 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Tuning: Wavelet-Decomposed Replay and Semantic Alignment for Continual Adaptation of Pretrained Time-Series Models
Nov 12, 2025Pre-trained models have demonstrated exceptional generalization capabilities in time-series forecasting; however, adapting them to evolving data distributions remains a significant challenge. A key hurdle lies in accessing the original training data, as fine-tuning solely on new data often leads to catastrophic forgetting. To address this issue, we propose Replay Tuning (R-Tuning), a novel framework designed for the continual adaptation of pre-trained time-series models. R-Tuning constructs a unified latent space that captures both prior and current task knowledge through a frequency-aware replay strategy. Specifically, it augments model-generated samples via wavelet-based decomposition across multiple frequency bands, generating trend-preserving and fusion-enhanced variants to improve representation diversity and replay efficiency. To further reduce reliance on synthetic samples, R-Tuning introduces a latent consistency constraint that aligns new representations with the prior task space. This constraint guides joint optimization within a compact and semantically coherent latent space, ensuring robust knowledge retention and adaptation. Extensive experimental results demonstrate the superiority of R-Tuning, which reduces MAE and MSE by up to 46.9% and 46.8%, respectively, on new tasks, while preserving prior knowledge with gains of up to 5.7% and 6.0% on old tasks. Notably, under few-shot settings, R-Tuning outperforms all state-of-the-art baselines even when synthetic proxy samples account for only 5% of the new task dataset.
NodeNAS: Node-Specific Graph Neural Architecture Search for Out-of-Distribution Generalization
Mar 06, 2025



Graph neural architecture search (GraphNAS) has demonstrated advantages in mitigating performance degradation of graph neural networks (GNNs) due to distribution shifts. Recent approaches introduce weight sharing across tailored architectures, generating unique GNN architectures for each graph end-to-end. However, existing GraphNAS methods do not account for distribution patterns across different graphs and heavily rely on extensive training data. With sparse or single training graphs, these methods struggle to discover optimal mappings between graphs and architectures, failing to generalize to out-of-distribution (OOD) data. In this paper, we propose node-specific graph neural architecture search(NodeNAS), which aims to tailor distinct aggregation methods for different nodes through disentangling node topology and graph distribution with limited datasets. We further propose adaptive aggregation attention based Multi-dim NodeNAS method(MNNAS), which learns an node-specific architecture customizer with good generalizability. Specifically, we extend the vertical depth of the search space, supporting simultaneous node-specific architecture customization across multiple dimensions. Moreover, we model the power-law distribution of node degrees under varying assortativity, encoding structure invariant information to guide architecture customization across each dimension. Extensive experiments across supervised and unsupervised tasks demonstrate that MNNAS surpasses state-of-the-art algorithms and achieves excellent OOD generalization.
Apollo-Forecast: Overcoming Aliasing and Inference Speed Challenges in Language Models for Time Series Forecasting
Dec 16, 2024



Encoding time series into tokens and using language models for processing has been shown to substantially augment the models' ability to generalize to unseen tasks. However, existing language models for time series forecasting encounter several obstacles, including aliasing distortion and prolonged inference times, primarily due to the limitations of quantization processes and the computational demands of large models. This paper introduces Apollo-Forecast, a novel framework that tackles these challenges with two key innovations: the Anti-Aliasing Quantization Module (AAQM) and the Race Decoding (RD) technique. AAQM adeptly encodes sequences into tokens while mitigating high-frequency noise in the original signals, thus enhancing both signal fidelity and overall quantization efficiency. RD employs a draft model to enable parallel processing and results integration, which markedly accelerates the inference speed for long-term predictions, particularly in large-scale models. Extensive experiments on various real-world datasets show that Apollo-Forecast outperforms state-of-the-art methods by 35.41\% and 18.99\% in WQL and MASE metrics, respectively, in zero-shot scenarios. Furthermore, our method achieves a 1.9X-2.7X acceleration in inference speed over baseline methods.
Synchro-Transient-Extracting Transform for the Analysis of Signals with Both Harmonic and Impulsive Components
Jun 02, 2023



Time-frequency analysis (TFA) techniques play an increasingly important role in the field of machine fault diagnosis attributing to their superiority in dealing with nonstationary signals. Synchroextracting transform (SET) and transient-extracting transform (TET) are two newly emerging techniques that can produce energy concentrated representation for nonstationary signals. However, SET and TET are only suitable for processing harmonic signals and impulsive signals, respectively. This poses a challenge for each of these two techniques when a signal contains both harmonic and impulsive components. In this paper, we propose a new TFA technique to solve this problem. The technique aims to combine the advantages of SET and TET to generate energy concentrated representations for both harmonic and impulsive components of the signal. Furthermore, we theoretically demonstrate that the proposed technique retains the signal reconstruction capability. The effectiveness of the proposed technique is verified using numerical and real-world signals.
FastATDC: Fast Anomalous Trajectory Detection and Classification
Jul 23, 2022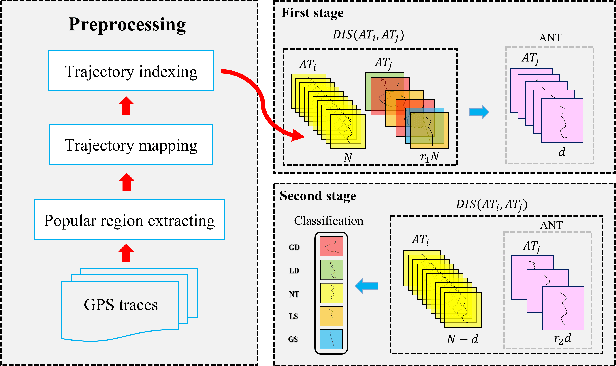
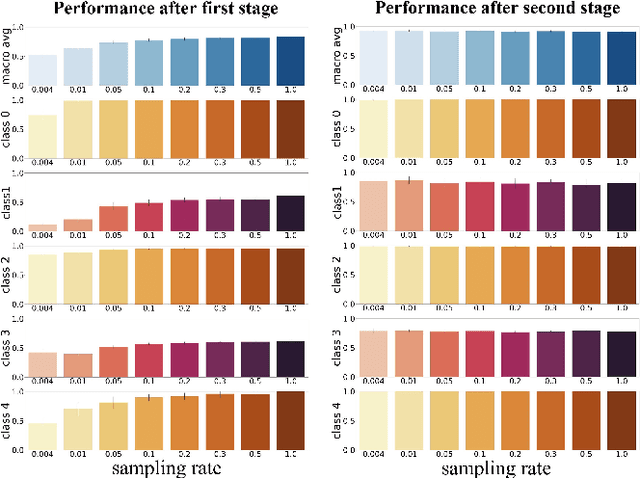
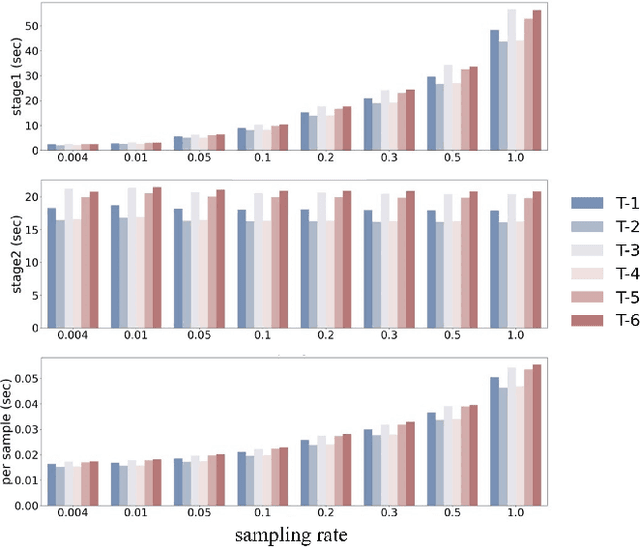

Automated detection of anomalous trajectories is an important problem with considerable applications in intelligent transportation systems. Many existing studies have focused on distinguishing anomalous trajectories from normal trajectories, ignoring the large differences between anomalous trajectories. A recent study has made great progress in identifying abnormal trajectory patterns and proposed a two-stage algorithm for anomalous trajectory detection and classification (ATDC). This algorithm has excellent performance but suffers from a few limitations, such as high time complexity and poor interpretation. Here, we present a careful theoretical and empirical analysis of the ATDC algorithm, showing that the calculation of anomaly scores in both stages can be simplified, and that the second stage of the algorithm is much more important than the first stage. Hence, we develop a FastATDC algorithm that introduces a random sampling strategy in both stages. Experimental results show that FastATDC is 10 to 20 times faster than ATDC on real datasets. Moreover, FastATDC outperforms the baseline algorithms and is comparable to the ATDC algorithm.
SdcNet: A Computation-Efficient CNN for Object Recognition
May 05, 2018

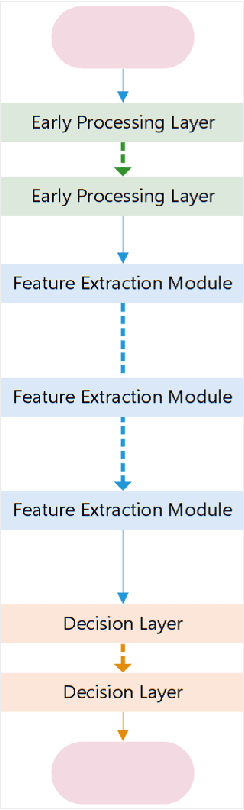
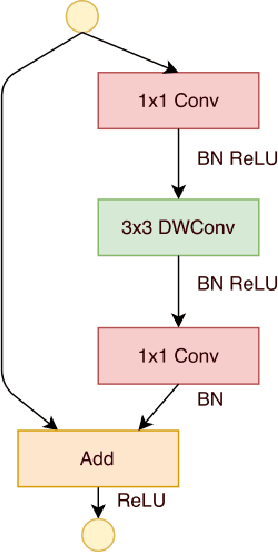
Extracting features from a huge amount of data for object recognition is a challenging task. Convolution neural network can be used to meet the challenge, but it often requires a large number of computation resources. In this paper, a computation-efficient convolutional module, named SdcBlock, is proposed and based on it, the convolution network SdcNet is introduced for object recognition tasks. In the proposed module, optimized successive depthwise convolutions supported by appropriate data management is applied in order to generate vectors containing high density and more varieties of feature information. The hyperparameters can be easily adjusted to suit varieties of tasks under different computation restrictions without significantly jeopardizing the performance. The experiments have shown that SdcNet achieved an error rate of 5.60% in CIFAR-10 with only 55M Flops and also reduced further the error rate to 5.24% using a moderate volume of 103M Flops. The expected computation efficiency of the SdcNet has been confirmed.