 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Tuning: Wavelet-Decomposed Replay and Semantic Alignment for Continual Adaptation of Pretrained Time-Series Models
Nov 12, 2025Pre-trained models have demonstrated exceptional generalization capabilities in time-series forecasting; however, adapting them to evolving data distributions remains a significant challenge. A key hurdle lies in accessing the original training data, as fine-tuning solely on new data often leads to catastrophic forgetting. To address this issue, we propose Replay Tuning (R-Tuning), a novel framework designed for the continual adaptation of pre-trained time-series models. R-Tuning constructs a unified latent space that captures both prior and current task knowledge through a frequency-aware replay strategy. Specifically, it augments model-generated samples via wavelet-based decomposition across multiple frequency bands, generating trend-preserving and fusion-enhanced variants to improve representation diversity and replay efficiency. To further reduce reliance on synthetic samples, R-Tuning introduces a latent consistency constraint that aligns new representations with the prior task space. This constraint guides joint optimization within a compact and semantically coherent latent space, ensuring robust knowledge retention and adaptation. Extensive experimental results demonstrate the superiority of R-Tuning, which reduces MAE and MSE by up to 46.9% and 46.8%, respectively, on new tasks, while preserving prior knowledge with gains of up to 5.7% and 6.0% on old tasks. Notably, under few-shot settings, R-Tuning outperforms all state-of-the-art baselines even when synthetic proxy samples account for only 5% of the new task dataset.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Apollo-Forecast: Overcoming Aliasing and Inference Speed Challenges in Language Models for Time Series Forecasting
Dec 16, 2024



Encoding time series into tokens and using language models for processing has been shown to substantially augment the models' ability to generalize to unseen tasks. However, existing language models for time series forecasting encounter several obstacles, including aliasing distortion and prolonged inference times, primarily due to the limitations of quantization processes and the computational demands of large models. This paper introduces Apollo-Forecast, a novel framework that tackles these challenges with two key innovations: the Anti-Aliasing Quantization Module (AAQM) and the Race Decoding (RD) technique. AAQM adeptly encodes sequences into tokens while mitigating high-frequency noise in the original signals, thus enhancing both signal fidelity and overall quantization efficiency. RD employs a draft model to enable parallel processing and results integration, which markedly accelerates the inference speed for long-term predictions, particularly in large-scale models. Extensive experiments on various real-world datasets show that Apollo-Forecast outperforms state-of-the-art methods by 35.41\% and 18.99\% in WQL and MASE metrics, respectively, in zero-shot scenarios. Furthermore, our method achieves a 1.9X-2.7X acceleration in inference speed over baseline methods.
Analyzing Multi-Head Attention on Trojan BERT Models
Jun 12, 2024


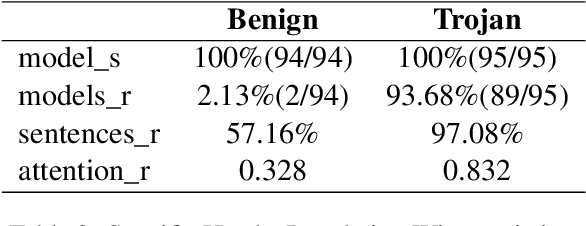
This project investigates the behavior of multi-head attention in Transformer models, specifically focusing on the differences between benign and trojan models in the context of sentiment analysis. Trojan attacks cause models to perform normally on clean inputs but exhibit misclassifications when presented with inputs containing predefined triggers. We characterize attention head functions in trojan and benign models, identifying specific 'trojan' heads and analyzing their behavior.
Hierarchical Large Language Models in Cloud Edge End Architecture for Heterogeneous Robot Cluster Control
Feb 16, 2024


Despite their powerful semantic understanding and code generation capabilities, Large Language Models (LLMs) still face challenges when dealing with complex tasks. Multi agent strategy generation and motion control are highly complex domains that inherently require experts from multiple fields to collaborate. To enhance multi agent strategy generation and motion control, we propose an innovative architecture that employs the concept of a cloud edge end hierarchical structure. By leveraging multiple large language models with distinct areas of expertise, we can efficiently generate strategies and perform task decomposition. Introducing the cosine similarity approach,aligning task decomposition instructions with robot task sequences at the vector level, we can identify subtasks with incomplete task decomposition and iterate on them multiple times to ultimately generate executable machine task sequences.The robot is guided through these task sequences to complete tasks of higher complexity. With this architecture, we implement the process of natural language control of robots to perform complex tasks, and successfully address the challenge of multi agent execution of open tasks in open scenarios and the problem of task decomposition.
AGRAMPLIFIER: Defending Federated Learning Against Poisoning Attacks Through Local Update Amplification
Nov 23, 2023
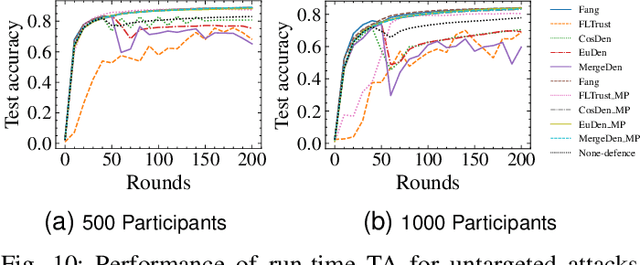


The collaborative nature of federated learning (FL) poses a major threat in the form of manipulation of local training data and local updates, known as the Byzantine poisoning attack. To address this issue, many Byzantine-robust aggregation rules (AGRs) have been proposed to filter out or moderate suspicious local updates uploaded by Byzantine participants. This paper introduces a novel approach called AGRAMPLIFIER, aiming to simultaneously improve the robustness, fidelity, and efficiency of the existing AGRs. The core idea of AGRAMPLIFIER is to amplify the "morality" of local updates by identifying the most repressive features of each gradient update, which provides a clearer distinction between malicious and benign updates, consequently improving the detection effect. To achieve this objective, two approaches, namely AGRMP and AGRXAI, are proposed. AGRMP organizes local updates into patches and extracts the largest value from each patch, while AGRXAI leverages explainable AI methods to extract the gradient of the most activated features. By equipping AGRAMPLIFIER with the existing Byzantine-robust mechanisms, we successfully enhance the model's robustness, maintaining its fidelity and improving overall efficiency. AGRAMPLIFIER is universally compatible with the existing Byzantine-robust mechanisms. The paper demonstrates its effectiveness by integrating it with all mainstream AGR mechanisms. Extensive evaluations conducted on seven datasets from diverse domains against seven representative poisoning attacks consistently show enhancements in robustness, fidelity, and efficiency, with average gains of 40.08%, 39.18%, and 10.68%, respectively.
LogicMP: A Neuro-symbolic Approach for Encoding First-order Logic Constraints
Sep 29, 2023Integrating first-order logic constraints (FOLCs) with neural networks is a crucial but challenging problem since it involves modeling intricate correlations to satisfy the constraints. This paper proposes a novel neural layer, LogicMP, whose layers perform mean-field variational inference over an MLN. It can be plugged into any off-the-shelf neural network to encode FOLCs while retaining modularity and efficiency. By exploiting the structure and symmetries in MLNs, we theoretically demonstrate that our well-designed, efficient mean-field iterations effectively mitigate the difficulty of MLN inference, reducing the inference from sequential calculation to a series of parallel tensor operations. Empirical results in three kinds of tasks over graphs, images, and text show that LogicMP outperforms advanced competitors in both performance and efficiency.
FastATDC: Fast Anomalous Trajectory Detection and Classification
Jul 23, 2022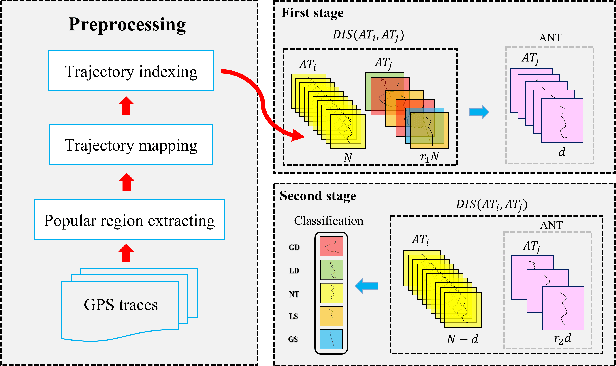
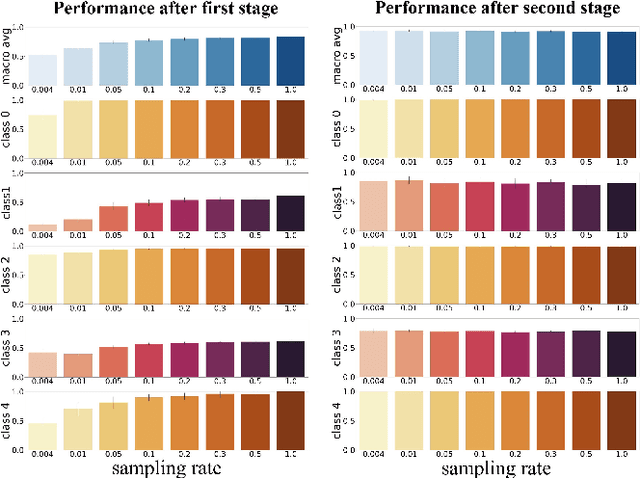
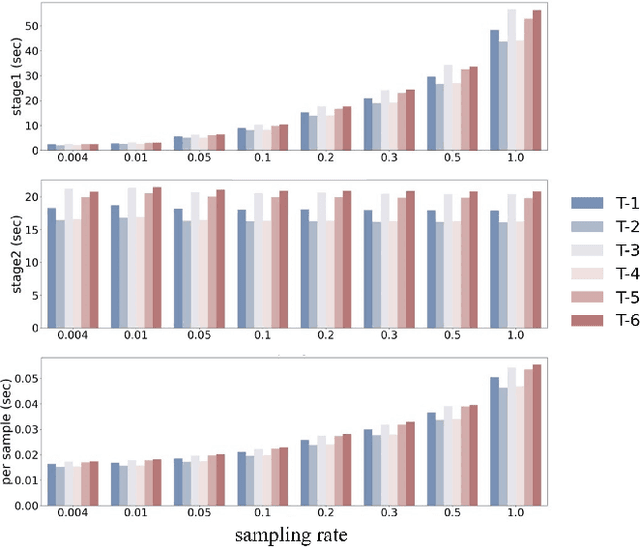

Automated detection of anomalous trajectories is an important problem with considerable applications in intelligent transportation systems. Many existing studies have focused on distinguishing anomalous trajectories from normal trajectories, ignoring the large differences between anomalous trajectories. A recent study has made great progress in identifying abnormal trajectory patterns and proposed a two-stage algorithm for anomalous trajectory detection and classification (ATDC). This algorithm has excellent performance but suffers from a few limitations, such as high time complexity and poor interpretation. Here, we present a careful theoretical and empirical analysis of the ATDC algorithm, showing that the calculation of anomaly scores in both stages can be simplified, and that the second stage of the algorithm is much more important than the first stage. Hence, we develop a FastATDC algorithm that introduces a random sampling strategy in both stages. Experimental results show that FastATDC is 10 to 20 times faster than ATDC on real datasets. Moreover, FastATDC outperforms the baseline algorithms and is comparable to the ATDC algorithm.