 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized algorithms for precise measurement of differentially-private, personalized recommendations
Aug 08, 2023



Personalized recommendations form an important part of today's internet ecosystem, helping artists and creators to reach interested users, and helping users to discover new and engaging content. However, many users today are skeptical of platforms that personalize recommendations, in part due to historically careless treatment of personal data and data privacy. Now, businesses that rely on personalized recommendations are entering a new paradigm, where many of their systems must be overhauled to be privacy-first. In this article, we propose an algorithm for personalized recommendations that facilitates both precise and differentially-private measurement. We consider advertising as an example application, and conduct offline experiments to quantify how the proposed privacy-preserving algorithm affects key metrics related to user experience, advertiser value, and platform revenue compared to the extremes of both (private) non-personalized and non-private, personalized implementations.
An Efficient and Robust System for Vertically Federated Random Forest
Jan 26, 2022As there is a growing interest in utilizing data across multiple resources to build better machine learning models, many vertically federated learning algorithms have been proposed to preserve the data privacy of the participating organizations. However, the efficiency of existing vertically federated learning algorithms remains to be a big problem, especially when applied to large-scale real-world datasets. In this paper, we present a fast, accurate, scalable and yet robust system for vertically federated random forest. With extensive optimization, we achieved $5\times$ and $83\times$ speed up over the SOTA SecureBoost model \cite{cheng2019secureboost} for training and serving tasks. Moreover, the proposed system can achieve similar accuracy but with favorable scalability and partition tolerance. Our code has been made public to facilitate the development of the community and the protection of user data privacy.
Graph-Enhanced Multi-Task Learning of Multi-Level Transition Dynamics for Session-based Recommendation
Oct 08, 2021
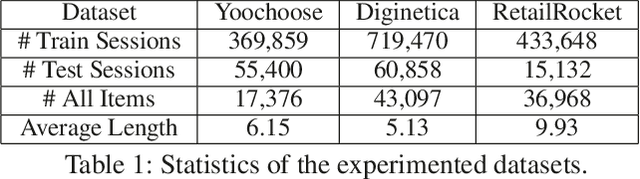

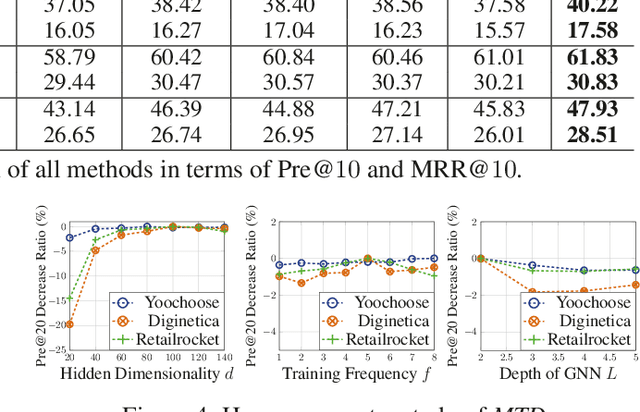
Session-based recommendation plays a central role in a wide spectrum of online applications, ranging from e-commerce to online advertising services. However, the majority of existing session-based recommendation techniques (e.g., attention-based recurrent network or graph neural network) are not well-designed for capturing the complex transition dynamics exhibited with temporally-ordered and multi-level inter-dependent relation structures. These methods largely overlook the relation hierarchy of item transitional patterns. In this paper, we propose a multi-task learning framework with Multi-level Transition Dynamics (MTD), which enables the jointly learning of intra- and inter-session item transition dynamics in automatic and hierarchical manner. Towards this end, we first develop a position-aware attention mechanism to learn item transitional regularities within individual session. Then, a graph-structured hierarchical relation encoder is proposed to explicitly capture the cross-session item transitions in the form of high-order connectivities by performing embedding propagation with the global graph context. The learning process of intra- and inter-session transition dynamics are integrated, to preserve the underlying low- and high-level item relationships in a common latent space. Extensive experiments on three real-world datasets demonstrate the superiority of MTD as compared to state-of-the-art baselines.
Fedlearn-Algo: A flexible open-source privacy-preserving machine learning platform
Jul 30, 2021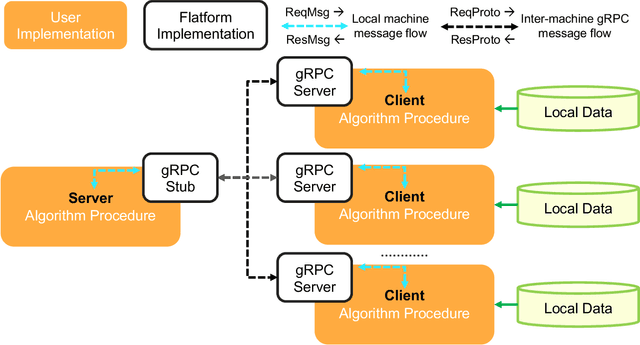
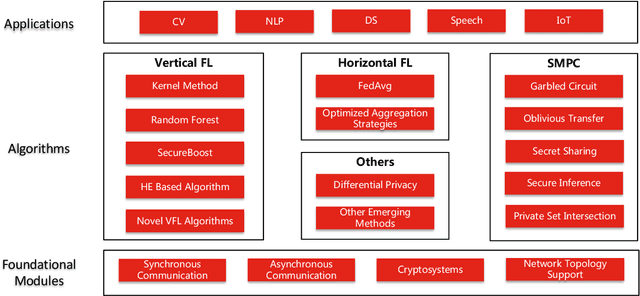
In this paper, we present Fedlearn-Algo, an open-source privacy preserving machine learning platform. We use this platform to demonstrate our research and development results on privacy preserving machine learning algorithms. As the first batch of novel FL algorithm examples, we release vertical federated kernel binary classification model and vertical federated random forest model. They have been tested to be more efficient than existing vertical federated learning models in our practice. Besides the novel FL algorithm examples, we also release a machine communication module. The uniform data transfer interface supports transferring widely used data formats between machines. We will maintain this platform by adding more functional modules and algorithm examples. The code is available at https://github.com/fedlearnAI/fedlearn-algo.
Recognizing Descriptive Wikipedia Categories for Historical Figures
Apr 24, 2017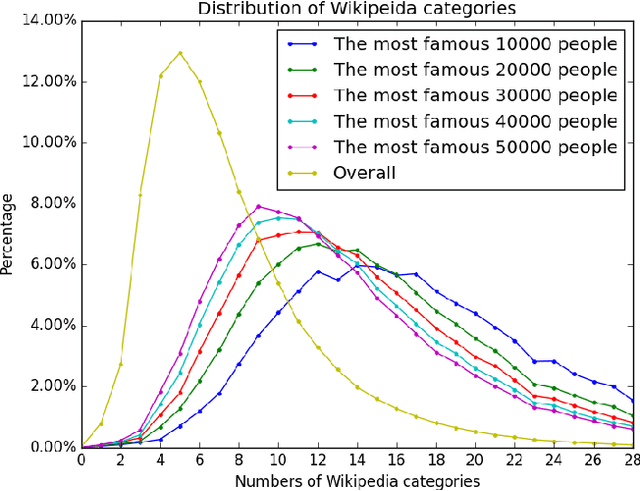
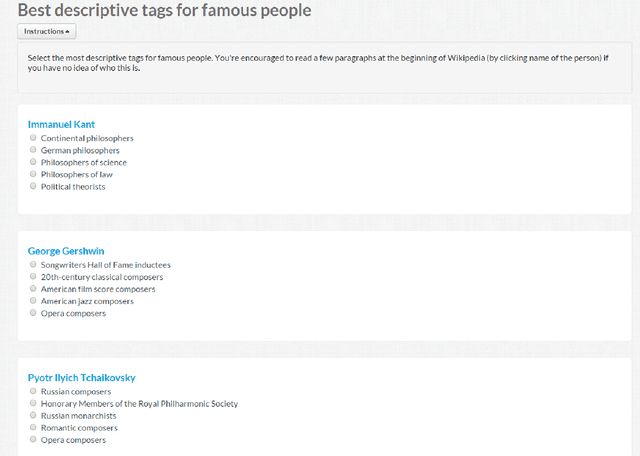
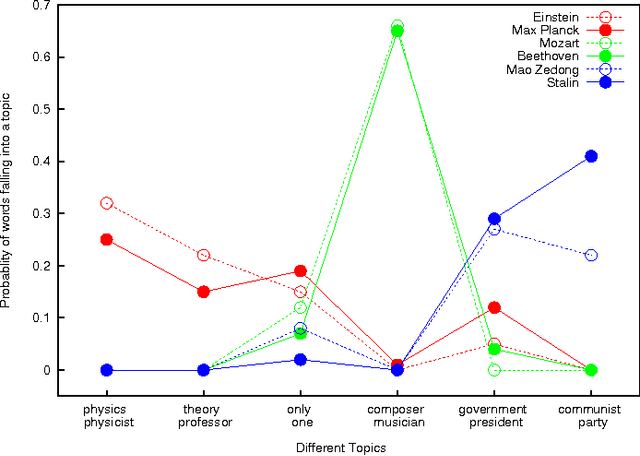
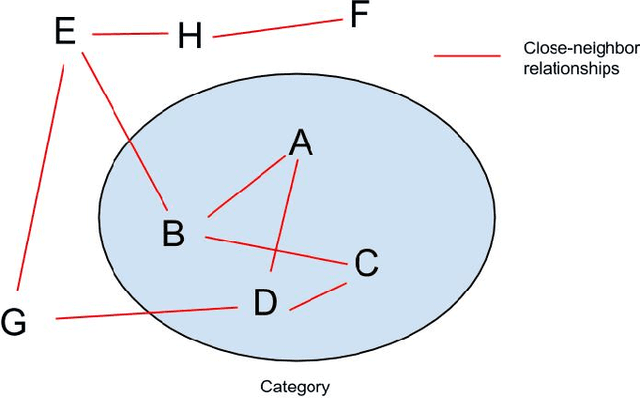
Wikipedia is a useful knowledge source that benefits many applications in language processing and knowledge representation. An important feature of Wikipedia is that of categories. Wikipedia pages are assigned different categories according to their contents as human-annotated labels which can be used in information retrieval, ad hoc search improvements, entity ranking and tag recommendations. However, important pages are usually assigned too many categories, which makes it difficult to recognize the most important ones that give the best descriptions. In this paper, we propose an approach to recognize the most descriptive Wikipedia categories. We observe that historical figures in a precise category presumably are mutually similar and such categorical coherence could be evaluated via texts or Wikipedia links of corresponding members in the category. We rank descriptive level of Wikipedia categories according to their coherence and our ranking yield an overall agreement of 88.27% compared with human wisdom.
False-Friend Detection and Entity Matching via Unsupervised Transliteration
Nov 21, 2016
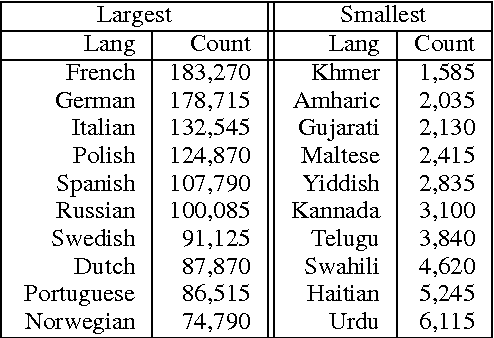
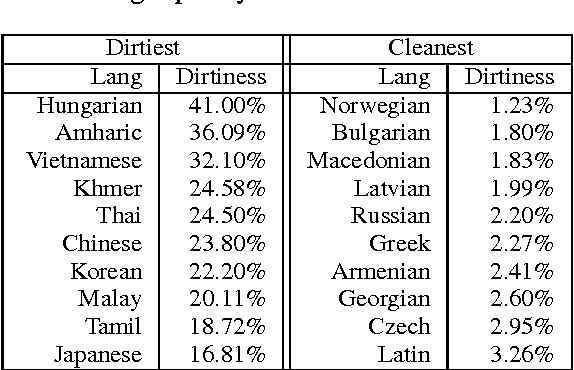

Transliterations play an important role in multilingual entity reference resolution, because proper names increasingly travel between languages in news and social media. Previous work associated with machine translation targets transliteration only single between language pairs, focuses on specific classes of entities (such as cities and celebrities) and relies on manual curation, which limits the expression power of transliteration in multilingual environment. By contrast, we present an unsupervised transliteration model covering 69 major languages that can generate good transliterations for arbitrary strings between any language pair. Our model yields top-(1, 20, 100) averages of (32.85%, 60.44%, 83.20%) in matching gold standard transliteration compared to results from a recently-published system of (26.71%, 50.27%, 72.79%). We also show the quality of our model in detecting true and false friends from Wikipedia high frequency lexicons. Our method indicates a strong signal of pronunciation similarity and boosts the probability of finding true friends in 68 out of 69 languages.
The Expressive Power of Word Embeddings
May 29, 2013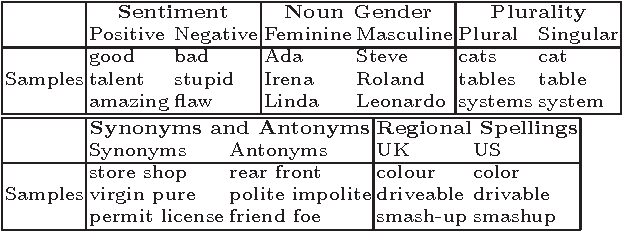
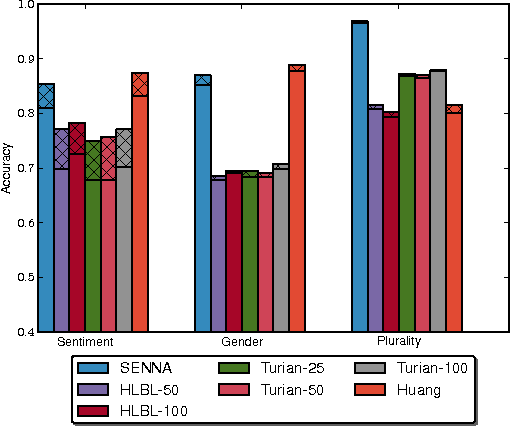
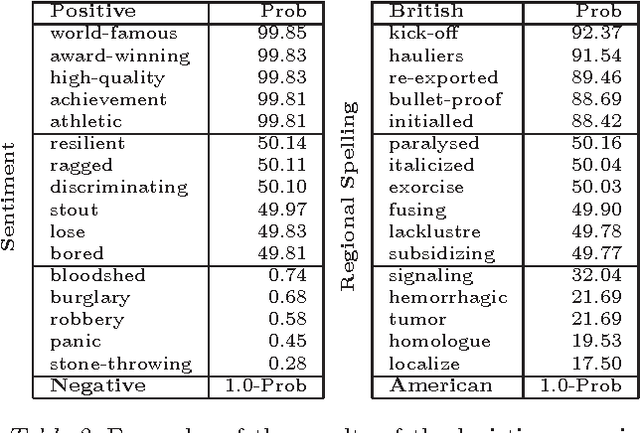
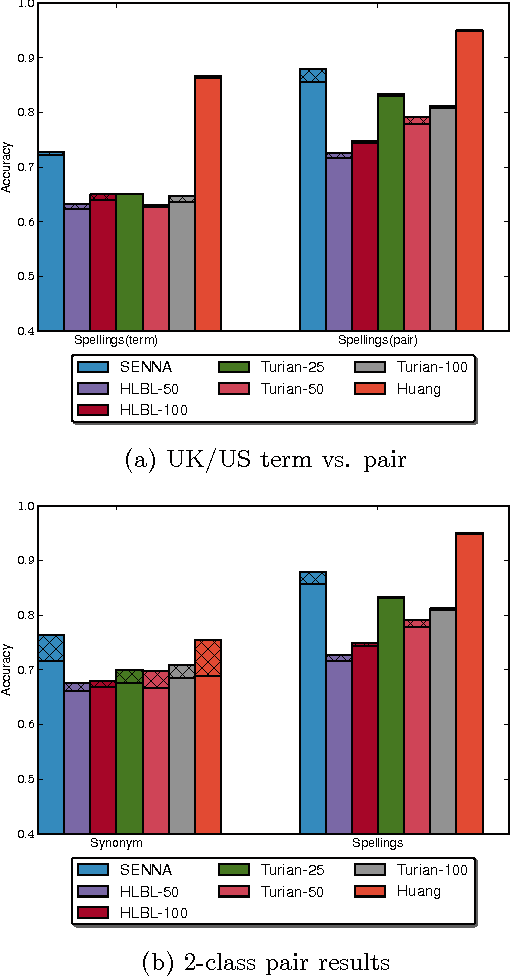
We seek to better understand the difference in quality of the several publicly released embeddings. We propose several tasks that help to distinguish the characteristics of different embeddings. Our evaluation of sentiment polarity and synonym/antonym relations shows that embeddings are able to capture surprisingly nuanced semantics even in the absence of sentence structure. Moreover, benchmarking the embeddings shows great variance in quality and characteristics of the semantics captured by the tested embeddings. Finally, we show the impact of varying the number of dimensions and the resolution of each dimension on the effective useful features captured by the embedding space. Our contributions highlight the importance of embeddings for NLP tasks and the effect of their quality on the final results.