 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Abstractive Processing for Retrieval in Dynamic Datasets
Oct 02, 2024



Recent retrieval-augmented models enhance basic methods by building a hierarchical structure over retrieved text chunks through recursive embedding, clustering, and summarization. The most relevant information is then retrieved from both the original text and generated summaries. However, such approaches face limitations with dynamic datasets, where adding or removing documents over time complicates the updating of hierarchical representations formed through clustering. We propose a new algorithm to efficiently maintain the recursive-abstractive tree structure in dynamic datasets, without compromising performance. Additionally, we introduce a novel post-retrieval method that applies query-focused recursive abstractive processing to substantially improve context quality. Our method overcomes the limitations of other approaches by functioning as a black-box post-retrieval layer compatible with any retrieval algorithm. Both algorithms are validated through extensive experiments on real-world datasets, demonstrating their effectiveness in handling dynamic data and improving retrieval performance.
Text-to-Events: Synthetic Event Camera Streams from Conditional Text Input
Jun 05, 2024Event cameras are advantageous for tasks that require vision sensors with low-latency and sparse output responses. However, the development of deep network algorithms using event cameras has been slow because of the lack of large labelled event camera datasets for network training. This paper reports a method for creating new labelled event datasets by using a text-to-X model, where X is one or multiple output modalities, in the case of this work, events. Our proposed text-to-events model produces synthetic event frames directly from text prompts. It uses an autoencoder which is trained to produce sparse event frames representing event camera outputs. By combining the pretrained autoencoder with a diffusion model architecture, the new text-to-events model is able to generate smooth synthetic event streams of moving objects. The autoencoder was first trained on an event camera dataset of diverse scenes. In the combined training with the diffusion model, the DVS gesture dataset was used. We demonstrate that the model can generate realistic event sequences of human gestures prompted by different text statements. The classification accuracy of the generated sequences, using a classifier trained on the real dataset, ranges between 42% to 92%, depending on the gesture group. The results demonstrate the capability of this method in synthesizing event datasets.
Biologically-Inspired Continual Learning of Human Motion Sequences
Nov 02, 2022This work proposes a model for continual learning on tasks involving temporal sequences, specifically, human motions. It improves on a recently proposed brain-inspired replay model (BI-R) by building a biologically-inspired conditional temporal variational autoencoder (BI-CTVAE), which instantiates a latent mixture-of-Gaussians for class representation. We investigate a novel continual-learning-to-generate (CL2Gen) scenario where the model generates motion sequences of different classes. The generative accuracy of the model is tested over a set of tasks. The final classification accuracy of BI-CTVAE on a human motion dataset after sequentially learning all action classes is 78%, which is 63% higher than using no-replay, and only 5.4% lower than a state-of-the-art offline trained GRU model.
Recurrent Neural Networks With Limited Numerical Precision
Feb 26, 2017

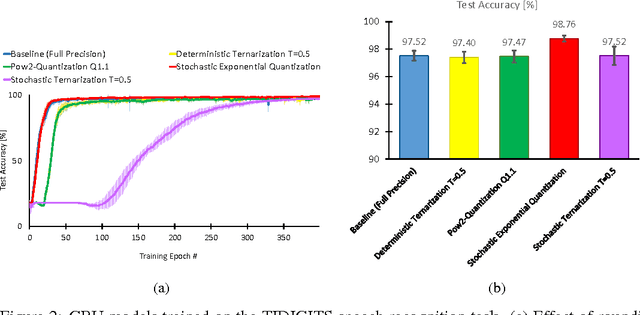
Recurrent Neural Networks (RNNs) produce state-of-art performance on many machine learning tasks but their demand on resources in terms of memory and computational power are often high. Therefore, there is a great interest in optimizing the computations performed with these models especially when considering development of specialized low-power hardware for deep networks. One way of reducing the computational needs is to limit the numerical precision of the network weights and biases, and this will be addressed for the case of RNNs. We present results from the use of different stochastic and deterministic reduced precision training methods applied to two major RNN types, which are then tested on three datasets. The results show that the stochastic and deterministic ternarization, pow2- ternarization, and exponential quantization methods gave rise to low-precision RNNs that produce similar and even higher accuracy on certain datasets, therefore providing a path towards training more efficient implementations of RNNs in specialized hardware.