 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Vision-tactile Reconstruction from Infrared and Visible Images for Robotic Fine-grained Tactile Perception
Jun 18, 2025To achieve human-like haptic perception in anthropomorphic grippers, the compliant sensing surfaces of vision tactile sensor (VTS) must evolve from conventional planar configurations to biomimetically curved topographies with continuous surface gradients. However, planar VTSs have challenges when extended to curved surfaces, including insufficient lighting of surfaces, blurring in reconstruction, and complex spatial boundary conditions for surface structures. With an end goal of constructing a human-like fingertip, our research (i) develops GelSplitter3D by expanding imaging channels with a prism and a near-infrared (NIR) camera, (ii) proposes a photometric stereo neural network with a CAD-based normal ground truth generation method to calibrate tactile geometry, and (iii) devises a normal integration method with boundary constraints of depth prior information to correcting the cumulative error of surface integrals. We demonstrate better tactile sensing performance, a 40$\%$ improvement in normal estimation accuracy, and the benefits of sensor shapes in grasping and manipulation tasks.
MTIL: Encoding Full History with Mamba for Temporal Imitation Learning
May 18, 2025Standard imitation learning (IL) methods have achieved considerable success in robotics, yet often rely on the Markov assumption, limiting their applicability to tasks where historical context is crucial for disambiguating current observations. This limitation hinders performance in long-horizon sequential manipulation tasks where the correct action depends on past events not fully captured by the current state. To address this fundamental challenge, we introduce Mamba Temporal Imitation Learning (MTIL), a novel approach that leverages the recurrent state dynamics inherent in State Space Models (SSMs), specifically the Mamba architecture. MTIL encodes the entire trajectory history into a compressed hidden state, conditioning action predictions on this comprehensive temporal context alongside current multi-modal observations. Through extensive experiments on simulated benchmarks (ACT dataset tasks, Robomimic, LIBERO) and real-world sequential manipulation tasks specifically designed to probe temporal dependencies, MTIL significantly outperforms state-of-the-art methods like ACT and Diffusion Policy. Our findings affirm the necessity of full temporal context for robust sequential decision-making and validate MTIL as a powerful approach that transcends the inherent limitations of Markovian imitation learning
Tri-Perspective View Decomposition for Geometry-Aware Depth Completion
Mar 22, 2024Depth completion is a vital task for autonomous driving, as it involves reconstructing the precise 3D geometry of a scene from sparse and noisy depth measurements. However, most existing methods either rely only on 2D depth representations or directly incorporate raw 3D point clouds for compensation, which are still insufficient to capture the fine-grained 3D geometry of the scene. To address this challenge, we introduce Tri-Perspective view Decomposition (TPVD), a novel framework that can explicitly model 3D geometry. In particular, (1) TPVD ingeniously decomposes the original point cloud into three 2D views, one of which corresponds to the sparse depth input. (2) We design TPV Fusion to update the 2D TPV features through recurrent 2D-3D-2D aggregation, where a Distance-Aware Spherical Convolution (DASC) is applied. (3) By adaptively choosing TPV affinitive neighbors, the newly proposed Geometric Spatial Propagation Network (GSPN) further improves the geometric consistency. As a result, our TPVD outperforms existing methods on KITTI, NYUv2, and SUN RGBD. Furthermore, we build a novel depth completion dataset named TOFDC, which is acquired by the time-of-flight (TOF) sensor and the color camera on smartphones. Project page: https://yanzq95.github.io/projectpage/TOFDC/index.html
GelSplitter: Tactile Reconstruction from Near Infrared and Visible Images
Sep 15, 2023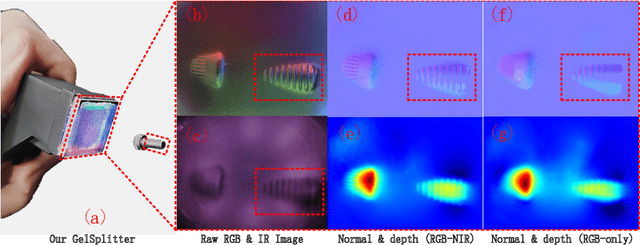

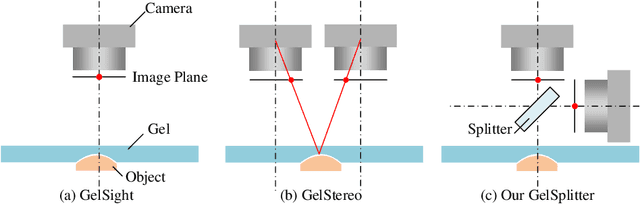
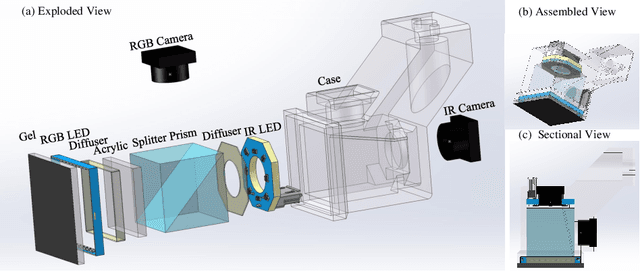
The GelSight-like visual tactile (VT) sensor has gained popularity as a high-resolution tactile sensing technology for robots, capable of measuring touch geometry using a single RGB camera. However, the development of multi-modal perception for VT sensors remains a challenge, limited by the mono camera. In this paper, we propose the GelSplitter, a new framework approach the multi-modal VT sensor with synchronized multi-modal cameras and resemble a more human-like tactile receptor. Furthermore, we focus on 3D tactile reconstruction and implement a compact sensor structure that maintains a comparable size to state-of-the-art VT sensors, even with the addition of a prism and a near infrared (NIR) camera. We also design a photometric fusion stereo neural network (PFSNN), which estimates surface normals of objects and reconstructs touch geometry from both infrared and visible images. Our results demonstrate that the accuracy of RGB and NIR fusion is higher than that of RGB images alone. Additionally, our GelSplitter framework allows for a flexible configuration of different camera sensor combinations, such as RGB and thermal imaging.
Dynamic Spatial Propagation Network for Depth Completion
Feb 20, 2022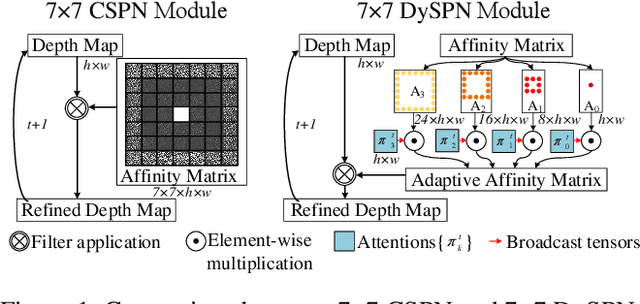
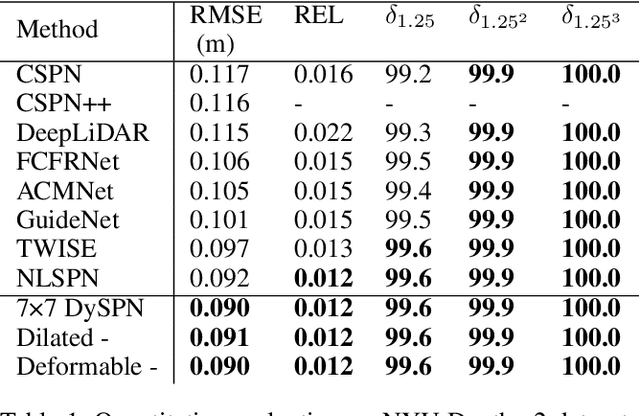
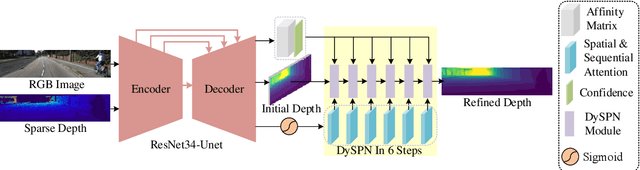
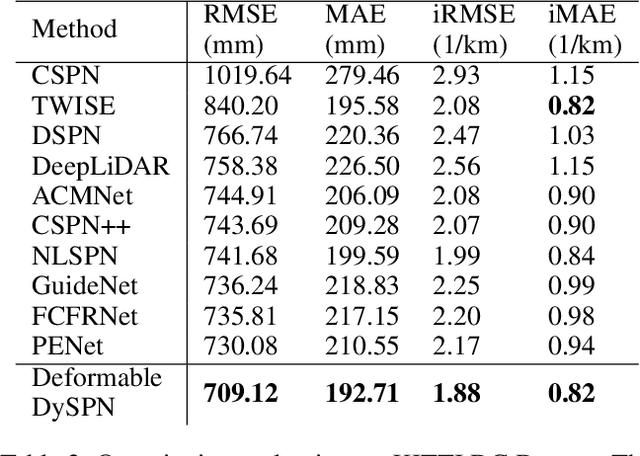
Image-guided depth completion aims to generate dense depth maps with sparse depth measurements and corresponding RGB images. Currently, spatial propagation networks (SPNs) are the most popular affinity-based methods in depth completion, but they still suffer from the representation limitation of the fixed affinity and the over smoothing during iterations. Our solution is to estimate independent affinity matrices in each SPN iteration, but it is over-parameterized and heavy calculation. This paper introduces an efficient model that learns the affinity among neighboring pixels with an attention-based, dynamic approach. Specifically, the Dynamic Spatial Propagation Network (DySPN) we proposed makes use of a non-linear propagation model (NLPM). It decouples the neighborhood into parts regarding to different distances and recursively generates independent attention maps to refine these parts into adaptive affinity matrices. Furthermore, we adopt a diffusion suppression (DS) operation so that the model converges at an early stage to prevent over-smoothing of dense depth. Finally, in order to decrease the computational cost required, we also introduce three variations that reduce the amount of neighbors and attentions needed while still retaining similar accuracy. In practice, our method requires less iteration to match the performance of other SPNs and yields better results overall. DySPN outperforms other state-of-the-art (SoTA) methods on KITTI Depth Completion (DC) evaluation by the time of submission and is able to yield SoTA performance in NYU Depth v2 dataset as well.