 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Finger on the Pulse of Cardiovascular Health: Smartphone Photoplethysmography-Based Pulse Waveform Analysis for Blood Pressure Measurement
Jan 20, 2024Routine blood pressure (BP) monitoring, crucial for health assessment, faces challenges such as limited access to medical-grade equipment and expertise. Portable cuff BP devices, on the other hand, are cumbersome to carry all day and often cost-prohibitive in less developed countries. Besides, these sphygmomanometer-based devices can cause discomfort and disrupt blood flow during measurement. This study explores the use of smartphones for continuous BP monitoring, focusing on overcoming the trust barriers associated with the opacity of machine learning models in predicting BP from low-quality PPG signals. Our approach included developing models based on cardiovascular literature, using simple statistical methods to estimate BP from smartphone PPG signals with comprehensive data pre-processing, applying SHAP for enhanced interpretability and feature identification, and comparing our methods against standard references using Bland-Altman analysis. Validated with data from 125 participants, the study demonstrated significant correlations in waveform features between smartphone and reference BP monitoring devices. The cross-validation of linear regression [MAE=9.86 and 8.01 mmHg for systolic blood pressure (SBP) and diastolic blood pressure (DBP), respectively] and random forest model (MAE=8.91 and 6.68 mmHg for SBP and DBP) using waveform-only variables demonstrated the feasibility of using a smartphone to estimate BP. Although SHAP analysis identified key feature sets, Bland-Altman results did not fully meet established thresholds (84.64% and 94.69% of MAE<15 mmHg for SBP and DBP, respectively). The study suggests the potential of smartphone cameras to enhance the accuracy and interpretability of machine learning models for daily BP estimation, but also indicates that smartphone PPG-based BP prediction is not yet a replacement for traditional medical devices.
GelSplitter: Tactile Reconstruction from Near Infrared and Visible Images
Sep 15, 2023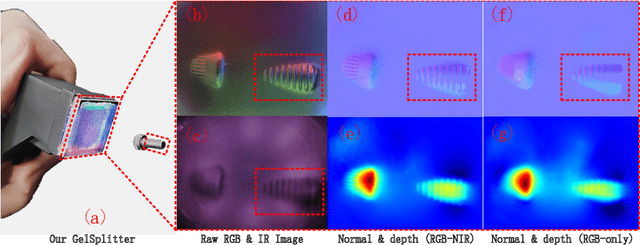

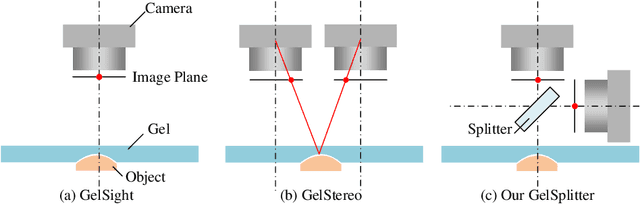
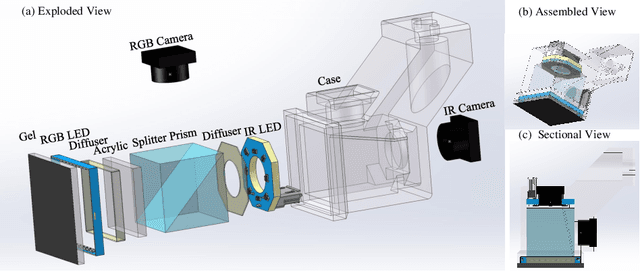
The GelSight-like visual tactile (VT) sensor has gained popularity as a high-resolution tactile sensing technology for robots, capable of measuring touch geometry using a single RGB camera. However, the development of multi-modal perception for VT sensors remains a challenge, limited by the mono camera. In this paper, we propose the GelSplitter, a new framework approach the multi-modal VT sensor with synchronized multi-modal cameras and resemble a more human-like tactile receptor. Furthermore, we focus on 3D tactile reconstruction and implement a compact sensor structure that maintains a comparable size to state-of-the-art VT sensors, even with the addition of a prism and a near infrared (NIR) camera. We also design a photometric fusion stereo neural network (PFSNN), which estimates surface normals of objects and reconstructs touch geometry from both infrared and visible images. Our results demonstrate that the accuracy of RGB and NIR fusion is higher than that of RGB images alone. Additionally, our GelSplitter framework allows for a flexible configuration of different camera sensor combinations, such as RGB and thermal imaging.
Masked Language Model Based Textual Adversarial Example Detection
Apr 19, 2023
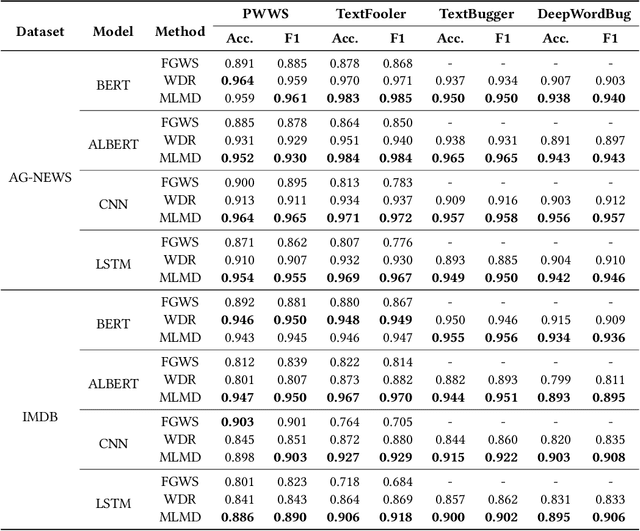


Adversarial attacks are a serious threat to the reliable deployment of machine learning models in safety-critical applications. They can misguide current models to predict incorrectly by slightly modifying the inputs. Recently, substantial work has shown that adversarial examples tend to deviate from the underlying data manifold of normal examples, whereas pre-trained masked language models can fit the manifold of normal NLP data. To explore how to use the masked language model in adversarial detection, we propose a novel textual adversarial example detection method, namely Masked Language Model-based Detection (MLMD), which can produce clearly distinguishable signals between normal examples and adversarial examples by exploring the changes in manifolds induced by the masked language model. MLMD features a plug and play usage (i.e., no need to retrain the victim model) for adversarial defense and it is agnostic to classification tasks, victim model's architectures, and to-be-defended attack methods. We evaluate MLMD on various benchmark textual datasets, widely studied machine learning models, and state-of-the-art (SOTA) adversarial attacks (in total $3*4*4 = 48$ settings). Experimental results show that MLMD can achieve strong performance, with detection accuracy up to 0.984, 0.967, and 0.901 on AG-NEWS, IMDB, and SST-2 datasets, respectively. Additionally, MLMD is superior, or at least comparable to, the SOTA detection defenses in detection accuracy and F1 score. Among many defenses based on the off-manifold assumption of adversarial examples, this work offers a new angle for capturing the manifold change. The code for this work is openly accessible at \url{https://github.com/mlmddetection/MLMDdetection}.
Attention Distraction: Watermark Removal Through Continual Learning with Selective Forgetting
Apr 05, 2022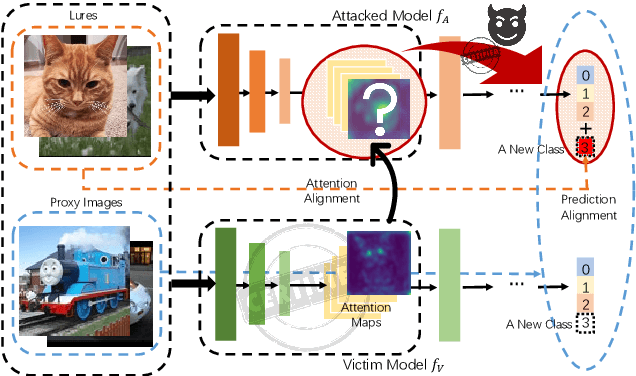
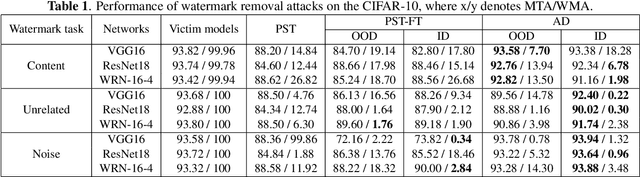
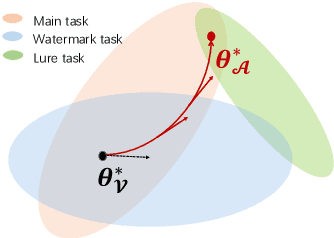

Fine-tuning attacks are effective in removing the embedded watermarks in deep learning models. However, when the source data is unavailable, it is challenging to just erase the watermark without jeopardizing the model performance. In this context, we introduce Attention Distraction (AD), a novel source data-free watermark removal attack, to make the model selectively forget the embedded watermarks by customizing continual learning. In particular, AD first anchors the model's attention on the main task using some unlabeled data. Then, through continual learning, a small number of \textit{lures} (randomly selected natural images) that are assigned a new label distract the model's attention away from the watermarks. Experimental results from different datasets and networks corroborate that AD can thoroughly remove the watermark with a small resource budget without compromising the model's performance on the main task, which outperforms the state-of-the-art works.
Dynamic Spatial Propagation Network for Depth Completion
Feb 20, 2022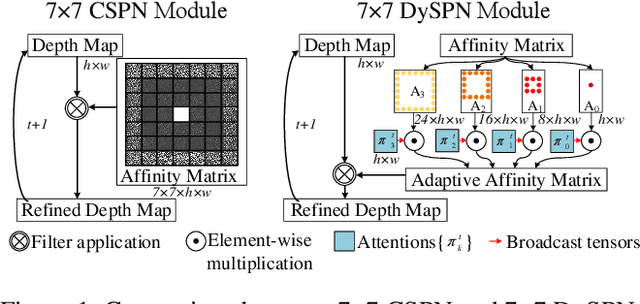
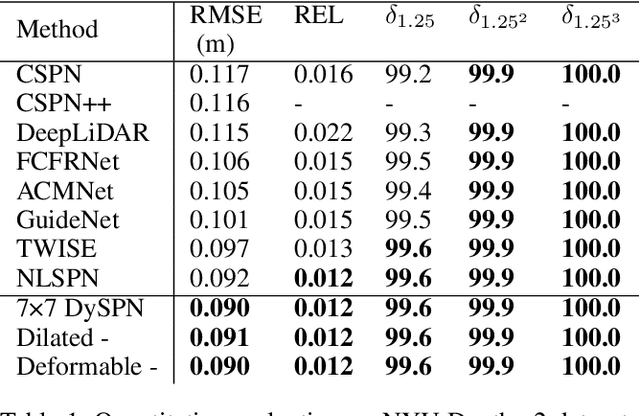
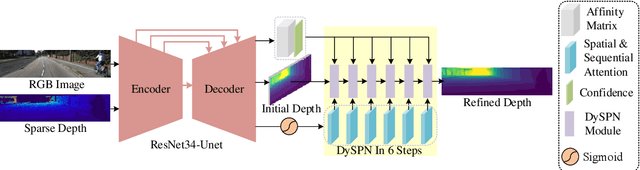
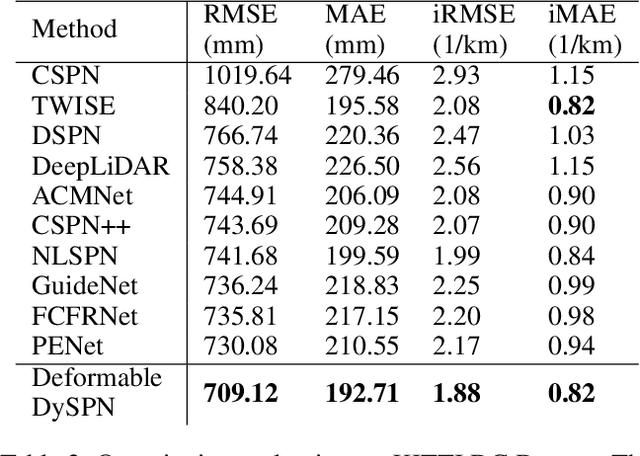
Image-guided depth completion aims to generate dense depth maps with sparse depth measurements and corresponding RGB images. Currently, spatial propagation networks (SPNs) are the most popular affinity-based methods in depth completion, but they still suffer from the representation limitation of the fixed affinity and the over smoothing during iterations. Our solution is to estimate independent affinity matrices in each SPN iteration, but it is over-parameterized and heavy calculation. This paper introduces an efficient model that learns the affinity among neighboring pixels with an attention-based, dynamic approach. Specifically, the Dynamic Spatial Propagation Network (DySPN) we proposed makes use of a non-linear propagation model (NLPM). It decouples the neighborhood into parts regarding to different distances and recursively generates independent attention maps to refine these parts into adaptive affinity matrices. Furthermore, we adopt a diffusion suppression (DS) operation so that the model converges at an early stage to prevent over-smoothing of dense depth. Finally, in order to decrease the computational cost required, we also introduce three variations that reduce the amount of neighbors and attentions needed while still retaining similar accuracy. In practice, our method requires less iteration to match the performance of other SPNs and yields better results overall. DySPN outperforms other state-of-the-art (SoTA) methods on KITTI Depth Completion (DC) evaluation by the time of submission and is able to yield SoTA performance in NYU Depth v2 dataset as well.