 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Sign Language Models: Toward 3D American Sign Language Translation
Nov 11, 2025We present Large Sign Language Models (LSLM), a novel framework for translating 3D American Sign Language (ASL) by leveraging Large Language Models (LLMs) as the backbone, which can benefit hearing-impaired individuals' virtual communication. Unlike existing sign language recognition methods that rely on 2D video, our approach directly utilizes 3D sign language data to capture rich spatial, gestural, and depth information in 3D scenes. This enables more accurate and resilient translation, enhancing digital communication accessibility for the hearing-impaired community. Beyond the task of ASL translation, our work explores the integration of complex, embodied multimodal languages into the processing capabilities of LLMs, moving beyond purely text-based inputs to broaden their understanding of human communication. We investigate both direct translation from 3D gesture features to text and an instruction-guided setting where translations can be modulated by external prompts, offering greater flexibility. This work provides a foundational step toward inclusive, multimodal intelligent systems capable of understanding diverse forms of language.
Rate-My-LoRA: Efficient and Adaptive Federated Model Tuning for Cardiac MRI Segmentation
Jan 06, 2025Cardiovascular disease (CVD) and cardiac dyssynchrony are major public health problems in the United States. Precise cardiac image segmentation is crucial for extracting quantitative measures that help categorize cardiac dyssynchrony. However, achieving high accuracy often depends on centralizing large datasets from different hospitals, which can be challenging due to privacy concerns. To solve this problem, Federated Learning (FL) is proposed to enable decentralized model training on such data without exchanging sensitive information. However, bandwidth limitations and data heterogeneity remain as significant challenges in conventional FL algorithms. In this paper, we propose a novel efficient and adaptive federate learning method for cardiac segmentation that improves model performance while reducing the bandwidth requirement. Our method leverages the low-rank adaptation (LoRA) to regularize model weight update and reduce communication overhead. We also propose a \mymethod{} aggregation technique to address data heterogeneity among clients. This technique adaptively penalizes the aggregated weights from different clients by comparing the validation accuracy in each client, allowing better generalization performance and fast local adaptation. In-client and cross-client evaluations on public cardiac MR datasets demonstrate the superiority of our method over other LoRA-based federate learning approaches.
DICE: Discrete Inversion Enabling Controllable Editing for Multinomial Diffusion and Masked Generative Models
Oct 10, 2024Discrete diffusion models have achieved success in tasks like image generation and masked language modeling but face limitations in controlled content editing. We introduce DICE (Discrete Inversion for Controllable Editing), the first approach to enable precise inversion for discrete diffusion models, including multinomial diffusion and masked generative models. By recording noise sequences and masking patterns during the reverse diffusion process, DICE enables accurate reconstruction and flexible editing of discrete data without the need for predefined masks or attention manipulation. We demonstrate the effectiveness of DICE across both image and text domains, evaluating it on models such as VQ-Diffusion, Paella, and RoBERTa. Our results show that DICE preserves high data fidelity while enhancing editing capabilities, offering new opportunities for fine-grained content manipulation in discrete spaces. For project webpage, see https://hexiaoxiao-cs.github.io/DICE/.
DMCVR: Morphology-Guided Diffusion Model for 3D Cardiac Volume Reconstruction
Aug 18, 2023

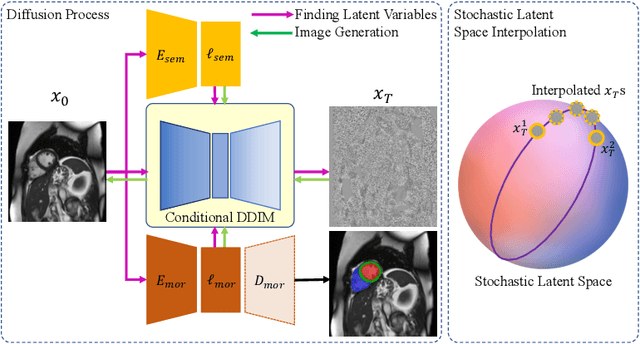
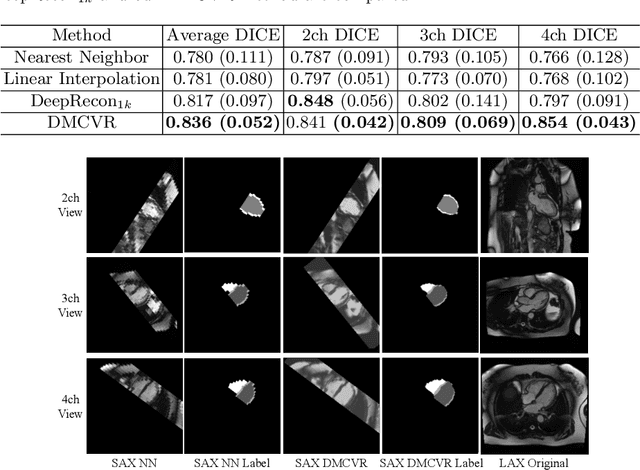
Accurate 3D cardiac reconstruction from cine magnetic resonance imaging (cMRI) is crucial for improved cardiovascular disease diagnosis and understanding of the heart's motion. However, current cardiac MRI-based reconstruction technology used in clinical settings is 2D with limited through-plane resolution, resulting in low-quality reconstructed cardiac volumes. To better reconstruct 3D cardiac volumes from sparse 2D image stacks, we propose a morphology-guided diffusion model for 3D cardiac volume reconstruction, DMCVR, that synthesizes high-resolution 2D images and corresponding 3D reconstructed volumes. Our method outperforms previous approaches by conditioning the cardiac morphology on the generative model, eliminating the time-consuming iterative optimization process of the latent code, and improving generation quality. The learned latent spaces provide global semantics, local cardiac morphology and details of each 2D cMRI slice with highly interpretable value to reconstruct 3D cardiac shape. Our experiments show that DMCVR is highly effective in several aspects, such as 2D generation and 3D reconstruction performance. With DMCVR, we can produce high-resolution 3D cardiac MRI reconstructions, surpassing current techniques. Our proposed framework has great potential for improving the accuracy of cardiac disease diagnosis and treatment planning. Code can be accessed at https://github.com/hexiaoxiao-cs/DMCVR.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Apr 18, 2023Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Recursive 3D Segmentation of Shoulder Joint with Coarse-scanned MR Image
Mar 13, 2022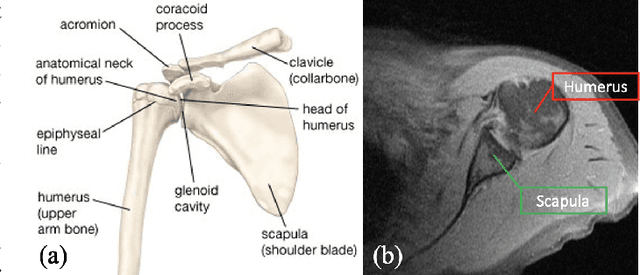
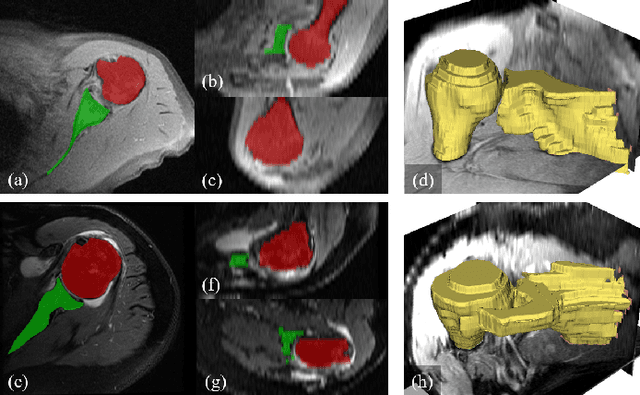
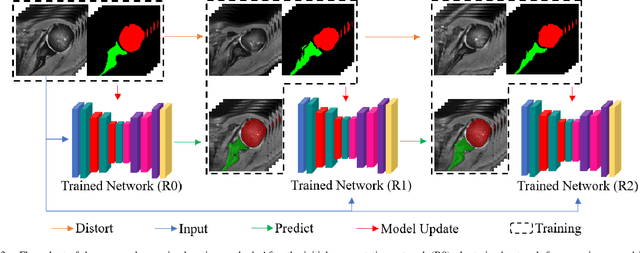
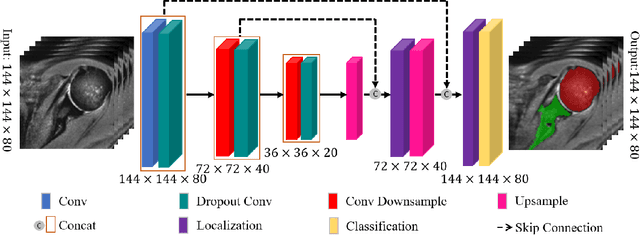
For diagnosis of shoulder illness, it is essential to look at the morphology deviation of scapula and humerus from the medical images that are acquired from Magnetic Resonance (MR) imaging. However, taking high-resolution MR images is time-consuming and costly because the reduction of the physical distance between image slices causes prolonged scanning time. Moreover, due to the lack of training images, images from various sources must be utilized, which creates the issue of high variance across the dataset. Also, there are human errors among the images due to the fact that it is hard to take the spatial relationship into consideration when labeling the 3D image in low resolution. In order to combat all obstacles stated above, we develop a fully automated algorithm for segmenting the humerus and scapula bone from coarsely scanned and low-resolution MR images and a recursive learning framework that iterative utilize the generated labels for reducing the errors among segmentations and increase our dataset set for training the next round network. In this study, 50 MR images are collected from several institutions and divided into five mutually exclusive sets for carrying five-fold cross-validation. Contours that are generated by the proposed method demonstrated a high level of accuracy when compared with ground truth and the traditional method. The proposed neural network and the recursive learning scheme improve the overall quality of the segmentation on humerus and scapula on the low-resolution dataset and reduced incorrect segmentation in the ground truth, which could have a positive impact on finding the cause of shoulder pain and patient's early relief.
Fedlearn-Algo: A flexible open-source privacy-preserving machine learning platform
Jul 30, 2021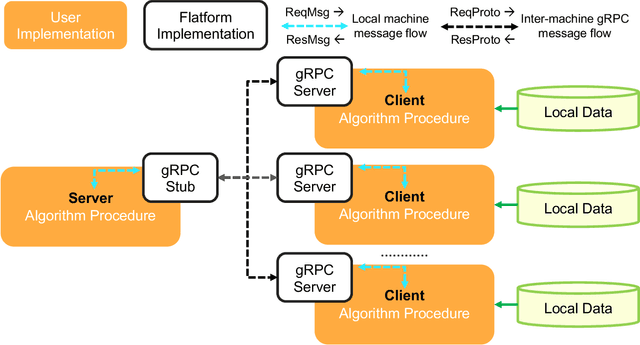
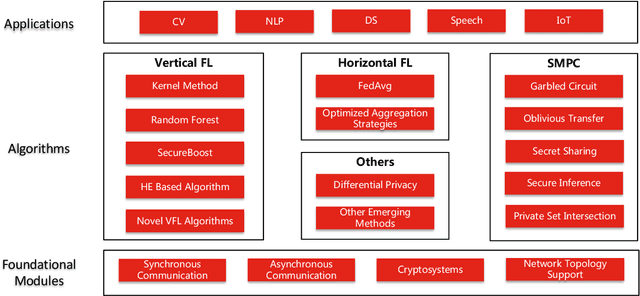
In this paper, we present Fedlearn-Algo, an open-source privacy preserving machine learning platform. We use this platform to demonstrate our research and development results on privacy preserving machine learning algorithms. As the first batch of novel FL algorithm examples, we release vertical federated kernel binary classification model and vertical federated random forest model. They have been tested to be more efficient than existing vertical federated learning models in our practice. Besides the novel FL algorithm examples, we also release a machine communication module. The uniform data transfer interface supports transferring widely used data formats between machines. We will maintain this platform by adding more functional modules and algorithm examples. The code is available at https://github.com/fedlearnAI/fedlearn-algo.
Data Augmentation for Object Detection via Differentiable Neural Rendering
Apr 05, 2021



It is challenging to train a robust object detector under the supervised learning setting when the annotated data are scarce. Thus, previous approaches tackling this problem are in two categories: semi-supervised learning models that interpolate labeled data from unlabeled data, and self-supervised learning approaches that exploit signals within unlabeled data via pretext tasks. To seamlessly integrate and enhance existing supervised object detection methods, in this work, we focus on addressing the data scarcity problem from a fundamental viewpoint without changing the supervised learning paradigm. We propose a new offline data augmentation method for object detection, which semantically interpolates the training data with novel views. Specifically, our new system generates controllable views of training images based on differentiable neural rendering, together with corresponding bounding box annotations which involve no human intervention. Firstly, we extract and project pixel-aligned image features into point clouds while estimating depth maps. We then re-project them with a target camera pose and render a novel-view 2d image. Objects in the form of keypoints are marked in point clouds to recover annotations in new views. Our new method is fully compatible with online data augmentation methods, such as affine transform, image mixup, etc. Extensive experiments show that our method, as a cost-free tool to enrich images and labels, can significantly boost the performance of object detection systems with scarce training data. Code is available at \url{https://github.com/Guanghan/DANR}.
Collaborative Multi-agent Learning for MR Knee Articular Cartilage Segmentation
Aug 13, 2019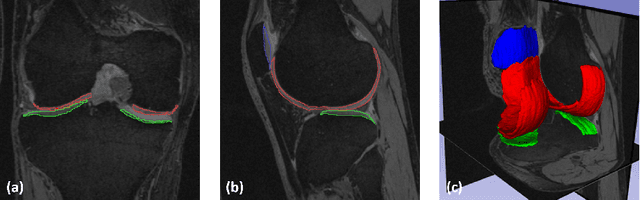
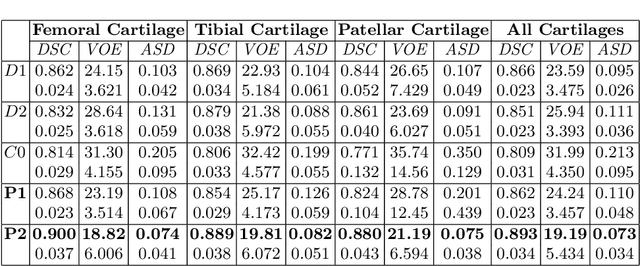
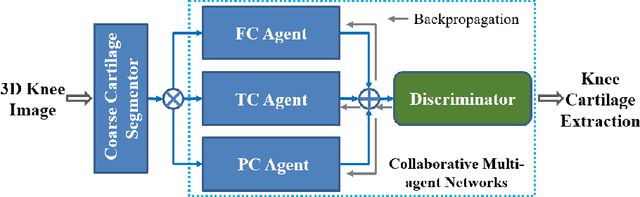
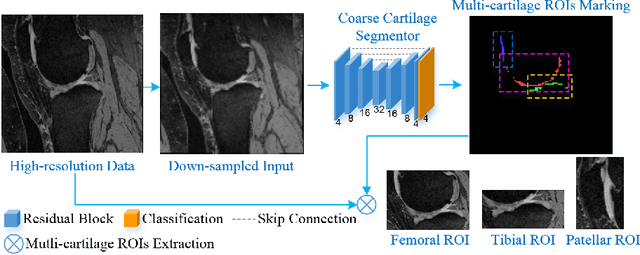
The 3D morphology and quantitative assessment of knee articular cartilages (i.e., femoral, tibial, and patellar cartilage) in magnetic resonance (MR) imaging is of great importance for knee radiographic osteoarthritis (OA) diagnostic decision making. However, effective and efficient delineation of all the knee articular cartilages in large-sized and high-resolution 3D MR knee data is still an open challenge. In this paper, we propose a novel framework to solve the MR knee cartilage segmentation task. The key contribution is the adversarial learning based collaborative multi-agent segmentation network. In the proposed network, we use three parallel segmentation agents to label cartilages in their respective region of interest (ROI), and then fuse the three cartilages by a novel ROI-fusion layer. The collaborative learning is driven by an adversarial sub-network. The ROI-fusion layer not only fuses the individual cartilages from multiple agents, but also backpropagates the training loss from the adversarial sub-network to each agent to enable joint learning of shape and spatial constraints. Extensive evaluations are conducted on a dataset including hundreds of MR knee volumes with diverse populations, and the proposed method shows superior performance.
Effective 3D Humerus and Scapula Extraction using Low-contrast and High-shape-variability MR Data
Feb 22, 2019For the initial shoulder preoperative diagnosis, it is essential to obtain a three-dimensional (3D) bone mask from medical images, e.g., magnetic resonance (MR). However, obtaining high-resolution and dense medical scans is both costly and time-consuming. In addition, the imaging parameters for each 3D scan may vary from time to time and thus increase the variance between images. Therefore, it is practical to consider the bone extraction on low-resolution data which may influence imaging contrast and make the segmentation work difficult. In this paper, we present a joint segmentation for the humerus and scapula bones on a small dataset with low-contrast and high-shape-variability 3D MR images. The proposed network has a deep end-to-end architecture to obtain the initial 3D bone masks. Because the existing scarce and inaccurate human-labeled ground truth, we design a self-reinforced learning strategy to increase performance. By comparing with the non-reinforced segmentation and a classical multi-atlas method with joint label fusion, the proposed approach obtains better results.