 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Paper and Code
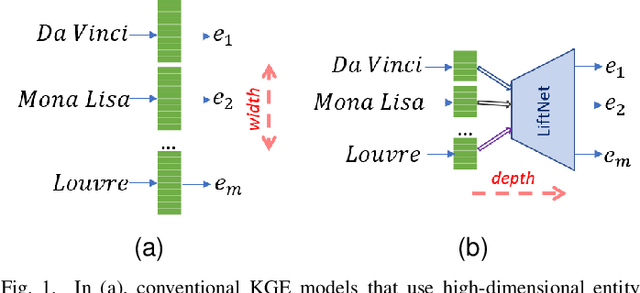
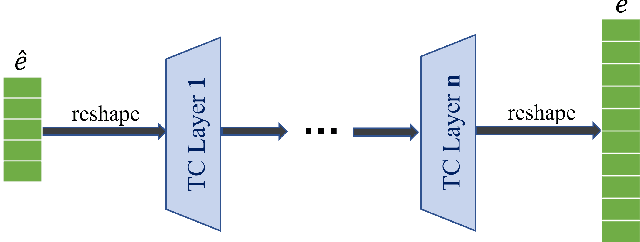
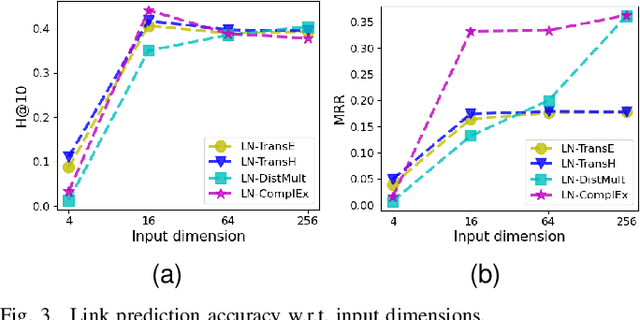
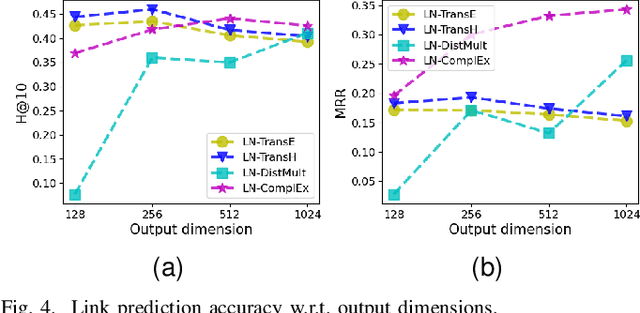
Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream tasks. Conventional KGE methods require relatively high-dimensional entity representations to preserve the structural information of knowledge graph, but lead to oversized model parameters. Recent methods reduce model parameters by adopting low-dimensional entity representations, while developing techniques (e.g., knowledge distillation) to compensate for the reduced dimension. However, such operations produce degraded model accuracy and limited reduction of model parameters. Specifically, we view the concatenation of all entity representations as an embedding layer, and then conventional KGE methods that adopt high-dimensional entity representations equal to enlarging the width of the embedding layer to gain expressiveness. To achieve parameter efficiency without sacrificing accuracy, we instead increase the depth and propose a deeper embedding network for entity representations, i.e., a narrow embedding layer and a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that the proposed method (implemented based on TransE and DistMult) with 4-dimensional entity representations achieves more accurate link prediction results than counterpart parameter-efficient KGE methods and strong KGE baselines, including TransE and DistMult with 512-dimensional entity representations.