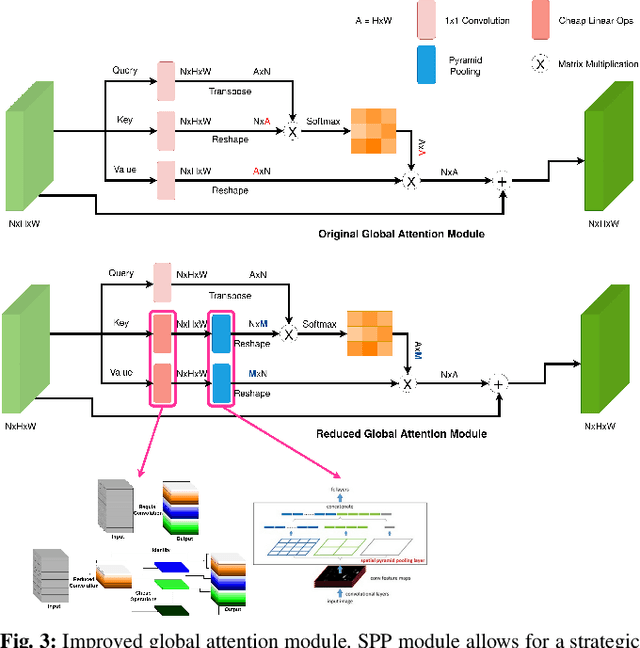
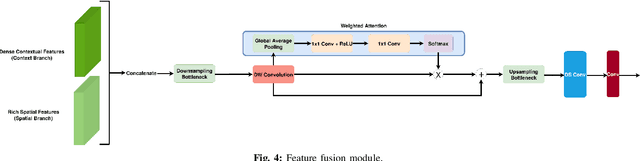
With the increasing demand of autonomous machines, pixel-wise semantic segmentation for visual scene understanding needs to be not only accurate but also efficient for any potential real-time applications. In this paper, we propose CABiNet (Context Aggregated Bi-lateral Network), a dual branch convolutional neural network (CNN), with significantly lower computational costs as compared to the state-of-the-art, while maintaining a competitive prediction accuracy. Building upon the existing multi-branch architectures for high-speed semantic segmentation, we design a cheap high resolution branch for effective spatial detailing and a context branch with light-weight versions of global aggregation and local distribution blocks, potent to capture both long-range and local contextual dependencies required for accurate semantic segmentation, with low computational overheads. Specifically, we achieve 76.6% and 75.9% mIOU on Cityscapes validation and test sets respectively, at 76 FPS on an NVIDIA RTX 2080Ti and 8 FPS on a Jetson Xavier NX. Codes and training models will be made publicly available.
Plug & Play Convolutional Regression Tracker for Video Object Detection
Mar 02, 2020
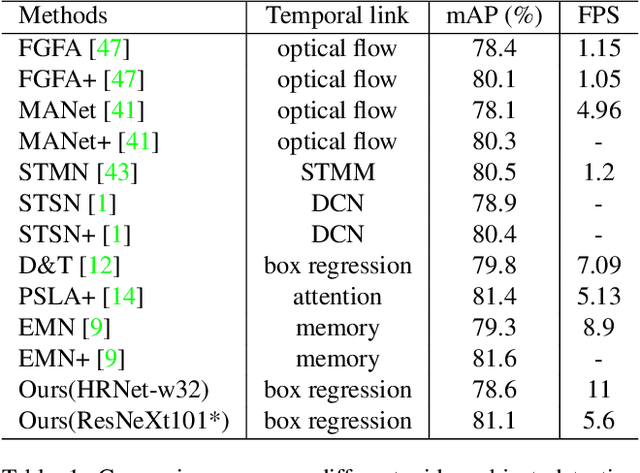
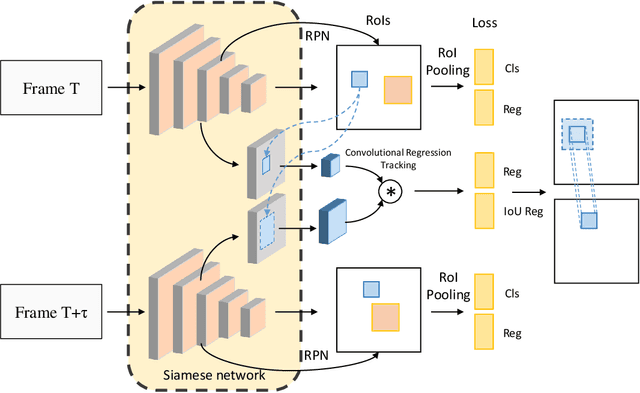

Video object detection targets to simultaneously localize the bounding boxes of the objects and identify their classes in a given video. One challenge for video object detection is to consistently detect all objects across the whole video. As the appearance of objects may deteriorate in some frames, features or detections from the other frames are commonly used to enhance the prediction. In this paper, we propose a Plug & Play scale-adaptive convolutional regression tracker for the video object detection task, which could be easily and compatibly implanted into the current state-of-the-art detection networks. As the tracker reuses the features from the detector, it is a very light-weighted increment to the detection network. The whole network performs at the speed close to a standard object detector. With our new video object detection pipeline design, image object detectors can be easily turned into efficient video object detectors without modifying any parameters. The performance is evaluated on the large-scale ImageNet VID dataset. Our Plug & Play design improves mAP score for the image detector by around 5% with only little speed drop.
LIP: Learning Instance Propagation for Video Object Segmentation
Sep 30, 2019

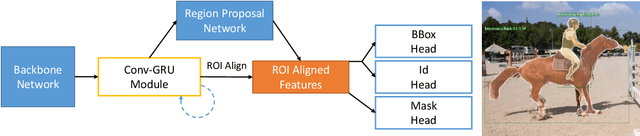
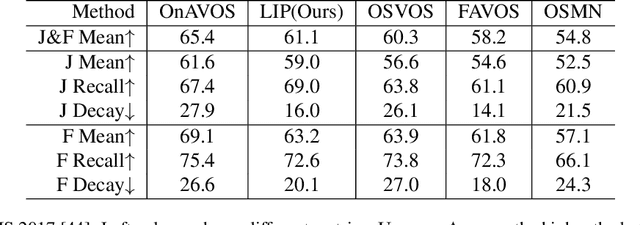
In recent years, the task of segmenting foreground objects from background in a video, i.e. video object segmentation (VOS), has received considerable attention. In this paper, we propose a single end-to-end trainable deep neural network, convolutional gated recurrent Mask-RCNN, for tackling the semi-supervised VOS task. We take advantage of both the instance segmentation network (Mask-RCNN) and the visual memory module (Conv-GRU) to tackle the VOS task. The instance segmentation network predicts masks for instances, while the visual memory module learns to selectively propagate information for multiple instances simultaneously, which handles the appearance change, the variation of scale and pose and the occlusions between objects. After offline and online training under purely instance segmentation losses, our approach is able to achieve satisfactory results without any post-processing or synthetic video data augmentation. Experimental results on DAVIS 2016 dataset and DAVIS 2017 dataset have demonstrated the effectiveness of our method for video object segmentation task.
The UAVid Dataset for Video Semantic Segmentation
Oct 24, 2018

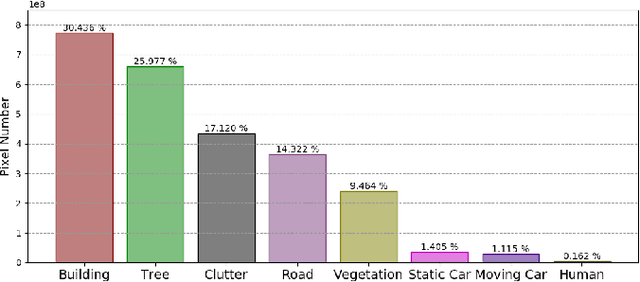
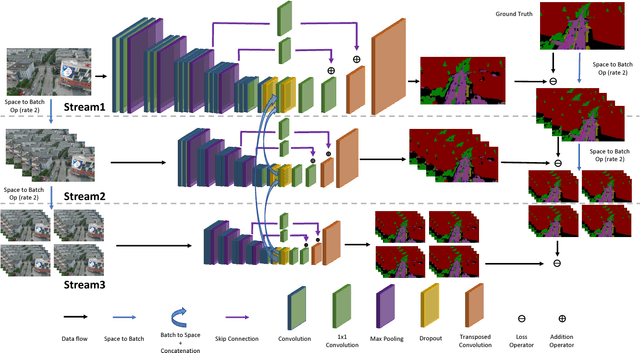
Video semantic segmentation has been one of the research focus in computer vision recently. It serves as a perception foundation for many fields such as robotics and autonomous driving. The fast development of semantic segmentation attributes enormously to the large scale datasets, especially for the deep learning related methods. Currently, there already exist several semantic segmentation datasets for complex urban scenes, such as the Cityscapes and CamVid datasets. They have been the standard datasets for comparison among semantic segmentation methods. In this paper, we introduce a new high resolution UAV video semantic segmentation dataset as complement, UAVid. Our UAV dataset consists of 30 video sequences capturing high resolution images. In total, 300 images have been densely labelled with 8 classes for urban scene understanding task. Our dataset brings out new challenges. We provide several deep learning baseline methods, among which the proposed novel Multi-Scale-Dilation net performs the best via multi-scale feature extraction. We have also explored the usability of sequence data by leveraging on CRF model in both spatial and temporal domain.