 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility of Indoor Frame-Wise Lidar Semantic Segmentation via Distillation from Visual Foundation Model
Apr 20, 2026Frame-wise semantic segmentation of indoor lidar scans is a fundamental step toward higher-level 3D scene understanding and mapping applications. However, acquiring frame-wise ground truth for training deep learning models is costly and time-consuming. This challenge is largely addressed, for imagery, by Visual Foundation Models (VFMs) which segment image frames. The same VFMs may be used to train a lidar scan frame segmentation model via a 2D-to-3D distillation pipeline. The success of such distillation has been shown for autonomous driving scenes, but not yet for indoor scenes. Here, we study the feasibility of repeating this success for indoor scenes, in a frame-wise distillation manner by coupling each lidar scan with a VFM-processed camera image. The evaluation is done using indoor SLAM datasets, where pseudo-labels are used for downstream evaluation. Also, a small manually annotated lidar dataset is provided for validation, as there are no other lidar frame-wise indoor datasets with semantics. Results show that the distilled model achieves up to 56% mIoU under pseudo-label evaluation and around 36% mIoU with real-label, demonstrating the feasibility of cross-modal distillation for indoor lidar semantic segmentation without manual annotations.
A Comparison of Multi-View Stereo Methods for Photogrammetric 3D Reconstruction: From Traditional to Learning-Based Approaches
Apr 11, 2026Photogrammetric 3D reconstruction has long relied on traditional Structure-from-Motion (SfM) and Multi-View Stereo (MVS) methods, which provide high accuracy but face challenges in speed and scalability. Recently, learning-based MVS methods have emerged, aiming for faster and more efficient reconstruction. This work presents a comparative evaluation between a representative traditional MVS pipeline (COLMAP) and state-of-the-art learning-based approaches, including geometry-guided methods (MVSNet, PatchmatchNet, MVSAnywhere, MVSFormer++) and end-to-end frameworks (Stereo4D, FoundationStereo, DUSt3R, MASt3R, Fast3R, VGGT). Two experiments were conducted on different aerial scenarios. The first experiment used the MARS-LVIG dataset, where ground-truth 3D reconstruction was provided by LiDAR point clouds. The second experiment used a public scene from the Pix4D official website, with ground truth generated by Pix4Dmapper. We evaluated accuracy, coverage, and runtime across all methods. Experimental results show that although COLMAP can provide reliable and geometrically consistent reconstruction results, it requires more computation time. In cases where traditional methods fail in image registration, learning-based approaches exhibit stronger feature-matching capability and greater robustness. Geometry-guided methods usually require careful dataset preparation and often depend on camera pose or depth priors generated by COLMAP. End-to-end methods such as DUSt3R and VGGT achieve competitive accuracy and reasonable coverage while offering substantially faster reconstruction. However, they exhibit relatively large residuals in 3D reconstruction, particularly in challenging scenarios.
Incremental Semantics-Aided Meshing from LiDAR-Inertial Odometry and RGB Direct Label Transfer
Apr 10, 2026Geometric high-fidelity mesh reconstruction from LiDAR-inertial scans remains challenging in large, complex indoor environments -- such as cultural buildings -- where point cloud sparsity, geometric drift, and fixed fusion parameters produce holes, over-smoothing, and spurious surfaces at structural boundaries. We propose a modular, incremental RGB+LiDAR pipeline that generates incremental semantics-aided high-quality meshes from indoor scans through scan frame-based direct label transfer. A vision foundation model labels each incoming RGB frame; labels are incrementally projected and fused onto a LiDAR-inertial odometry map; and an incremental semantics-aware Truncated Signed Distance Function (TSDF) fusion step produces the final mesh via marching cubes. This frame-level fusion strategy preserves the geometric fidelity of LiDAR while leveraging rich visual semantics to resolve geometric ambiguities at reconstruction boundaries caused by LiDAR point-cloud sparsity and geometric drift. We demonstrate that semantic guidance improves geometric reconstruction quality; quantitative evaluation is therefore performed using geometric metrics on the Oxford Spires dataset, while results from the NTU VIRAL dataset are analyzed qualitatively. The proposed method outperforms state-of-the-art geometric baselines ImMesh and Voxblox, demonstrating the benefit of semantics-aided fusion for geometric mesh quality. The resulting semantically labelled meshes are of value when reconstructing Universal Scene Description (USD) assets, offering a path from indoor LiDAR scanning to XR and digital modeling.
M2H-MX: Multi-Task Dense Visual Perception for Real-Time Monocular Spatial Understanding
Mar 31, 2026Monocular cameras are attractive for robotic perception due to their low cost and ease of deployment, yet achieving reliable real-time spatial understanding from a single image stream remains challenging. While recent multi-task dense prediction models have improved per-pixel depth and semantic estimation, translating these advances into stable monocular mapping systems is still non-trivial. This paper presents M2H-MX, a real-time multi-task perception model for monocular spatial understanding. The model preserves multi-scale feature representations while introducing register-gated global context and controlled cross-task interaction in a lightweight decoder, enabling depth and semantic predictions to reinforce each other under strict latency constraints. Its outputs integrate directly into an unmodified monocular SLAM pipeline through a compact perception-to-mapping interface. We evaluate both dense prediction accuracy and in-the-loop system performance. On NYUDv2, M2H-MX-L achieves state-of-the-art results, improving semantic mIoU by 6.6% and reducing depth RMSE by 9.4% over representative multi-task baselines. When deployed in a real-time monocular mapping system on ScanNet, M2H-MX reduces average trajectory error by 60.7% compared to a strong monocular SLAM baseline while producing cleaner metric-semantic maps. These results demonstrate that modern multi-task dense prediction can be reliably deployed for real-time monocular spatial perception in robotic systems.
ACPV-Net: All-Class Polygonal Vectorization for Seamless Vector Map Generation from Aerial Imagery
Mar 17, 2026We tackle the problem of generating a complete vector map representation from aerial imagery in a single run: producing polygons for all land-cover classes with shared boundaries and without gaps or overlaps. Existing polygonization methods are typically class-specific; extending them to multiple classes via per-class runs commonly leads to topological inconsistencies, such as duplicated edges, gaps, and overlaps. We formalize this new task as All-Class Polygonal Vectorization (ACPV) and release the first public benchmark, Deventer-512, with standardized metrics jointly evaluating semantic fidelity, geometric accuracy, vertex efficiency, per-class topological fidelity and global topological consistency. To realize ACPV, we propose ACPV-Net, a unified framework introducing a novel Semantically Supervised Conditioning (SSC) mechanism coupling semantic perception with geometric primitive generation, along with a topological reconstruction that enforces shared-edge consistency by design. While enforcing such strict topological constraints, ACPV-Net surpasses all class-specific baselines in polygon quality across classes on Deventer-512. It also applies to single-class polygonal vectorization without any architectural modification, achieving the best-reported results on WHU-Building. Data, code, and models will be released at: https://github.com/HeinzJiao/ACPV-Net.
LDPoly: Latent Diffusion for Polygonal Road Outline Extraction in Large-Scale Topographic Mapping
Apr 29, 2025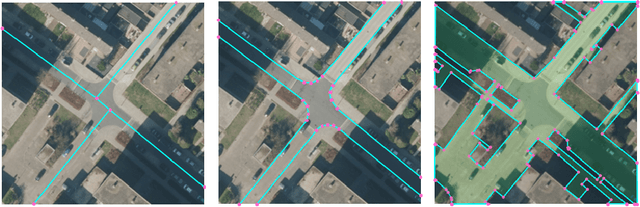



Polygonal road outline extraction from high-resolution aerial images is an important task in large-scale topographic mapping, where roads are represented as vectorized polygons, capturing essential geometric features with minimal vertex redundancy. Despite its importance, no existing method has been explicitly designed for this task. While polygonal building outline extraction has been extensively studied, the unique characteristics of roads, such as branching structures and topological connectivity, pose challenges to these methods. To address this gap, we introduce LDPoly, the first dedicated framework for extracting polygonal road outlines from high-resolution aerial images. Our method leverages a novel Dual-Latent Diffusion Model with a Channel-Embedded Fusion Module, enabling the model to simultaneously generate road masks and vertex heatmaps. A tailored polygonization method is then applied to obtain accurate vectorized road polygons with minimal vertex redundancy. We evaluate LDPoly on a new benchmark dataset, Map2ImLas, which contains detailed polygonal annotations for various topographic objects in several Dutch regions. Our experiments include both in-region and cross-region evaluations, with the latter designed to assess the model's generalization performance on unseen regions. Quantitative and qualitative results demonstrate that LDPoly outperforms state-of-the-art polygon extraction methods across various metrics, including pixel-level coverage, vertex efficiency, polygon regularity, and road connectivity. We also design two new metrics to assess polygon simplicity and boundary smoothness. Moreover, this work represents the first application of diffusion models for extracting precise vectorized object outlines without redundant vertices from remote-sensing imagery, paving the way for future advancements in this field.
Scale-wise Bidirectional Alignment Network for Referring Remote Sensing Image Segmentation
Jan 06, 2025The goal of referring remote sensing image segmentation (RRSIS) is to extract specific pixel-level regions within an aerial image via a natural language expression. Recent advancements, particularly Transformer-based fusion designs, have demonstrated remarkable progress in this domain. However, existing methods primarily focus on refining visual features using language-aware guidance during the cross-modal fusion stage, neglecting the complementary vision-to-language flow. This limitation often leads to irrelevant or suboptimal representations. In addition, the diverse spatial scales of ground objects in aerial images pose significant challenges to the visual perception capabilities of existing models when conditioned on textual inputs. In this paper, we propose an innovative framework called Scale-wise Bidirectional Alignment Network (SBANet) to address these challenges for RRSIS. Specifically, we design a Bidirectional Alignment Module (BAM) with learnable query tokens to selectively and effectively represent visual and linguistic features, emphasizing regions associated with key tokens. BAM is further enhanced with a dynamic feature selection block, designed to provide both macro- and micro-level visual features, preserving global context and local details to facilitate more effective cross-modal interaction. Furthermore, SBANet incorporates a text-conditioned channel and spatial aggregator to bridge the gap between the encoder and decoder, enhancing cross-scale information exchange in complex aerial scenarios. Extensive experiments demonstrate that our proposed method achieves superior performance in comparison to previous state-of-the-art methods on the RRSIS-D and RefSegRS datasets, both quantitatively and qualitatively. The code will be released after publication.
PolyR-CNN: R-CNN for end-to-end polygonal building outline extraction
Jul 20, 2024



Polygonal building outline extraction has been a research focus in recent years. Most existing methods have addressed this challenging task by decomposing it into several subtasks and employing carefully designed architectures. Despite their accuracy, such pipelines often introduce inefficiencies during training and inference. This paper presents an end-to-end framework, denoted as PolyR-CNN, which offers an efficient and fully integrated approach to predict vectorized building polygons and bounding boxes directly from remotely sensed images. Notably, PolyR-CNN leverages solely the features of the Region of Interest (RoI) for the prediction, thereby mitigating the necessity for complex designs. Furthermore, we propose a novel scheme with PolyR-CNN to extract detailed outline information from polygon vertex coordinates, termed vertex proposal feature, to guide the RoI features to predict more regular buildings. PolyR-CNN demonstrates the capacity to deal with buildings with holes through a simple post-processing method on the Inria dataset. Comprehensive experiments conducted on the CrowdAI dataset show that PolyR-CNN achieves competitive accuracy compared to state-of-the-art methods while significantly improving computational efficiency, i.e., achieving 79.2 Average Precision (AP), exhibiting a 15.9 AP gain and operating 2.5 times faster and four times lighter than the well-established end-to-end method PolyWorld. Replacing the backbone with a simple ResNet-50, PolyR-CNN maintains a 71.1 AP while running four times faster than PolyWorld.
RoIPoly: Vectorized Building Outline Extraction Using Vertex and Logit Embeddings
Jul 20, 2024Polygonal building outlines are crucial for geographic and cartographic applications. The existing approaches for outline extraction from aerial or satellite imagery are typically decomposed into subtasks, e.g., building masking and vectorization, or treat this task as a sequence-to-sequence prediction of ordered vertices. The former lacks efficiency, and the latter often generates redundant vertices, both resulting in suboptimal performance. To handle these issues, we propose a novel Region-of-Interest (RoI) query-based approach called RoIPoly. Specifically, we formulate each vertex as a query and constrain the query attention on the most relevant regions of a potential building, yielding reduced computational overhead and more efficient vertex level interaction. Moreover, we introduce a novel learnable logit embedding to facilitate vertex classification on the attention map; thus, no post-processing is needed for redundant vertex removal. We evaluated our method on the vectorized building outline extraction dataset CrowdAI and the 2D floorplan reconstruction dataset Structured3D. On the CrowdAI dataset, RoIPoly with a ResNet50 backbone outperforms existing methods with the same or better backbones on most MS-COCO metrics, especially on small buildings, and achieves competitive results in polygon quality and vertex redundancy without any post-processing. On the Structured3D dataset, our method achieves the second-best performance on most metrics among existing methods dedicated to 2D floorplan reconstruction, demonstrating our cross-domain generalization capability. The code will be released upon acceptance of this paper.
Learning from Exemplars for Interactive Image Segmentation
Jun 17, 2024Interactive image segmentation enables users to interact minimally with a machine, facilitating the gradual refinement of the segmentation mask for a target of interest. Previous studies have demonstrated impressive performance in extracting a single target mask through interactive segmentation. However, the information cues of previously interacted objects have been overlooked in the existing methods, which can be further explored to speed up interactive segmentation for multiple targets in the same category. To this end, we introduce novel interactive segmentation frameworks for both a single object and multiple objects in the same category. Specifically, our model leverages transformer backbones to extract interaction-focused visual features from the image and the interactions to obtain a satisfactory mask of a target as an exemplar. For multiple objects, we propose an exemplar-informed module to enhance the learning of similarities among the objects of the target category. To combine attended features from different modules, we incorporate cross-attention blocks followed by a feature fusion module. Experiments conducted on mainstream benchmarks demonstrate that our models achieve superior performance compared to previous methods. Particularly, our model reduces users' labor by around 15\%, requiring two fewer clicks to achieve target IoUs 85\% and 90\%. The results highlight our models' potential as a flexible and practical annotation tool. The source code will be released after publication.