 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing is Believing: Robust Vision-Guided Cross-Modal Prompt Learning under Label Noise
Apr 10, 2026Prompt learning is a parameter-efficient approach for vision-language models, yet its robustness under label noise is less investigated. Visual content contains richer and more reliable semantic information, which remains more robust under label noise. However, the prompt itself is highly susceptible to label noise. Motivated by this intuition, we propose VisPrompt, a lightweight and robust vision-guided prompt learning framework for noisy-label settings. Specifically, we exploit a cross-modal attention mechanism to reversely inject visual semantics into prompt representations. This enables the prompt tokens to selectively aggregate visual information relevant to the current sample, thereby improving robustness by anchoring prompt learning to stable instance-level visual evidence and reducing the influence of noisy supervision. To address the instability caused by using the same way of injecting visual information for all samples, despite differences in the quality of their visual cues, we further introduce a lightweight conditional modulation mechanism to adaptively control the strength of visual information injection, which strikes a more robust balance between text-side semantic priors and image-side instance evidence. The proposed framework effectively suppresses the noise-induced disturbances, reduce instability in prompt updates, and alleviate memorization of mislabeled samples. VisPrompt significantly improves robustness while keeping the pretrained VLM backbone frozen and introducing only a small amount of additional trainable parameters. Extensive experiments under synthetic and real-world label noise demonstrate that VisPrompt generally outperforms existing baselines on seven benchmark datasets and achieves stronger robustness. Our code is publicly available at https://github.com/gezbww/Vis_Prompt.
Unsupervised MR-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
Feb 16, 2026Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on Multilevel Correlation Pyramidal Optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is available at https://github.com/wjiazheng/MCPO.
Red-teaming the Multimodal Reasoning: Jailbreaking Vision-Language Models via Cross-modal Entanglement Attacks
Feb 09, 2026Vision-Language Models (VLMs) with multimodal reasoning capabilities are high-value attack targets, given their potential for handling complex multimodal harmful tasks. Mainstream black-box jailbreak attacks on VLMs work by distributing malicious clues across modalities to disperse model attention and bypass safety alignment mechanisms. However, these adversarial attacks rely on simple and fixed image-text combinations that lack attack complexity scalability, limiting their effectiveness for red-teaming VLMs' continuously evolving reasoning capabilities. We propose \textbf{CrossTALK} (\textbf{\underline{Cross}}-modal en\textbf{\underline{TA}}ng\textbf{\underline{L}}ement attac\textbf{\underline{K}}), which is a scalable approach that extends and entangles information clues across modalities to exceed VLMs' trained and generalized safety alignment patterns for jailbreak. Specifically, {knowledge-scalable reframing} extends harmful tasks into multi-hop chain instructions, {cross-modal clue entangling} migrates visualizable entities into images to build multimodal reasoning links, and {cross-modal scenario nesting} uses multimodal contextual instructions to steer VLMs toward detailed harmful outputs. Experiments show our COMET achieves state-of-the-art attack success rate.
Unsupervised MRI-US Multimodal Image Registration with Multilevel Correlation Pyramidal Optimization
Feb 06, 2026Surgical navigation based on multimodal image registration has played a significant role in providing intraoperative guidance to surgeons by showing the relative position of the target area to critical anatomical structures during surgery. However, due to the differences between multimodal images and intraoperative image deformation caused by tissue displacement and removal during the surgery, effective registration of preoperative and intraoperative multimodal images faces significant challenges. To address the multimodal image registration challenges in Learn2Reg 2025, an unsupervised multimodal medical image registration method based on multilevel correlation pyramidal optimization (MCPO) is designed to solve these problems. First, the features of each modality are extracted based on the modality independent neighborhood descriptor, and the multimodal images is mapped to the feature space. Second, a multilevel pyramidal fusion optimization mechanism is designed to achieve global optimization and local detail complementation of the displacement field through dense correlation analysis and weight-balanced coupled convex optimization for input features at different scales. Our method focuses on the ReMIND2Reg task in Learn2Reg 2025. Based on the results, our method achieved the first place in the validation phase and test phase of ReMIND2Reg. The MCPO is also validated on the Resect dataset, achieving an average TRE of 1.798 mm. This demonstrates the broad applicability of our method in preoperative-to-intraoperative image registration. The code is avaliable at https://github.com/wjiazheng/MCPO.
Reg-TTR, Test-Time Refinement for Fast, Robust and Accurate Image Registration
Jan 27, 2026Traditional image registration methods are robust but slow due to their iterative nature. While deep learning has accelerated inference, it often struggles with domain shifts. Emerging registration foundation models offer a balance of speed and robustness, yet typically cannot match the peak accuracy of specialized models trained on specific datasets. To mitigate this limitation, we propose Reg-TTR, a test-time refinement framework that synergizes the complementary strengths of both deep learning and conventional registration techniques. By refining the predictions of pre-trained models at inference, our method delivers significantly improved registration accuracy at a modest computational cost, requiring only 21% additional inference time (0.56s). We evaluate Reg-TTR on two distinct tasks and show that it achieves state-of-the-art (SOTA) performance while maintaining inference speeds close to previous deep learning methods. As foundation models continue to emerge, our framework offers an efficient strategy to narrow the performance gap between registration foundation models and SOTA methods trained on specialized datasets. The source code will be publicly available following the acceptance of this work.
A Step to Decouple Optimization in 3DGS
Jan 26, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time novel view synthesis. As an explicit representation optimized through gradient propagation among primitives, optimization widely accepted in deep neural networks (DNNs) is actually adopted in 3DGS, such as synchronous weight updating and Adam with the adaptive gradient. However, considering the physical significance and specific design in 3DGS, there are two overlooked details in the optimization of 3DGS: (i) update step coupling, which induces optimizer state rescaling and costly attribute updates outside the viewpoints, and (ii) gradient coupling in the moment, which may lead to under- or over-effective regularization. Nevertheless, such a complex coupling is under-explored. After revisiting the optimization of 3DGS, we take a step to decouple it and recompose the process into: Sparse Adam, Re-State Regularization and Decoupled Attribute Regularization. Taking a large number of experiments under the 3DGS and 3DGS-MCMC frameworks, our work provides a deeper understanding of these components. Finally, based on the empirical analysis, we re-design the optimization and propose AdamW-GS by re-coupling the beneficial components, under which better optimization efficiency and representation effectiveness are achieved simultaneously.
SearchAttack: Red-Teaming LLMs against Real-World Threats via Framing Unsafe Web Information-Seeking Tasks
Jan 07, 2026Recently, people have suffered and become increasingly aware of the unreliability gap in LLMs for open and knowledge-intensive tasks, and thus turn to search-augmented LLMs to mitigate this issue. However, when the search engine is triggered for harmful tasks, the outcome is no longer under the LLM's control. Once the returned content directly contains targeted, ready-to-use harmful takeaways, the LLM's safeguards cannot withdraw that exposure. Motivated by this dilemma, we identify web search as a critical attack surface and propose \textbf{\textit{SearchAttack}} for red-teaming. SearchAttack outsources the harmful semantics to web search, retaining only the query's skeleton and fragmented clues, and further steers LLMs to reconstruct the retrieved content via structural rubrics to achieve malicious goals. Extensive experiments are conducted to red-team the search-augmented LLMs for responsible vulnerability assessment. Empirically, SearchAttack demonstrates strong effectiveness in attacking these systems.
R-Tuning: Wavelet-Decomposed Replay and Semantic Alignment for Continual Adaptation of Pretrained Time-Series Models
Nov 12, 2025Pre-trained models have demonstrated exceptional generalization capabilities in time-series forecasting; however, adapting them to evolving data distributions remains a significant challenge. A key hurdle lies in accessing the original training data, as fine-tuning solely on new data often leads to catastrophic forgetting. To address this issue, we propose Replay Tuning (R-Tuning), a novel framework designed for the continual adaptation of pre-trained time-series models. R-Tuning constructs a unified latent space that captures both prior and current task knowledge through a frequency-aware replay strategy. Specifically, it augments model-generated samples via wavelet-based decomposition across multiple frequency bands, generating trend-preserving and fusion-enhanced variants to improve representation diversity and replay efficiency. To further reduce reliance on synthetic samples, R-Tuning introduces a latent consistency constraint that aligns new representations with the prior task space. This constraint guides joint optimization within a compact and semantically coherent latent space, ensuring robust knowledge retention and adaptation. Extensive experimental results demonstrate the superiority of R-Tuning, which reduces MAE and MSE by up to 46.9% and 46.8%, respectively, on new tasks, while preserving prior knowledge with gains of up to 5.7% and 6.0% on old tasks. Notably, under few-shot settings, R-Tuning outperforms all state-of-the-art baselines even when synthetic proxy samples account for only 5% of the new task dataset.
Mono3DVG-EnSD: Enhanced Spatial-aware and Dimension-decoupled Text Encoding for Monocular 3D Visual Grounding
Nov 10, 2025Monocular 3D Visual Grounding (Mono3DVG) is an emerging task that locates 3D objects in RGB images using text descriptions with geometric cues. However, existing methods face two key limitations. Firstly, they often over-rely on high-certainty keywords that explicitly identify the target object while neglecting critical spatial descriptions. Secondly, generalized textual features contain both 2D and 3D descriptive information, thereby capturing an additional dimension of details compared to singular 2D or 3D visual features. This characteristic leads to cross-dimensional interference when refining visual features under text guidance. To overcome these challenges, we propose Mono3DVG-EnSD, a novel framework that integrates two key components: the CLIP-Guided Lexical Certainty Adapter (CLIP-LCA) and the Dimension-Decoupled Module (D2M). The CLIP-LCA dynamically masks high-certainty keywords while retaining low-certainty implicit spatial descriptions, thereby forcing the model to develop a deeper understanding of spatial relationships in captions for object localization. Meanwhile, the D2M decouples dimension-specific (2D/3D) textual features from generalized textual features to guide corresponding visual features at same dimension, which mitigates cross-dimensional interference by ensuring dimensionally-consistent cross-modal interactions. Through comprehensive comparisons and ablation studies on the Mono3DRefer dataset, our method achieves state-of-the-art (SOTA) performance across all metrics. Notably, it improves the challenging Far(Acc@0.5) scenario by a significant +13.54%.
A Dual-stage Prompt-driven Privacy-preserving Paradigm for Person Re-Identification
Nov 07, 2025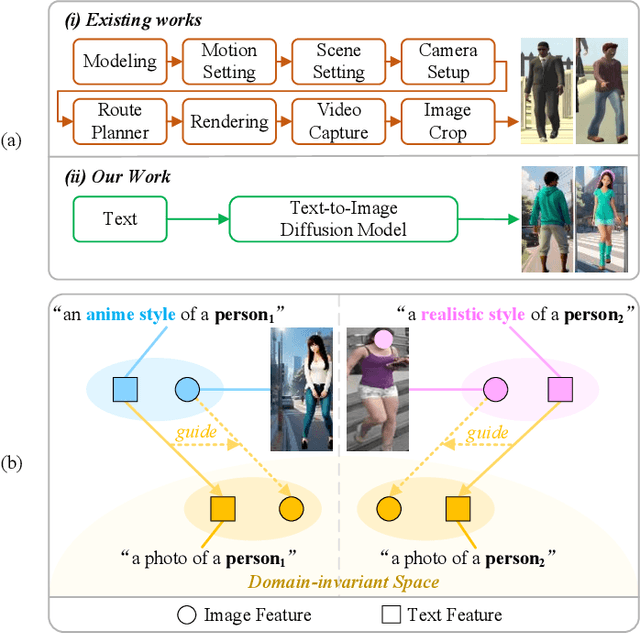
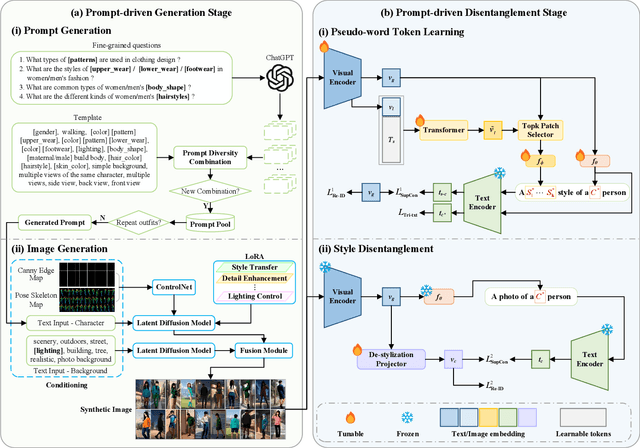
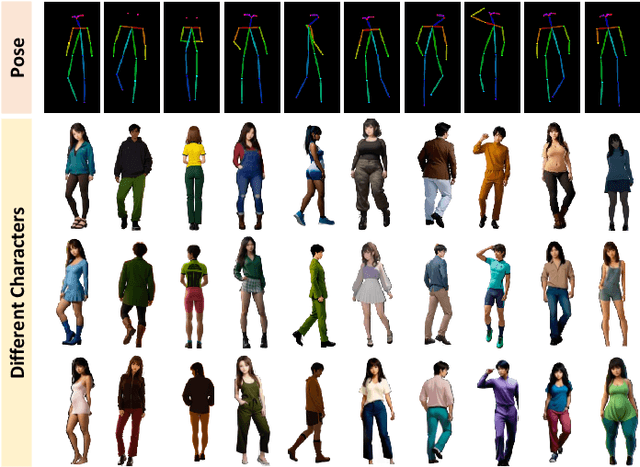

With growing concerns over data privacy, researchers have started using virtual data as an alternative to sensitive real-world images for training person re-identification (Re-ID) models. However, existing virtual datasets produced by game engines still face challenges such as complex construction and poor domain generalization, making them difficult to apply in real scenarios. To address these challenges, we propose a Dual-stage Prompt-driven Privacy-preserving Paradigm (DPPP). In the first stage, we generate rich prompts incorporating multi-dimensional attributes such as pedestrian appearance, illumination, and viewpoint that drive the diffusion model to synthesize diverse data end-to-end, building a large-scale virtual dataset named GenePerson with 130,519 images of 6,641 identities. In the second stage, we propose a Prompt-driven Disentanglement Mechanism (PDM) to learn domain-invariant generalization features. With the aid of contrastive learning, we employ two textual inversion networks to map images into pseudo-words representing style and content, respectively, thereby constructing style-disentangled content prompts to guide the model in learning domain-invariant content features at the image level. Experiments demonstrate that models trained on GenePerson with PDM achieve state-of-the-art generalization performance, surpassing those on popular real and virtual Re-ID datasets.