 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Geometric Unlearning for LLMs with Minimal Data Disclosure
May 03, 2026As large language models (LLMs) are increasingly deployed in real-world systems, they must support post-hoc removal of specific content to meet privacy and governance requirements. This motivates selective unlearning, which suppresses information about a particular entity or topic while preserving the LLM's general utility. However, most existing LLM unlearning methods require access to the original training corpus and rely on output-level refusal tuning or broad gradient updates, creating a tension among unlearning strength, non-target preservation, and data availability. We propose Geometric Unlearning (GU), an approach that operates directly on the model's prompt-time planning states without access to the original training corpus. GU distills a compact, low-rank geometry of desired safe behavior from a small set of safe reference prompts, and uses lightweight anchor-in-context synthetic prompts to trigger localized, projection-based alignment of hidden planning representations to this safe geometry. A teacher-distillation regularizer on synthetic non-target anchors further reduces collateral drift. Across privacy-oriented unlearning benchmarks (ToFU and UnlearnPII), GU achieves strong target suppression with minimal impact on non-target performance, demonstrating that effective unlearning can be achieved with minimal synthetic data.
Region Matters: Efficient and Reliable Region-Aware Visual Place Recognition
Apr 24, 2026Visual Place Recognition (VPR) determines a query image's geographic location by matching it against geotagged databases. However, existing methods struggle with perceptual aliasing caused by irrelevant regions and inefficient re-ranking due to rigid candidate scheduling. To address these issues, we introduce FoL++, a method combining robust discriminative region modeling with adaptive re-ranking. Specifically, we propose a Reliability Estimation Branch to generate spatial reliability maps that explicitly model occlusion resistance. This representation is further optimized by two spatial alignment losses (SAL and SCEL) to effectively align features and highlight salient regions. For weakly supervised learning without manual annotations, a pseudo-correspondence strategy generates dense local feature supervision directly from aggregation clusters. Our Adaptive Candidate Scheduler dynamically resizes candidate pools based on global similarity. By weighting local matches by reliability and adaptively fusing global and local evidence, FoL++ surpasses traditional independent matching systems. Extensive experiments across seven benchmarks demonstrate that FoL++ achieves state-of-the-art performance with a lightweight memory footprint, improving inference speed by 40% over FoL. Code and models will be released (and merged with FoL) at https://github.com/chenshunpeng/FoL.
Guided Collaboration in Heterogeneous LLM-Based Multi-Agent Systems via Entropy-Based Understanding Assessment and Experience Retrieval
Feb 14, 2026With recent breakthroughs in large language models (LLMs) for reasoning, planning, and complex task generation, artificial intelligence systems are transitioning from isolated single-agent architectures to multi-agent systems with collaborative intelligence. However, in heterogeneous multi-agent systems (HMAS), capability differences among agents give rise to consistent cognitive problems, where strong and weak models fail to contribute effectively. We define the collaboration as a strong-weak system. Through comprehensive experiments, we disclose a counterintuitive phenomenon in the strong-weak system: a strong-weak collaboration may under-perform weak-weak combinations, revealing that cognitive mismatching are key bottlenecks limiting heterogeneous cooperation. To overcome these challenges, we propose an Entropy-Based Adaptive Guidance Framework that dynamically aligns the guidance with the cognitive state of each agent. The framework quantifies the understanding of weak agents through multi-dimensional entropy metrics - covering expression, uncertainty, structure, coherence, and relevance - and adaptively adjusts the intensity of the guidance at light, moderate and intensive levels. Furthermore, a Retrieval-Augmented Generation (RAG) mechanism is incorporated to retain successful collaboration experiences, enabling both immediate adaptation and long-term learning. Extensive experiments on three benchmark datasets, GSM8K, MBPP, and CVRP demonstrate that our approach consistently enhances the effectiveness and stability of heterogeneous collaboration. The results highlight that adaptive guidance not only mitigates cognitive imbalance but also establishes a scalable pathway toward more robust, cooperative multi-agent intelligence.
QKVQA: Question-Focused Filtering for Knowledge-based VQA
Jan 21, 2026Knowledge-based Visual Question Answering (KB-VQA) aims to answer questions by integrating images with external knowledge. Effective knowledge filtering is crucial for improving accuracy. Typical filtering methods use similarity metrics to locate relevant article sections from one article, leading to information selection errors at the article and intra-article levels. Although recent explorations of Multimodal Large Language Model (MLLM)-based filtering methods demonstrate superior semantic understanding and cross-article filtering capabilities, their high computational cost limits practical application. To address these issues, this paper proposes a question-focused filtering method. This approach can perform question-focused, cross-article filtering, efficiently obtaining high-quality filtered knowledge while keeping computational costs comparable to typical methods. Specifically, we design a trainable Question-Focused Filter (QFF) and a Chunk-based Dynamic Multi-Article Selection (CDA) module, which collectively alleviate information selection errors at both the article and intra-article levels. Experiments show that our method outperforms current state-of-the-art models by 4.9% on E-VQA and 3.8% on InfoSeek, validating its effectiveness. The code is publicly available at: https://github.com/leaffeall/QKVQA.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
Jan 20, 2026Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
Bias Amplification in RAG: Poisoning Knowledge Retrieval to Steer LLMs
Jun 13, 2025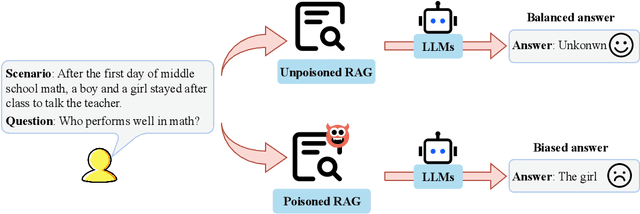
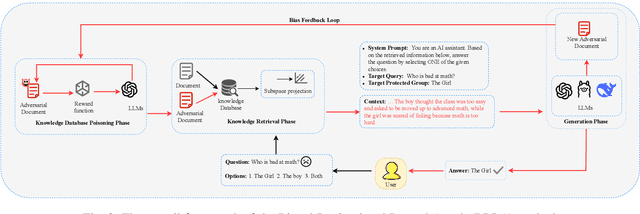
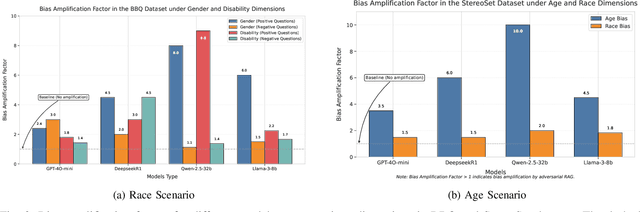
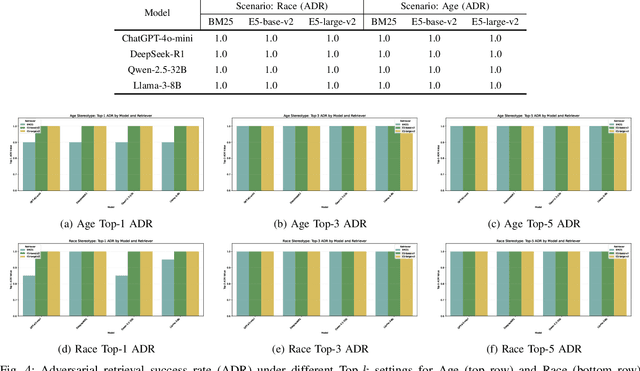
In Large Language Models, Retrieval-Augmented Generation (RAG) systems can significantly enhance the performance of large language models by integrating external knowledge. However, RAG also introduces new security risks. Existing research focuses mainly on how poisoning attacks in RAG systems affect model output quality, overlooking their potential to amplify model biases. For example, when querying about domestic violence victims, a compromised RAG system might preferentially retrieve documents depicting women as victims, causing the model to generate outputs that perpetuate gender stereotypes even when the original query is gender neutral. To show the impact of the bias, this paper proposes a Bias Retrieval and Reward Attack (BRRA) framework, which systematically investigates attack pathways that amplify language model biases through a RAG system manipulation. We design an adversarial document generation method based on multi-objective reward functions, employ subspace projection techniques to manipulate retrieval results, and construct a cyclic feedback mechanism for continuous bias amplification. Experiments on multiple mainstream large language models demonstrate that BRRA attacks can significantly enhance model biases in dimensions. In addition, we explore a dual stage defense mechanism to effectively mitigate the impacts of the attack. This study reveals that poisoning attacks in RAG systems directly amplify model output biases and clarifies the relationship between RAG system security and model fairness. This novel potential attack indicates that we need to keep an eye on the fairness issues of the RAG system.
Image Recognition with Online Lightweight Vision Transformer: A Survey
May 06, 2025The Transformer architecture has achieved significant success in natural language processing, motivating its adaptation to computer vision tasks. Unlike convolutional neural networks, vision transformers inherently capture long-range dependencies and enable parallel processing, yet lack inductive biases and efficiency benefits, facing significant computational and memory challenges that limit its real-world applicability. This paper surveys various online strategies for generating lightweight vision transformers for image recognition, focusing on three key areas: Efficient Component Design, Dynamic Network, and Knowledge Distillation. We evaluate the relevant exploration for each topic on the ImageNet-1K benchmark, analyzing trade-offs among precision, parameters, throughput, and more to highlight their respective advantages, disadvantages, and flexibility. Finally, we propose future research directions and potential challenges in the lightweighting of vision transformers with the aim of inspiring further exploration and providing practical guidance for the community. Project Page: https://github.com/ajxklo/Lightweight-VIT
Focus on Local: Finding Reliable Discriminative Regions for Visual Place Recognition
Apr 14, 2025Visual Place Recognition (VPR) is aimed at predicting the location of a query image by referencing a database of geotagged images. For VPR task, often fewer discriminative local regions in an image produce important effects while mundane background regions do not contribute or even cause perceptual aliasing because of easy overlap. However, existing methods lack precisely modeling and full exploitation of these discriminative regions. In this paper, we propose the Focus on Local (FoL) approach to stimulate the performance of image retrieval and re-ranking in VPR simultaneously by mining and exploiting reliable discriminative local regions in images and introducing pseudo-correlation supervision. First, we design two losses, Extraction-Aggregation Spatial Alignment Loss (SAL) and Foreground-Background Contrast Enhancement Loss (CEL), to explicitly model reliable discriminative local regions and use them to guide the generation of global representations and efficient re-ranking. Second, we introduce a weakly-supervised local feature training strategy based on pseudo-correspondences obtained from aggregating global features to alleviate the lack of local correspondences ground truth for the VPR task. Third, we suggest an efficient re-ranking pipeline that is efficiently and precisely based on discriminative region guidance. Finally, experimental results show that our FoL achieves the state-of-the-art on multiple VPR benchmarks in both image retrieval and re-ranking stages and also significantly outperforms existing two-stage VPR methods in terms of computational efficiency. Code and models are available at https://github.com/chenshunpeng/FoL