 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Defense Strategies for Robust Image Watermarking
Feb 23, 2026Deep learning-based image watermarking, while robust against conventional distortions, remains vulnerable to advanced adversarial and regeneration attacks. Conventional countermeasures, which jointly optimize the encoder and decoder via a noise layer, face 2 inevitable challenges: (1) decrease of clean accuracy due to decoder adversarial training and (2) limited robustness due to simultaneous training of all three advanced attacks. To overcome these issues, we propose AdvMark, a novel two-stage fine-tuning framework that decouples the defense strategies. In stage 1, we address adversarial vulnerability via a tailored adversarial training paradigm that primarily fine-tunes the encoder while only conditionally updating the decoder. This approach learns to move the image into a non-attackable region, rather than modifying the decision boundary, thus preserving clean accuracy. In stage 2, we tackle distortion and regeneration attacks via direct image optimization. To preserve the adversarial robustness gained in stage 1, we formulate a principled, constrained image loss with theoretical guarantees, which balances the deviation from cover and previous encoded images. We also propose a quality-aware early-stop to further guarantee the lower bound of visual quality. Extensive experiments demonstrate AdvMark outperforms with the highest image quality and comprehensive robustness, i.e. up to 29\%, 33\% and 46\% accuracy improvement for distortion, regeneration and adversarial attacks, respectively.
HiVid: LLM-Guided Video Saliency For Content-Aware VOD And Live Streaming
Feb 15, 2026Content-aware streaming requires dynamic, chunk-level importance weights to optimize subjective quality of experience (QoE). However, direct human annotation is prohibitively expensive while vision-saliency models generalize poorly. We introduce HiVid, the first framework to leverage Large Language Models (LLMs) as a scalable human proxy to generate high-fidelity weights for both Video-on-Demand (VOD) and live streaming. We address 3 non-trivial challenges: (1) To extend LLMs' limited modality and circumvent token limits, we propose a perception module to assess frames in a local context window, autoregressively building a coherent understanding of the video. (2) For VOD with rating inconsistency across local windows, we propose a ranking module to perform global re-ranking with a novel LLM-guided merge-sort algorithm. (3) For live streaming which requires low-latency, online inference without future knowledge, we propose a prediction module to predict future weights with a multi-modal time series model, which comprises a content-aware attention and adaptive horizon to accommodate asynchronous LLM inference. Extensive experiments show HiVid improves weight prediction accuracy by up to 11.5\% for VOD and 26\% for live streaming over SOTA baselines. Real-world user study validates HiVid boosts streaming QoE correlation by 14.7\%.
Testing Storage-System Correctness: Challenges, Fuzzing Limitations, and AI-Augmented Opportunities
Feb 02, 2026Storage systems are fundamental to modern computing infrastructures, yet ensuring their correctness remains challenging in practice. Despite decades of research on system testing, many storage-system failures (including durability, ordering, recovery, and consistency violations) remain difficult to expose systematically. This difficulty stems not primarily from insufficient testing tooling, but from intrinsic properties of storage-system execution, including nondeterministic interleavings, long-horizon state evolution, and correctness semantics that span multiple layers and execution phases. This survey adopts a storage-centric view of system testing and organizes existing techniques according to the execution properties and failure mechanisms they target. We review a broad spectrum of approaches, ranging from concurrency testing and long-running workloads to crash-consistency analysis, hardware-level semantic validation, and distributed fault injection, and analyze their fundamental strengths and limitations. Within this framework, we examine fuzzing as an automated testing paradigm, highlighting systematic mismatches between conventional fuzzing assumptions and storage-system semantics, and discuss how recent artificial intelligence advances may complement fuzzing through state-aware and semantic guidance. Overall, this survey provides a unified perspective on storage-system correctness testing and outlines key challenges
Unified Text-Image Generation with Weakness-Targeted Post-Training
Jan 07, 2026Unified multimodal generation architectures that jointly produce text and images have recently emerged as a promising direction for text-to-image (T2I) synthesis. However, many existing systems rely on explicit modality switching, generating reasoning text before switching manually to image generation. This separate, sequential inference process limits cross-modal coupling and prohibits automatic multimodal generation. This work explores post-training to achieve fully unified text-image generation, where models autonomously transition from textual reasoning to visual synthesis within a single inference process. We examine the impact of joint text-image generation on T2I performance and the relative importance of each modality during post-training. We additionally explore different post-training data strategies, showing that a targeted dataset addressing specific limitations achieves superior results compared to broad image-caption corpora or benchmark-aligned data. Using offline, reward-weighted post-training with fully self-generated synthetic data, our approach enables improvements in multimodal image generation across four diverse T2I benchmarks, demonstrating the effectiveness of reward-weighting both modalities and strategically designed post-training data.
CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search
Nov 19, 2025Dense retrieval has become a foundational paradigm in modern search systems, especially on short-video platforms. However, most industrial systems adopt a self-reinforcing training pipeline that relies on historically exposed user interactions for supervision. This paradigm inevitably leads to a filter bubble effect, where potentially relevant but previously unseen content is excluded from the training signal, biasing the model toward narrow and conservative retrieval. In this paper, we present CroPS (Cross-Perspective Positive Samples), a novel retrieval data engine designed to alleviate this problem by introducing diverse and semantically meaningful positive examples from multiple perspectives. CroPS enhances training with positive signals derived from user query reformulation behavior (query-level), engagement data in recommendation streams (system-level), and world knowledge synthesized by large language models (knowledge-level). To effectively utilize these heterogeneous signals, we introduce a Hierarchical Label Assignment (HLA) strategy and a corresponding H-InfoNCE loss that together enable fine-grained, relevance-aware optimization. Extensive experiments conducted on Kuaishou Search, a large-scale commercial short-video search platform, demonstrate that CroPS significantly outperforms strong baselines both offline and in live A/B tests, achieving superior retrieval performance and reducing query reformulation rates. CroPS is now fully deployed in Kuaishou Search, serving hundreds of millions of users daily.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025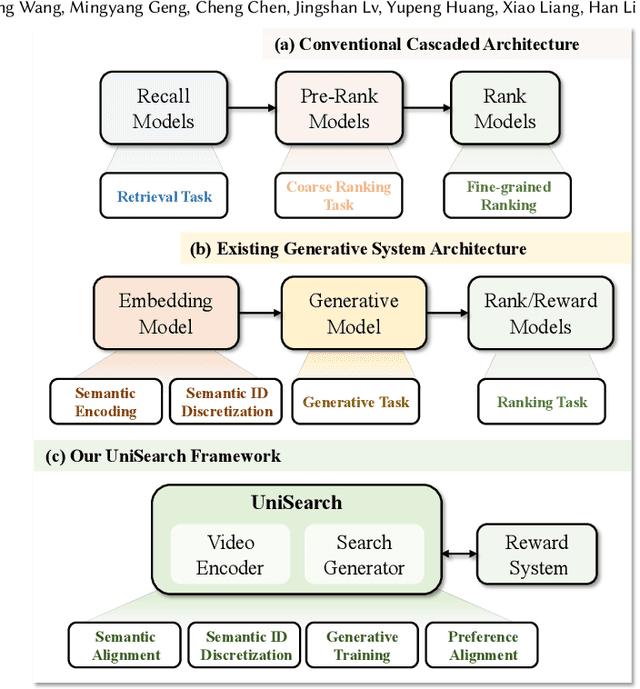
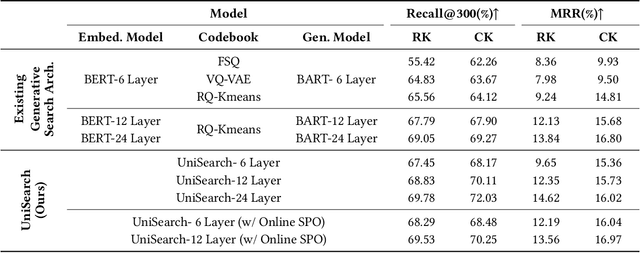
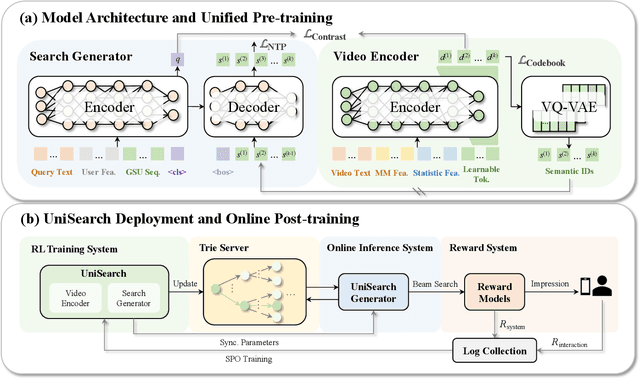
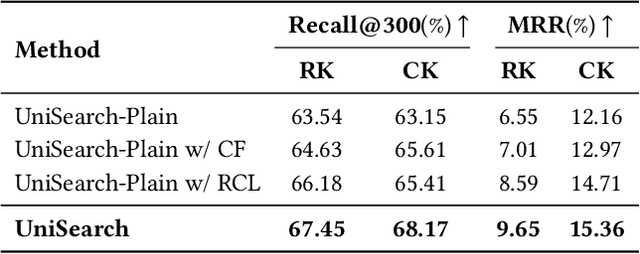
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
3D Vision-tactile Reconstruction from Infrared and Visible Images for Robotic Fine-grained Tactile Perception
Jun 18, 2025To achieve human-like haptic perception in anthropomorphic grippers, the compliant sensing surfaces of vision tactile sensor (VTS) must evolve from conventional planar configurations to biomimetically curved topographies with continuous surface gradients. However, planar VTSs have challenges when extended to curved surfaces, including insufficient lighting of surfaces, blurring in reconstruction, and complex spatial boundary conditions for surface structures. With an end goal of constructing a human-like fingertip, our research (i) develops GelSplitter3D by expanding imaging channels with a prism and a near-infrared (NIR) camera, (ii) proposes a photometric stereo neural network with a CAD-based normal ground truth generation method to calibrate tactile geometry, and (iii) devises a normal integration method with boundary constraints of depth prior information to correcting the cumulative error of surface integrals. We demonstrate better tactile sensing performance, a 40$\%$ improvement in normal estimation accuracy, and the benefits of sensor shapes in grasping and manipulation tasks.
MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
May 18, 2025Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, limiting their applicability to tasks where historical context is crucial for disambiguating current observations. This limitation hinders performance in long-horizon sequential manipulation tasks where the correct action depends on past events not fully captured by the current state. To address this fundamental challenge, we introduce Mamba Temporal Imitation Learning (MTIL), a novel approach that leverages the recurrent state dynamics inherent in State Space Models (SSMs), specifically the Mamba architecture. MTIL encodes the entire trajectory history into a compressed hidden state, conditioning action predictions on this comprehensive temporal context alongside current multi-modal observations. Through extensive experiments on simulated benchmarks (ACT dataset tasks, Robomimic, LIBERO) and real-world sequential manipulation tasks specifically designed to probe temporal dependencies, MTIL significantly outperforms state-of-the-art methods like ACT and Diffusion Policy. Our findings affirm the necessity of full temporal context for robust sequential decision-making and validate MTIL as a powerful approach that transcends the inherent limitations of Markovian imitation learning
Multi-Modal Language Models as Text-to-Image Model Evaluators
May 01, 2025The steady improvements of text-to-image (T2I) generative models lead to slow deprecation of automatic evaluation benchmarks that rely on static datasets, motivating researchers to seek alternative ways to evaluate the T2I progress. In this paper, we explore the potential of multi-modal large language models (MLLMs) as evaluator agents that interact with a T2I model, with the objective of assessing prompt-generation consistency and image aesthetics. We present Multimodal Text-to-Image Eval (MT2IE), an evaluation framework that iteratively generates prompts for evaluation, scores generated images and matches T2I evaluation of existing benchmarks with a fraction of the prompts used in existing static benchmarks. Moreover, we show that MT2IE's prompt-generation consistency scores have higher correlation with human judgment than scores previously introduced in the literature. MT2IE generates prompts that are efficient at probing T2I model performance, producing the same relative T2I model rankings as existing benchmarks while using only 1/80th the number of prompts for evaluation.
Audio-driven Gesture Generation via Deviation Feature in the Latent Space
Mar 27, 2025Gestures are essential for enhancing co-speech communication, offering visual emphasis and complementing verbal interactions. While prior work has concentrated on point-level motion or fully supervised data-driven methods, we focus on co-speech gestures, advocating for weakly supervised learning and pixel-level motion deviations. We introduce a weakly supervised framework that learns latent representation deviations, tailored for co-speech gesture video generation. Our approach employs a diffusion model to integrate latent motion features, enabling more precise and nuanced gesture representation. By leveraging weakly supervised deviations in latent space, we effectively generate hand gestures and mouth movements, crucial for realistic video production. Experiments show our method significantly improves video quality, surpassing current state-of-the-art techniques.