 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentinel: Dynamic Knowledge Distillation for Personalized Federated Intrusion Detection in Heterogeneous IoT Networks
Oct 27, 2025Federated learning (FL) offers a privacy-preserving paradigm for machine learning, but its application in intrusion detection systems (IDS) within IoT networks is challenged by severe class imbalance, non-IID data, and high communication overhead.These challenges severely degrade the performance of conventional FL methods in real-world network traffic classification. To overcome these limitations, we propose Sentinel, a personalized federated IDS (pFed-IDS) framework that incorporates a dual-model architecture on each client, consisting of a personalized teacher and a lightweight shared student model. This design effectively balances deep local adaptation with efficient global model consensus while preserving client privacy by transmitting only the compact student model, thus reducing communication costs. Sentinel integrates three key mechanisms to ensure robust performance: bidirectional knowledge distillation with adaptive temperature scaling, multi-faceted feature alignment, and class-balanced loss functions. Furthermore, the server employs normalized gradient aggregation with equal client weighting to enhance fairness and mitigate client drift. Extensive experiments on the IoTID20 and 5GNIDD benchmark datasets demonstrate that Sentinel significantly outperforms state-of-the-art federated methods, establishing a new performance benchmark, especially under extreme data heterogeneity, while maintaining communication efficiency.
Not All Edges are Equally Robust: Evaluating the Robustness of Ranking-Based Federated Learning
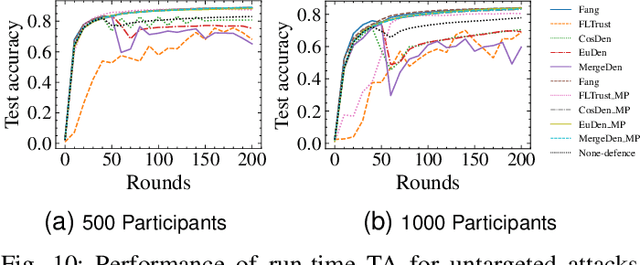
Mar 12, 2025Federated Ranking Learning (FRL) is a state-of-the-art FL framework that stands out for its communication efficiency and resilience to poisoning attacks. It diverges from the traditional FL framework in two ways: 1) it leverages discrete rankings instead of gradient updates, significantly reducing communication costs and limiting the potential space for malicious updates, and 2) it uses majority voting on the server side to establish the global ranking, ensuring that individual updates have minimal influence since each client contributes only a single vote. These features enhance the system's scalability and position FRL as a promising paradigm for FL training. However, our analysis reveals that FRL is not inherently robust, as certain edges are particularly vulnerable to poisoning attacks. Through a theoretical investigation, we prove the existence of these vulnerable edges and establish a lower bound and an upper bound for identifying them in each layer. Based on this finding, we introduce a novel local model poisoning attack against FRL, namely the Vulnerable Edge Manipulation (VEM) attack. The VEM attack focuses on identifying and perturbing the most vulnerable edges in each layer and leveraging an optimization-based approach to maximize the attack's impact. Through extensive experiments on benchmark datasets, we demonstrate that our attack achieves an overall 53.23% attack impact and is 3.7x more impactful than existing methods. Our findings highlight significant vulnerabilities in ranking-based FL systems and underline the urgency for the development of new robust FL frameworks.
A Unified Solution to Diverse Heterogeneities in One-shot Federated Learning
Oct 28, 2024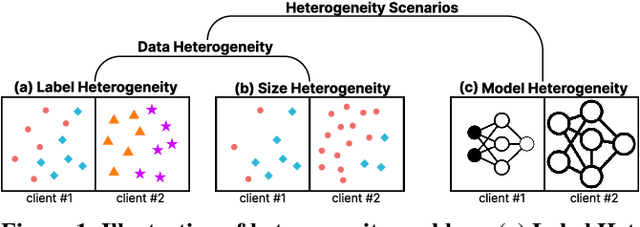

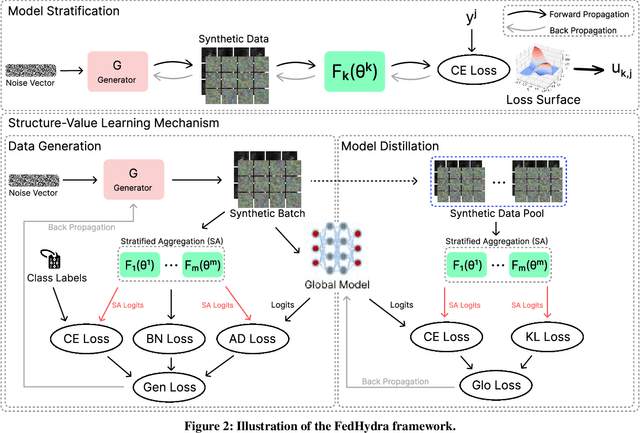
One-shot federated learning (FL) limits the communication between the server and clients to a single round, which largely decreases the privacy leakage risks in traditional FLs requiring multiple communications. However, we find existing one-shot FL frameworks are vulnerable to distributional heterogeneity due to their insufficient focus on data heterogeneity while concentrating predominantly on model heterogeneity. Filling this gap, we propose a unified, data-free, one-shot federated learning framework (FedHydra) that can effectively address both model and data heterogeneity. Rather than applying existing value-only learning mechanisms, a structure-value learning mechanism is proposed in FedHydra. Specifically, a new stratified learning structure is proposed to cover data heterogeneity, and the value of each item during computation reflects model heterogeneity. By this design, the data and model heterogeneity issues are simultaneously monitored from different aspects during learning. Consequently, FedHydra can effectively mitigate both issues by minimizing their inherent conflicts. We compared FedHydra with three SOTA baselines on four benchmark datasets. Experimental results show that our method outperforms the previous one-shot FL methods in both homogeneous and heterogeneous settings.
Data and Model Poisoning Backdoor Attacks on Wireless Federated Learning, and the Defense Mechanisms: A Comprehensive Survey
Dec 14, 2023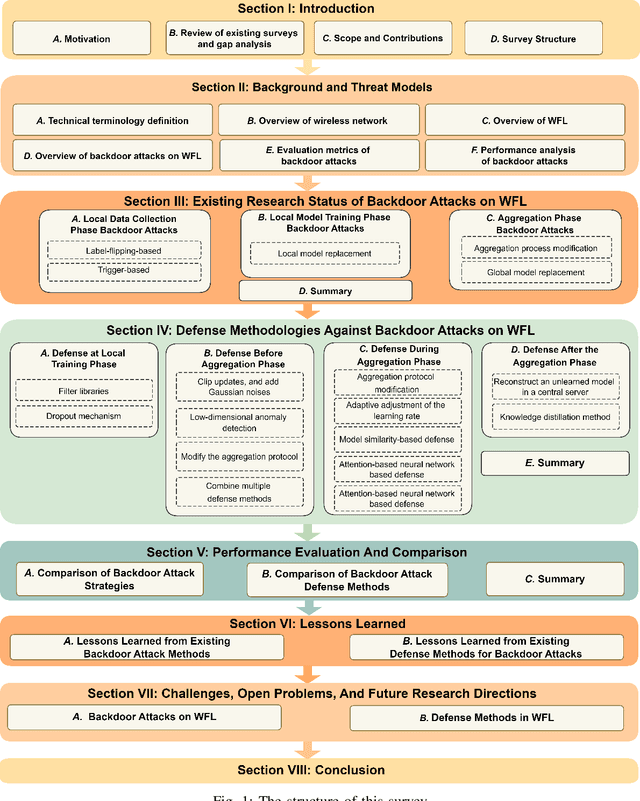
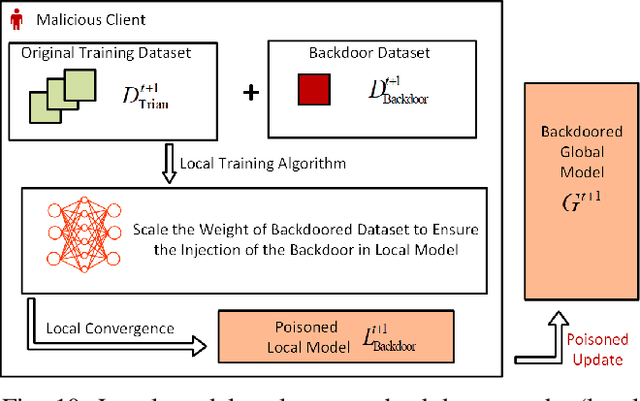
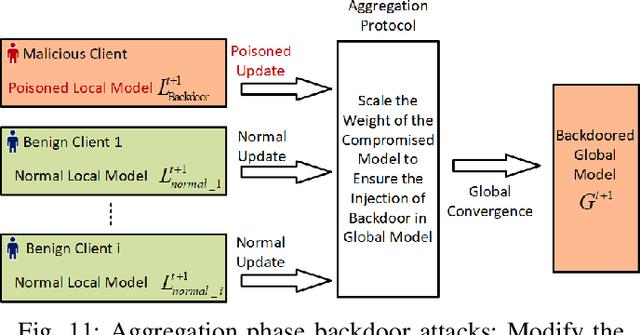
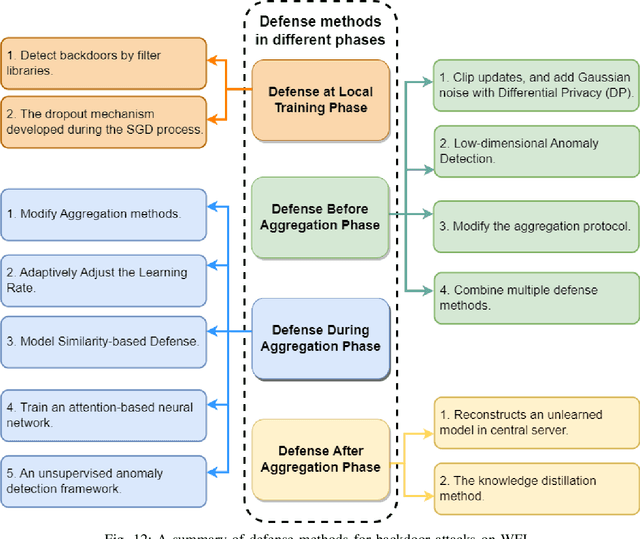
Due to the greatly improved capabilities of devices, massive data, and increasing concern about data privacy, Federated Learning (FL) has been increasingly considered for applications to wireless communication networks (WCNs). Wireless FL (WFL) is a distributed method of training a global deep learning model in which a large number of participants each train a local model on their training datasets and then upload the local model updates to a central server. However, in general, non-independent and identically distributed (non-IID) data of WCNs raises concerns about robustness, as a malicious participant could potentially inject a "backdoor" into the global model by uploading poisoned data or models over WCN. This could cause the model to misclassify malicious inputs as a specific target class while behaving normally with benign inputs. This survey provides a comprehensive review of the latest backdoor attacks and defense mechanisms. It classifies them according to their targets (data poisoning or model poisoning), the attack phase (local data collection, training, or aggregation), and defense stage (local training, before aggregation, during aggregation, or after aggregation). The strengths and limitations of existing attack strategies and defense mechanisms are analyzed in detail. Comparisons of existing attack methods and defense designs are carried out, pointing to noteworthy findings, open challenges, and potential future research directions related to security and privacy of WFL.
AGRAMPLIFIER: Defending Federated Learning Against Poisoning Attacks Through Local Update Amplification
Nov 23, 2023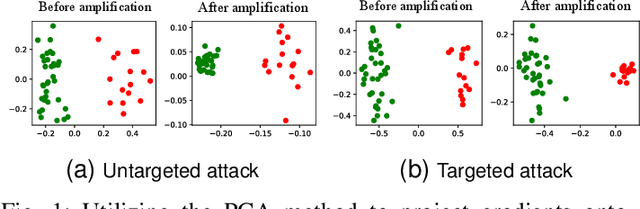


The collaborative nature of federated learning (FL) poses a major threat in the form of manipulation of local training data and local updates, known as the Byzantine poisoning attack. To address this issue, many Byzantine-robust aggregation rules (AGRs) have been proposed to filter out or moderate suspicious local updates uploaded by Byzantine participants. This paper introduces a novel approach called AGRAMPLIFIER, aiming to simultaneously improve the robustness, fidelity, and efficiency of the existing AGRs. The core idea of AGRAMPLIFIER is to amplify the "morality" of local updates by identifying the most repressive features of each gradient update, which provides a clearer distinction between malicious and benign updates, consequently improving the detection effect. To achieve this objective, two approaches, namely AGRMP and AGRXAI, are proposed. AGRMP organizes local updates into patches and extracts the largest value from each patch, while AGRXAI leverages explainable AI methods to extract the gradient of the most activated features. By equipping AGRAMPLIFIER with the existing Byzantine-robust mechanisms, we successfully enhance the model's robustness, maintaining its fidelity and improving overall efficiency. AGRAMPLIFIER is universally compatible with the existing Byzantine-robust mechanisms. The paper demonstrates its effectiveness by integrating it with all mainstream AGR mechanisms. Extensive evaluations conducted on seven datasets from diverse domains against seven representative poisoning attacks consistently show enhancements in robustness, fidelity, and efficiency, with average gains of 40.08%, 39.18%, and 10.68%, respectively.
SS-shapelets: Semi-supervised Clustering of Time Series Using Representative Shapelets
Apr 06, 2023



Shapelets that discriminate time series using local features (subsequences) are promising for time series clustering. Existing time series clustering methods may fail to capture representative shapelets because they discover shapelets from a large pool of uninformative subsequences, and thus result in low clustering accuracy. This paper proposes a Semi-supervised Clustering of Time Series Using Representative Shapelets (SS-Shapelets) method, which utilizes a small number of labeled and propagated pseudo-labeled time series to help discover representative shapelets, thereby improving the clustering accuracy. In SS-Shapelets, we propose two techniques to discover representative shapelets for the effective clustering of time series. 1) A \textit{salient subsequence chain} ($SSC$) that can extract salient subsequences (as candidate shapelets) of a labeled/pseudo-labeled time series, which helps remove massive uninformative subsequences from the pool. 2) A \textit{linear discriminant selection} ($LDS$) algorithm to identify shapelets that can capture representative local features of time series in different classes, for convenient clustering. Experiments on UCR time series datasets demonstrate that SS-shapelets discovers representative shapelets and achieves higher clustering accuracy than counterpart semi-supervised time series clustering methods.
From Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Mar 22, 2023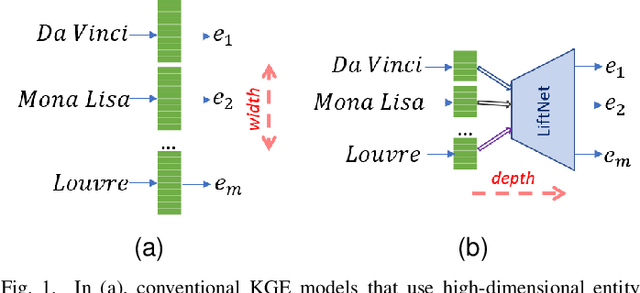
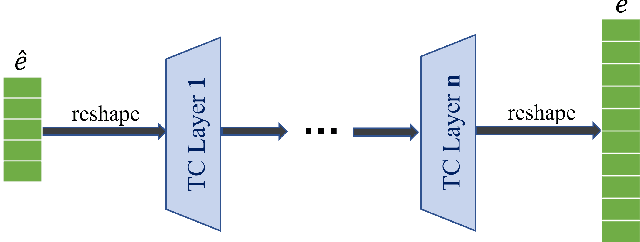
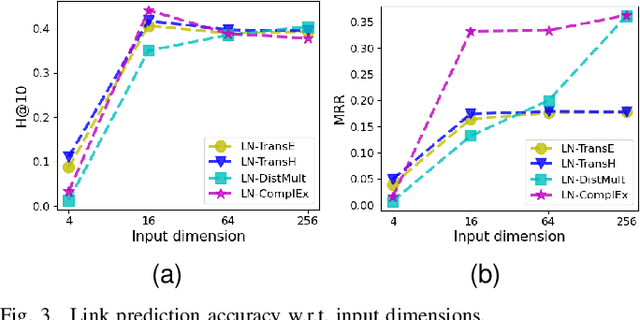
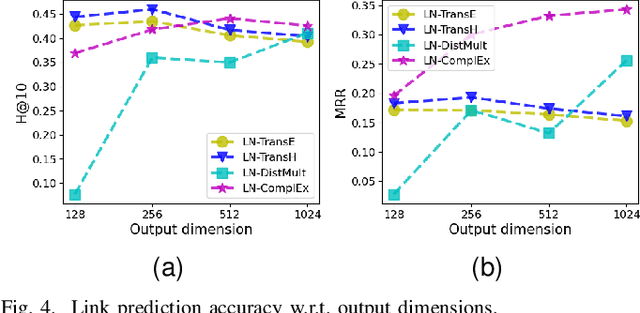
Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream tasks. Conventional KGE methods require relatively high-dimensional entity representations to preserve the structural information of knowledge graph, but lead to oversized model parameters. Recent methods reduce model parameters by adopting low-dimensional entity representations, while developing techniques (e.g., knowledge distillation) to compensate for the reduced dimension. However, such operations produce degraded model accuracy and limited reduction of model parameters. Specifically, we view the concatenation of all entity representations as an embedding layer, and then conventional KGE methods that adopt high-dimensional entity representations equal to enlarging the width of the embedding layer to gain expressiveness. To achieve parameter efficiency without sacrificing accuracy, we instead increase the depth and propose a deeper embedding network for entity representations, i.e., a narrow embedding layer and a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that the proposed method (implemented based on TransE and DistMult) with 4-dimensional entity representations achieves more accurate link prediction results than counterpart parameter-efficient KGE methods and strong KGE baselines, including TransE and DistMult with 512-dimensional entity representations.
Hybrid Variational Autoencoder for Time Series Forecasting
Mar 13, 2023
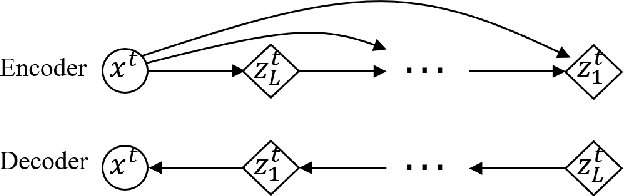
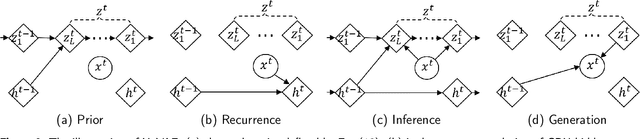
Variational autoencoders (VAE) are powerful generative models that learn the latent representations of input data as random variables. Recent studies show that VAE can flexibly learn the complex temporal dynamics of time series and achieve more promising forecasting results than deterministic models. However, a major limitation of existing works is that they fail to jointly learn the local patterns (e.g., seasonality and trend) and temporal dynamics of time series for forecasting. Accordingly, we propose a novel hybrid variational autoencoder (HyVAE) to integrate the learning of local patterns and temporal dynamics by variational inference for time series forecasting. Experimental results on four real-world datasets show that the proposed HyVAE achieves better forecasting results than various counterpart methods, as well as two HyVAE variants that only learn the local patterns or temporal dynamics of time series, respectively.
Representing Noisy Image Without Denoising
Jan 18, 2023A long-standing topic in artificial intelligence is the effective recognition of patterns from noisy images. In this regard, the recent data-driven paradigm considers 1) improving the representation robustness by adding noisy samples in training phase (i.e., data augmentation) or 2) pre-processing the noisy image by learning to solve the inverse problem (i.e., image denoising). However, such methods generally exhibit inefficient process and unstable result, limiting their practical applications. In this paper, we explore a non-learning paradigm that aims to derive robust representation directly from noisy images, without the denoising as pre-processing. Here, the noise-robust representation is designed as Fractional-order Moments in Radon space (FMR), with also beneficial properties of orthogonality and rotation invariance. Unlike earlier integer-order methods, our work is a more generic design taking such classical methods as special cases, and the introduced fractional-order parameter offers time-frequency analysis capability that is not available in classical methods. Formally, both implicit and explicit paths for constructing the FMR are discussed in detail. Extensive simulation experiments and an image security application are provided to demonstrate the uniqueness and usefulness of our FMR, especially for noise robustness, rotation invariance, and time-frequency discriminability.
An Efficient and Reliable Asynchronous Federated Learning Scheme for Smart Public Transportation
Aug 30, 2022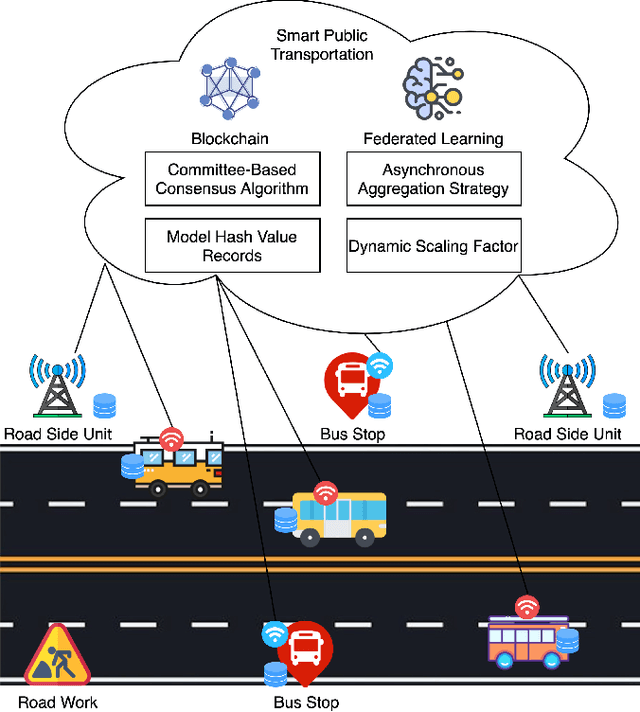
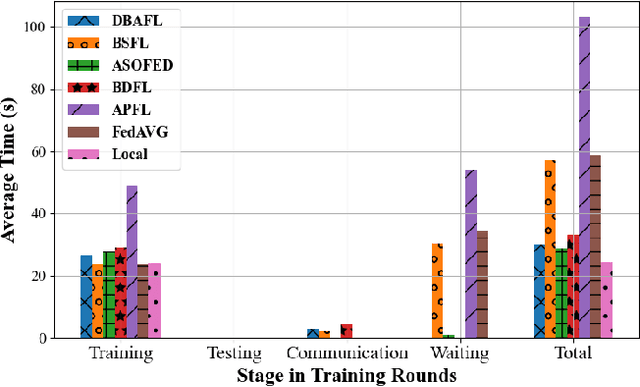
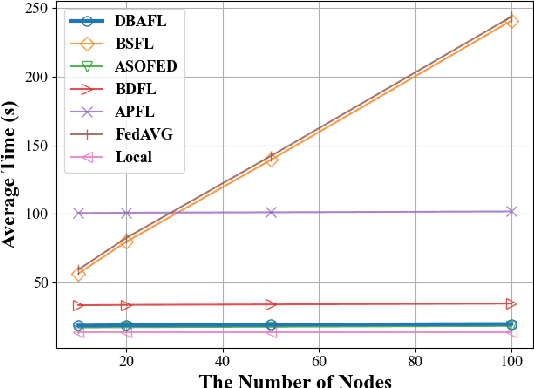
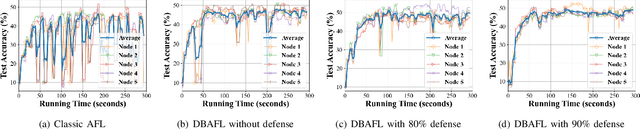
Since the traffic conditions change over time, machine learning models that predict traffic flows must be updated continuously and efficiently in smart public transportation. Federated learning (FL) is a distributed machine learning scheme that allows buses to receive model updates without waiting for model training on the cloud. However, FL is vulnerable to poisoning or DDoS attacks since buses travel in public. Some work introduces blockchain to improve reliability, but the additional latency from the consensus process reduces the efficiency of FL. Asynchronous Federated Learning (AFL) is a scheme that reduces the latency of aggregation to improve efficiency, but the learning performance is unstable due to unreasonably weighted local models. To address the above challenges, this paper offers a blockchain-based asynchronous federated learning scheme with a dynamic scaling factor (DBAFL). Specifically, the novel committee-based consensus algorithm for blockchain improves reliability at the lowest possible cost of time. Meanwhile, the devised dynamic scaling factor allows AFL to assign reasonable weights to stale local models. Extensive experiments conducted on heterogeneous devices validate outperformed learning performance, efficiency, and reliability of DBAFL.