 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Distraction: Watermark Removal Through Continual Learning with Selective Forgetting
Paper and Code
Apr 05, 2022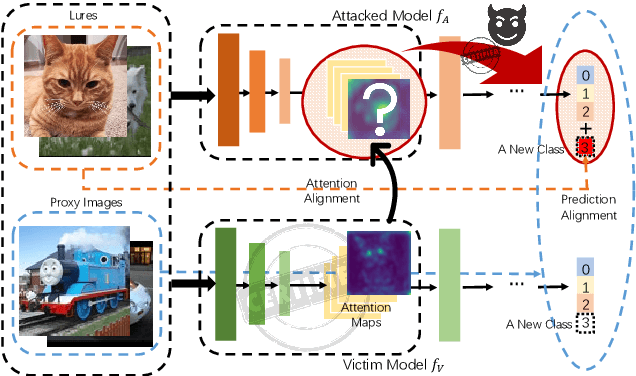
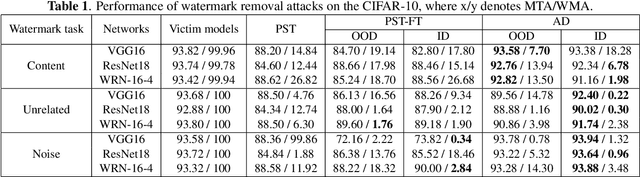
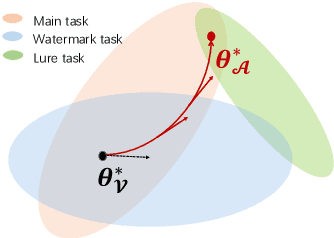

Fine-tuning attacks are effective in removing the embedded watermarks in deep learning models. However, when the source data is unavailable, it is challenging to just erase the watermark without jeopardizing the model performance. In this context, we introduce Attention Distraction (AD), a novel source data-free watermark removal attack, to make the model selectively forget the embedded watermarks by customizing continual learning. In particular, AD first anchors the model's attention on the main task using some unlabeled data. Then, through continual learning, a small number of \textit{lures} (randomly selected natural images) that are assigned a new label distract the model's attention away from the watermarks. Experimental results from different datasets and networks corroborate that AD can thoroughly remove the watermark with a small resource budget without compromising the model's performance on the main task, which outperforms the state-of-the-art works.