 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Latent Diagnostic Trajectory Learning for Sequential Clinical Diagnosis
Apr 06, 2026Clinical diagnosis requires sequential evidence acquisition under uncertainty. However, most Large Language Model (LLM) based diagnostic systems assume fully observed patient information and therefore do not explicitly model how clinical evidence should be sequentially acquired over time. Even when diagnosis is formulated as a sequential decision process, it is still challenging to learn effective diagnostic trajectories. This is because the space of possible evidence-acquisition paths is relatively large, while clinical datasets rarely provide explicit supervision information for desirable diagnostic paths. To this end, we formulate sequential diagnosis as a Latent Diagnostic Trajectory Learning (LDTL) framework based on a planning LLM agent and a diagnostic LLM agent. For the diagnostic LLM agent, diagnostic action sequences are treated as latent paths and we introduce a posterior distribution that prioritizes trajectories providing more diagnostic information. The planning LLM agent is then trained to follow this distribution, encouraging coherent diagnostic trajectories that progressively reduce uncertainty. Experiments on the MIMIC-CDM benchmark demonstrate that our proposed LDTL framework outperforms existing baselines in diagnostic accuracy under a sequential clinical diagnosis setting, while requiring fewer diagnostic tests. Furthermore, ablation studies highlight the critical role of trajectory-level posterior alignment in achieving these improvements.
DiscussLLM: Teaching Large Language Models When to Speak
Aug 25, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in understanding and generating human-like text, yet they largely operate as reactive agents, responding only when directly prompted. This passivity creates an "awareness gap," limiting their potential as truly collaborative partners in dynamic human discussions. We introduce $\textit{DiscussLLM}$, a framework designed to bridge this gap by training models to proactively decide not just $\textit{what}$ to say, but critically, $\textit{when}$ to speak. Our primary contribution is a scalable two-stage data generation pipeline that synthesizes a large-scale dataset of realistic multi-turn human discussions. Each discussion is annotated with one of five intervention types (e.g., Factual Correction, Concept Definition) and contains an explicit conversational trigger where an AI intervention adds value. By training models to predict a special silent token when no intervention is needed, they learn to remain quiet until a helpful contribution can be made. We explore two architectural baselines: an integrated end-to-end model and a decoupled classifier-generator system optimized for low-latency inference. We evaluate these models on their ability to accurately time interventions and generate helpful responses, paving the way for more situationally aware and proactive conversational AI.
PPDiff: Diffusing in Hybrid Sequence-Structure Space for Protein-Protein Complex Design
Jun 13, 2025Designing protein-binding proteins with high affinity is critical in biomedical research and biotechnology. Despite recent advancements targeting specific proteins, the ability to create high-affinity binders for arbitrary protein targets on demand, without extensive rounds of wet-lab testing, remains a significant challenge. Here, we introduce PPDiff, a diffusion model to jointly design the sequence and structure of binders for arbitrary protein targets in a non-autoregressive manner. PPDiffbuilds upon our developed Sequence Structure Interleaving Network with Causal attention layers (SSINC), which integrates interleaved self-attention layers to capture global amino acid correlations, k-nearest neighbor (kNN) equivariant graph layers to model local interactions in three-dimensional (3D) space, and causal attention layers to simplify the intricate interdependencies within the protein sequence. To assess PPDiff, we curate PPBench, a general protein-protein complex dataset comprising 706,360 complexes from the Protein Data Bank (PDB). The model is pretrained on PPBenchand finetuned on two real-world applications: target-protein mini-binder complex design and antigen-antibody complex design. PPDiffconsistently surpasses baseline methods, achieving success rates of 50.00%, 23.16%, and 16.89% for the pretraining task and the two downstream applications, respectively.
Solving Inverse Problems via Diffusion-Based Priors: An Approximation-Free Ensemble Sampling Approach
Jun 05, 2025Diffusion models (DMs) have proven to be effective in modeling high-dimensional distributions, leading to their widespread adoption for representing complex priors in Bayesian inverse problems (BIPs). However, current DM-based posterior sampling methods proposed for solving common BIPs rely on heuristic approximations to the generative process. To exploit the generative capability of DMs and avoid the usage of such approximations, we propose an ensemble-based algorithm that performs posterior sampling without the use of heuristic approximations. Our algorithm is motivated by existing works that combine DM-based methods with the sequential Monte Carlo (SMC) method. By examining how the prior evolves through the diffusion process encoded by the pre-trained score function, we derive a modified partial differential equation (PDE) governing the evolution of the corresponding posterior distribution. This PDE includes a modified diffusion term and a reweighting term, which can be simulated via stochastic weighted particle methods. Theoretically, we prove that the error between the true posterior distribution can be bounded in terms of the training error of the pre-trained score function and the number of particles in the ensemble. Empirically, we validate our algorithm on several inverse problems in imaging to show that our method gives more accurate reconstructions compared to existing DM-based methods.
Reducing Hallucinations of Medical Multimodal Large Language Models with Visual Retrieval-Augmented Generation
Feb 20, 2025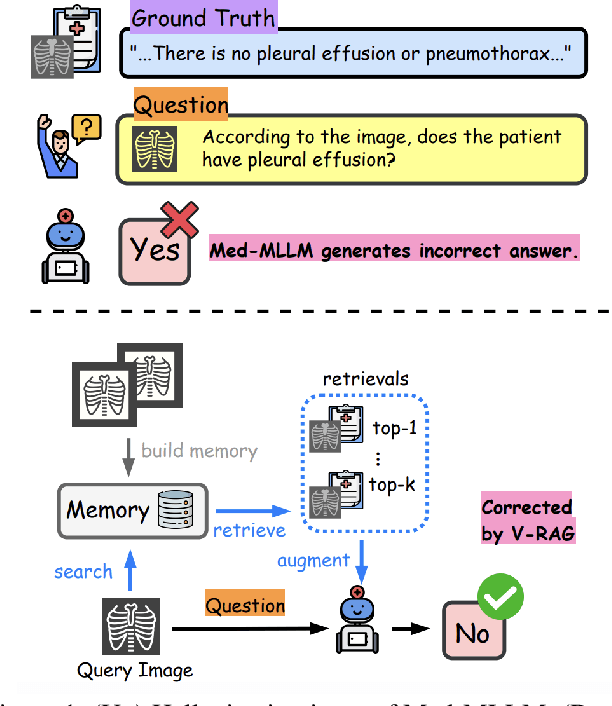
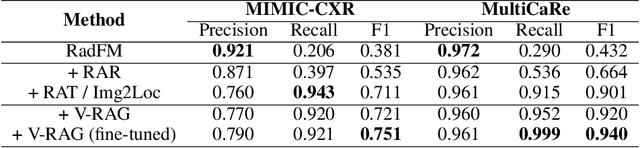
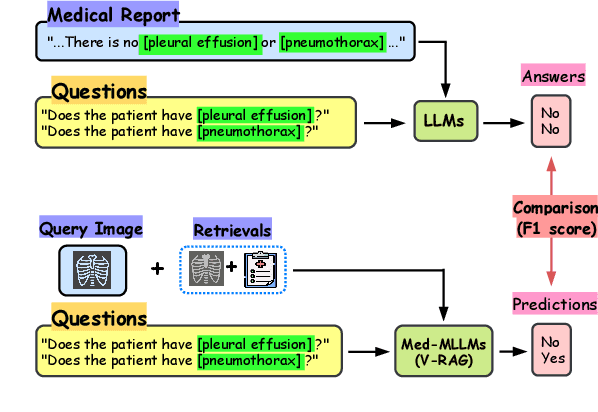
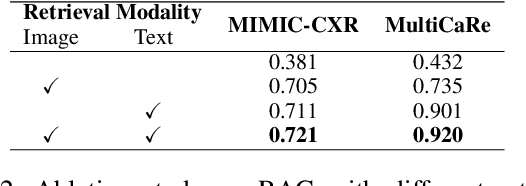
Multimodal Large Language Models (MLLMs) have shown impressive performance in vision and text tasks. However, hallucination remains a major challenge, especially in fields like healthcare where details are critical. In this work, we show how MLLMs may be enhanced to support Visual RAG (V-RAG), a retrieval-augmented generation framework that incorporates both text and visual data from retrieved images. On the MIMIC-CXR chest X-ray report generation and Multicare medical image caption generation datasets, we show that Visual RAG improves the accuracy of entity probing, which asks whether a medical entities is grounded by an image. We show that the improvements extend both to frequent and rare entities, the latter of which may have less positive training data. Downstream, we apply V-RAG with entity probing to correct hallucinations and generate more clinically accurate X-ray reports, obtaining a higher RadGraph-F1 score.
Learning Disentangled Equivariant Representation for Explicitly Controllable 3D Molecule Generation
Dec 19, 2024We consider the conditional generation of 3D drug-like molecules with \textit{explicit control} over molecular properties such as drug-like properties (e.g., Quantitative Estimate of Druglikeness or Synthetic Accessibility score) and effectively binding to specific protein sites. To tackle this problem, we propose an E(3)-equivariant Wasserstein autoencoder and factorize the latent space of our generative model into two disentangled aspects: molecular properties and the remaining structural context of 3D molecules. Our model ensures explicit control over these molecular attributes while maintaining equivariance of coordinate representation and invariance of data likelihood. Furthermore, we introduce a novel alignment-based coordinate loss to adapt equivariant networks for auto-regressive de-novo 3D molecule generation from scratch. Extensive experiments validate our model's effectiveness on property-guided and context-guided molecule generation, both for de-novo 3D molecule design and structure-based drug discovery against protein targets.
Exploiting VLM Localizability and Semantics for Open Vocabulary Action Detection
Nov 17, 2024



Action detection aims to detect (recognize and localize) human actions spatially and temporally in videos. Existing approaches focus on the closed-set setting where an action detector is trained and tested on videos from a fixed set of action categories. However, this constrained setting is not viable in an open world where test videos inevitably come beyond the trained action categories. In this paper, we address the practical yet challenging Open-Vocabulary Action Detection (OVAD) problem. It aims to detect any action in test videos while training a model on a fixed set of action categories. To achieve such an open-vocabulary capability, we propose a novel method OpenMixer that exploits the inherent semantics and localizability of large vision-language models (VLM) within the family of query-based detection transformers (DETR). Specifically, the OpenMixer is developed by spatial and temporal OpenMixer blocks (S-OMB and T-OMB), and a dynamically fused alignment (DFA) module. The three components collectively enjoy the merits of strong generalization from pre-trained VLMs and end-to-end learning from DETR design. Moreover, we established OVAD benchmarks under various settings, and the experimental results show that the OpenMixer performs the best over baselines for detecting seen and unseen actions. We release the codes, models, and dataset splits at https://github.com/Cogito2012/OpenMixer.
Variational methods for Learning Multilevel Genetic Algorithms using the Kantorovich Monad
Nov 14, 2024



Levels of selection and multilevel evolutionary processes are essential concepts in evolutionary theory, and yet there is a lack of common mathematical models for these core ideas. Here, we propose a unified mathematical framework for formulating and optimizing multilevel evolutionary processes and genetic algorithms over arbitrarily many levels based on concepts from category theory and population genetics. We formulate a multilevel version of the Wright-Fisher process using this approach, and we show that this model can be analyzed to clarify key features of multilevel selection. Particularly, we derive an extended multilevel probabilistic version of Price's Equation via the Kantorovich Monad, and we use this to characterize regimes of parameter space within which selection acts antagonistically or cooperatively across levels. Finally, we show how our framework can provide a unified setting for learning genetic algorithms (GAs), and we show how we can use a Variational Optimization and a multi-level analogue of coalescent analysis to fit multilevel GAs to simulated data.
Exploring the Role of Reasoning Structures for Constructing Proofs in Multi-Step Natural Language Reasoning with Large Language Models
Oct 11, 2024



When performing complex multi-step reasoning tasks, the ability of Large Language Models (LLMs) to derive structured intermediate proof steps is important for ensuring that the models truly perform the desired reasoning and for improving models' explainability. This paper is centred around a focused study: whether the current state-of-the-art generalist LLMs can leverage the structures in a few examples to better construct the proof structures with \textit{in-context learning}. Our study specifically focuses on structure-aware demonstration and structure-aware pruning. We demonstrate that they both help improve performance. A detailed analysis is provided to help understand the results.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.