 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVNet: Point-Voxel Interaction LiDAR Scene Upsampling Via Diffusion Models
Aug 23, 2025Accurate 3D scene understanding in outdoor environments heavily relies on high-quality point clouds. However, LiDAR-scanned data often suffer from extreme sparsity, severely hindering downstream 3D perception tasks. Existing point cloud upsampling methods primarily focus on individual objects, thus demonstrating limited generalization capability for complex outdoor scenes. To address this issue, we propose PVNet, a diffusion model-based point-voxel interaction framework to perform LiDAR point cloud upsampling without dense supervision. Specifically, we adopt the classifier-free guidance-based DDPMs to guide the generation, in which we employ a sparse point cloud as the guiding condition and the synthesized point clouds derived from its nearby frames as the input. Moreover, we design a voxel completion module to refine and complete the coarse voxel features for enriching the feature representation. In addition, we propose a point-voxel interaction module to integrate features from both points and voxels, which efficiently improves the environmental perception capability of each upsampled point. To the best of our knowledge, our approach is the first scene-level point cloud upsampling method supporting arbitrary upsampling rates. Extensive experiments on various benchmarks demonstrate that our method achieves state-of-the-art performance. The source code will be available at https://github.com/chengxianjing/PVNet.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025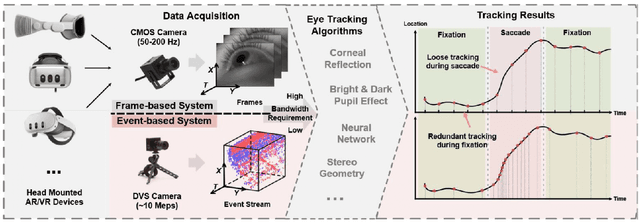
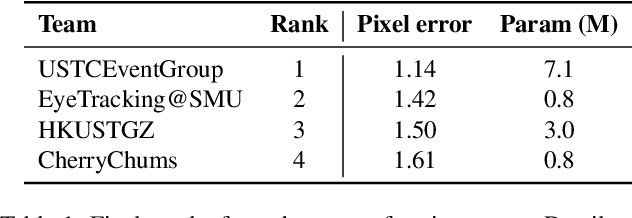
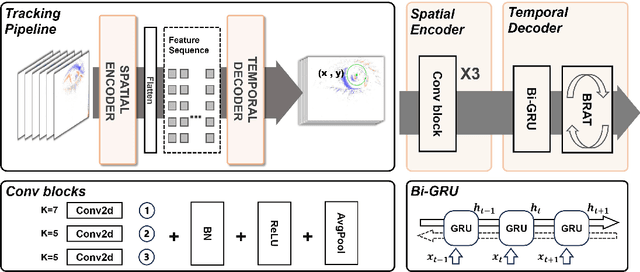

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Text-to-Events: Synthetic Event Camera Streams from Conditional Text Input
Jun 05, 2024Event cameras are advantageous for tasks that require vision sensors with low-latency and sparse output responses. However, the development of deep network algorithms using event cameras has been slow because of the lack of large labelled event camera datasets for network training. This paper reports a method for creating new labelled event datasets by using a text-to-X model, where X is one or multiple output modalities, in the case of this work, events. Our proposed text-to-events model produces synthetic event frames directly from text prompts. It uses an autoencoder which is trained to produce sparse event frames representing event camera outputs. By combining the pretrained autoencoder with a diffusion model architecture, the new text-to-events model is able to generate smooth synthetic event streams of moving objects. The autoencoder was first trained on an event camera dataset of diverse scenes. In the combined training with the diffusion model, the DVS gesture dataset was used. We demonstrate that the model can generate realistic event sequences of human gestures prompted by different text statements. The classification accuracy of the generated sequences, using a classifier trained on the real dataset, ranges between 42% to 92%, depending on the gesture group. The results demonstrate the capability of this method in synthesizing event datasets.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024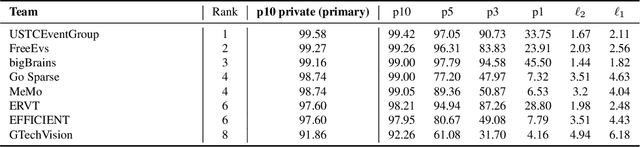
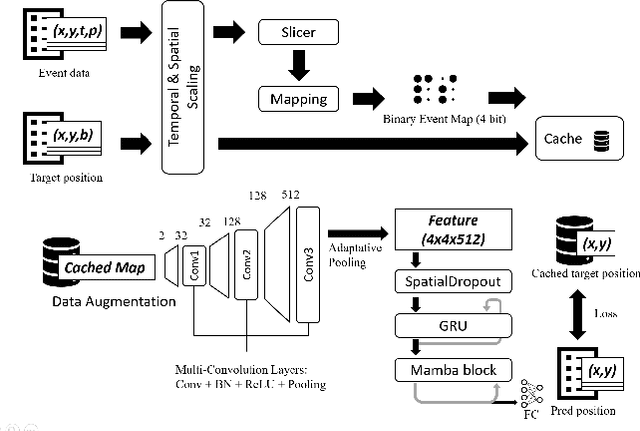
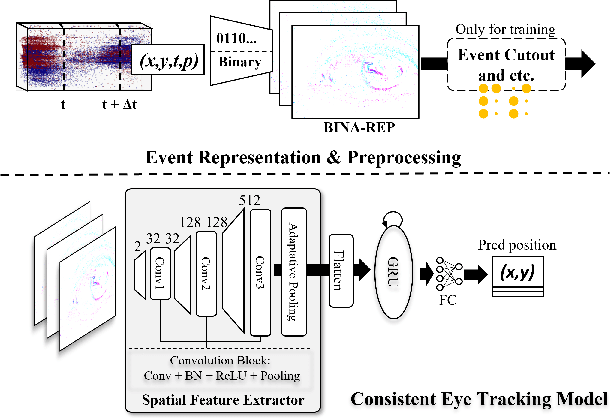

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.
3ET: Efficient Event-based Eye Tracking using a Change-Based ConvLSTM Network
Aug 22, 2023This paper presents a sparse Change-Based Convolutional Long Short-Term Memory (CB-ConvLSTM) model for event-based eye tracking, key for next-generation wearable healthcare technology such as AR/VR headsets. We leverage the benefits of retina-inspired event cameras, namely their low-latency response and sparse output event stream, over traditional frame-based cameras. Our CB-ConvLSTM architecture efficiently extracts spatio-temporal features for pupil tracking from the event stream, outperforming conventional CNN structures. Utilizing a delta-encoded recurrent path enhancing activation sparsity, CB-ConvLSTM reduces arithmetic operations by approximately 4.7$\times$ without losing accuracy when tested on a \texttt{v2e}-generated event dataset of labeled pupils. This increase in efficiency makes it ideal for real-time eye tracking in resource-constrained devices. The project code and dataset are openly available at \url{https://github.com/qinche106/cb-convlstm-eyetracking}.
Exploiting Spatial Sparsity for Event Cameras with Visual Transformers
Feb 10, 2022



Event cameras report local changes of brightness through an asynchronous stream of output events. Events are spatially sparse at pixel locations with little brightness variation. We propose using a visual transformer (ViT) architecture to leverage its ability to process a variable-length input. The input to the ViT consists of events that are accumulated into time bins and spatially separated into non-overlapping sub-regions called patches. Patches are selected when the number of nonzero pixel locations within a sub-region is above a threshold. We show that by fine-tuning a ViT model on the selected active patches, we can reduce the average number of patches fed into the backbone during the inference by at least 50% with only a minor drop (0.34%) of the classification accuracy on the N-Caltech101 dataset. This reduction translates into a decrease of 51% in Multiply-Accumulate (MAC) operations and an increase of 46% in the inference speed using a server CPU.
Understanding (Non-)Robust Feature Disentanglement and the Relationship Between Low- and High-Dimensional Adversarial Attacks
Apr 04, 2020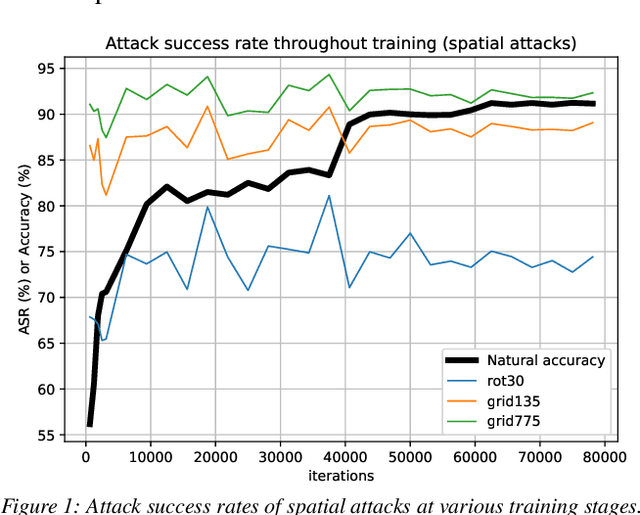
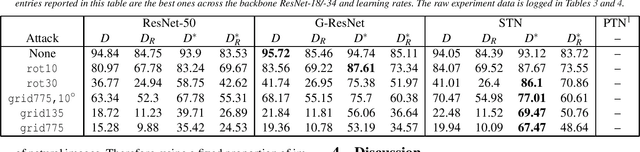
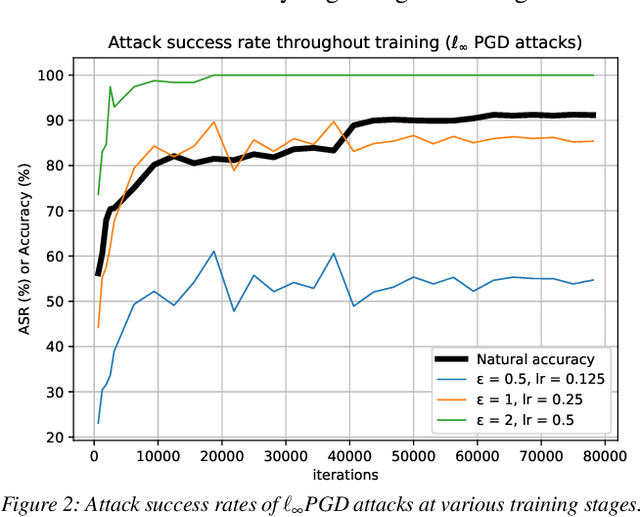

Recent work has put forth the hypothesis that adversarial vulnerabilities in neural networks are due to them overusing "non-robust features" inherent in the training data. We show empirically that for PGD-attacks, there is a training stage where neural networks start heavily relying on non-robust features to boost natural accuracy. We also propose a mechanism reducing vulnerability to PGD-style attacks consisting of mixing in a certain amount of images contain-ing mostly "robust features" into each training batch, and then show that robust accuracy is improved, while natural accuracy is not substantially hurt. We show that training on "robust features" provides boosts in robust accuracy across various architectures and for different attacks. Finally, we demonstrate empirically that these "robust features" do not induce spatial invariance.
Invariance-inducing regularization using worst-case transformations suffices to boost accuracy and spatial robustness
Jun 26, 2019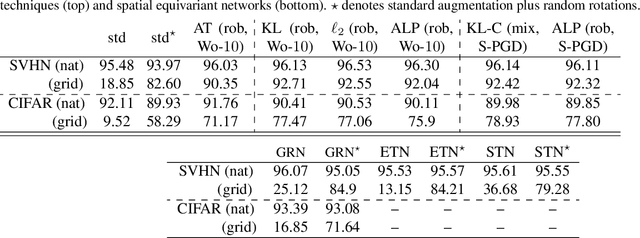

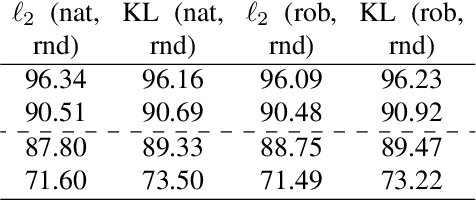
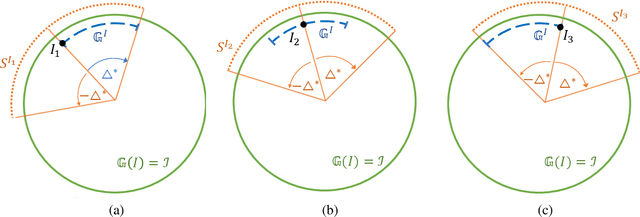
This work provides theoretical and empirical evidence that invariance-inducing regularizers can increase predictive accuracy for worst-case spatial transformations (spatial robustness). Evaluated on these adversarially transformed examples, we demonstrate that adding regularization on top of standard or adversarial training reduces the relative error by 20% for CIFAR10 without increasing the computational cost. This outperforms handcrafted networks that were explicitly designed to be spatial-equivariant. Furthermore, we observe for SVHN, known to have inherent variance in orientation, that robust training also improves standard accuracy on the test set. We prove that this no-trade-off phenomenon holds for adversarial examples from transformation groups in the infinite data limit.