 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning aligns language models to human cognition
Feb 09, 2026Do language models make decisions under uncertainty like humans do, and what role does chain-of-thought (CoT) reasoning play in the underlying decision process? We introduce an active probabilistic reasoning task that cleanly separates sampling (actively acquiring evidence) from inference (integrating evidence toward a decision). Benchmarking humans and a broad set of contemporary large language models against near-optimal reference policies reveals a consistent pattern: extended reasoning is the key determinant of strong performance, driving large gains in inference and producing belief trajectories that become strikingly human-like, while yielding only modest improvements in active sampling. To explain these differences, we fit a mechanistic model that captures systematic deviations from optimal behavior via four interpretable latent variables: memory, strategy, choice bias, and occlusion awareness. This model places humans and models in a shared low-dimensional cognitive space, reproduces behavioral signatures across agents, and shows how chain-of-thought shifts language models toward human-like regimes of evidence accumulation and belief-to-choice mapping, tightening alignment in inference while leaving a persistent gap in information acquisition.
Modulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
Nov 04, 2024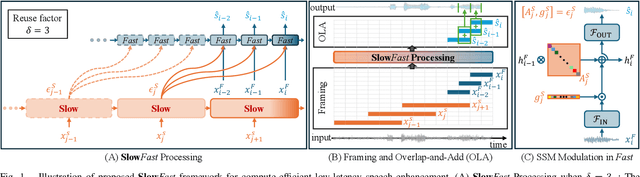
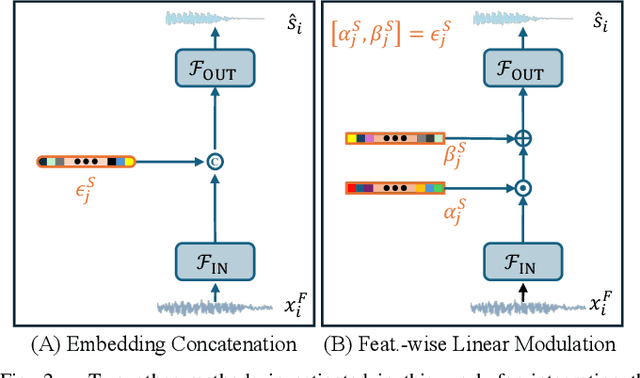
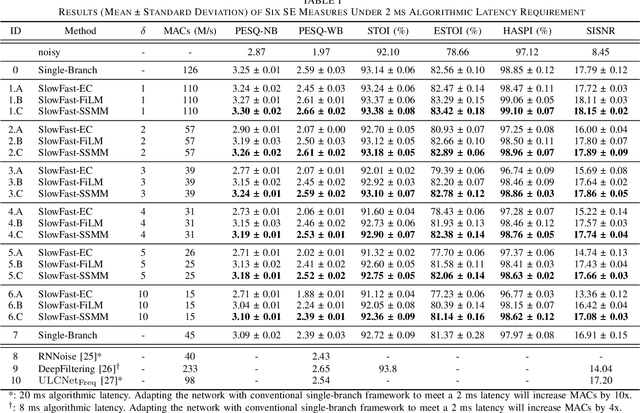

Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 60 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement
Aug 22, 2024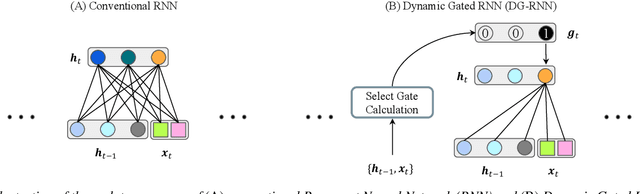
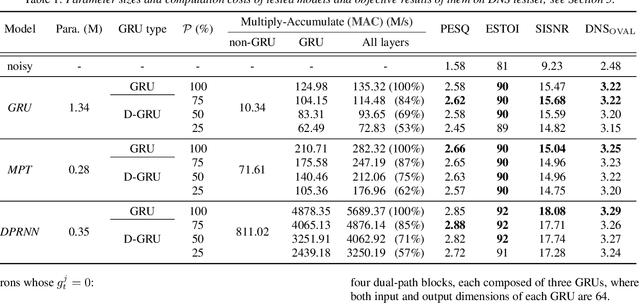
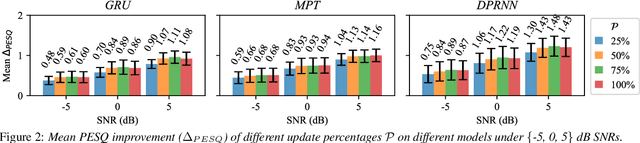
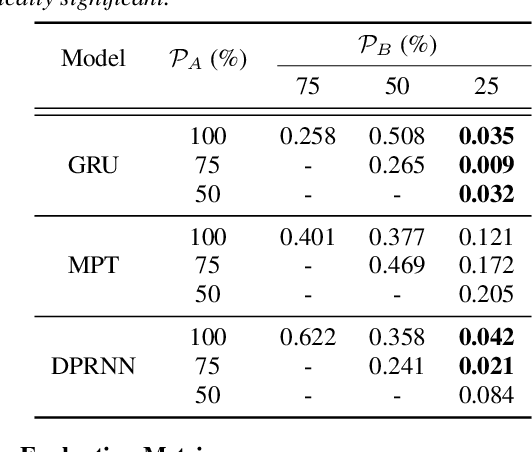
This paper introduces a new Dynamic Gated Recurrent Neural Network (DG-RNN) for compute-efficient speech enhancement models running on resource-constrained hardware platforms. It leverages the slow evolution characteristic of RNN hidden states over steps, and updates only a selected set of neurons at each step by adding a newly proposed select gate to the RNN model. This select gate allows the computation cost of the conventional RNN to be reduced during network inference. As a realization of the DG-RNN, we further propose the Dynamic Gated Recurrent Unit (D-GRU) which does not require additional parameters. Test results obtained from several state-of-the-art compute-efficient RNN-based speech enhancement architectures using the DNS challenge dataset, show that the D-GRU based model variants maintain similar speech intelligibility and quality metrics comparable to the baseline GRU based models even with an average 50% reduction in GRU computes.
Text-to-Events: Synthetic Event Camera Streams from Conditional Text Input
Jun 05, 2024Event cameras are advantageous for tasks that require vision sensors with low-latency and sparse output responses. However, the development of deep network algorithms using event cameras has been slow because of the lack of large labelled event camera datasets for network training. This paper reports a method for creating new labelled event datasets by using a text-to-X model, where X is one or multiple output modalities, in the case of this work, events. Our proposed text-to-events model produces synthetic event frames directly from text prompts. It uses an autoencoder which is trained to produce sparse event frames representing event camera outputs. By combining the pretrained autoencoder with a diffusion model architecture, the new text-to-events model is able to generate smooth synthetic event streams of moving objects. The autoencoder was first trained on an event camera dataset of diverse scenes. In the combined training with the diffusion model, the DVS gesture dataset was used. We demonstrate that the model can generate realistic event sequences of human gestures prompted by different text statements. The classification accuracy of the generated sequences, using a classifier trained on the real dataset, ranges between 42% to 92%, depending on the gesture group. The results demonstrate the capability of this method in synthesizing event datasets.
A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM
May 06, 2024This paper introduces, to the best of the authors' knowledge, the first fine-grained temporal sparsity-aware keyword spotting (KWS) IC leveraging temporal similarities between neighboring feature vectors extracted from input frames and network hidden states, eliminating unnecessary operations and memory accesses. This KWS IC, featuring a bio-inspired delta-gated recurrent neural network ({\Delta}RNN) classifier, achieves an 11-class Google Speech Command Dataset (GSCD) KWS accuracy of 90.5% and energy consumption of 36nJ/decision. At 87% temporal sparsity, computing latency and energy per inference are reduced by 2.4$\times$/3.4$\times$, respectively. The 65nm design occupies 0.78mm$^2$ and features two additional blocks, a compact 0.084mm$^2$ digital infinite-impulse-response (IIR)-based band-pass filter (BPF) audio feature extractor (FEx) and a 24kB 0.6V near-Vth weight SRAM with 6.6$\times$ lower read power compared to the standard SRAM.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024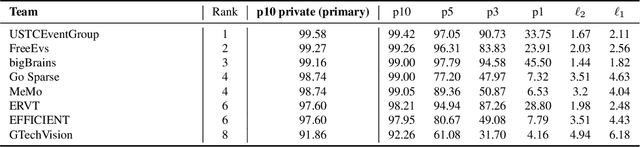
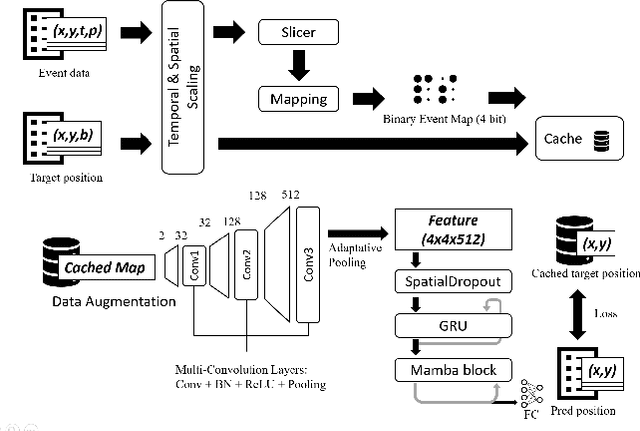
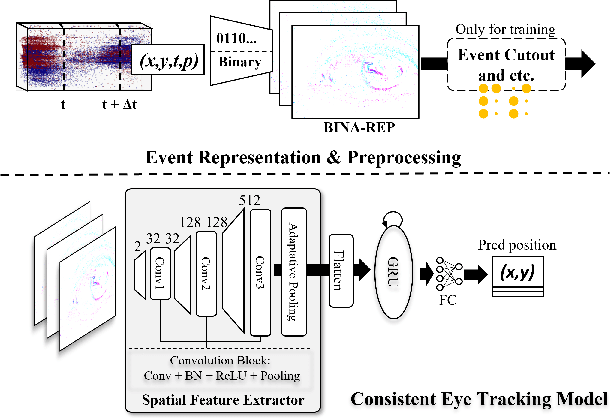

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.
3ET: Efficient Event-based Eye Tracking using a Change-Based ConvLSTM Network
Aug 22, 2023This paper presents a sparse Change-Based Convolutional Long Short-Term Memory (CB-ConvLSTM) model for event-based eye tracking, key for next-generation wearable healthcare technology such as AR/VR headsets. We leverage the benefits of retina-inspired event cameras, namely their low-latency response and sparse output event stream, over traditional frame-based cameras. Our CB-ConvLSTM architecture efficiently extracts spatio-temporal features for pupil tracking from the event stream, outperforming conventional CNN structures. Utilizing a delta-encoded recurrent path enhancing activation sparsity, CB-ConvLSTM reduces arithmetic operations by approximately 4.7$\times$ without losing accuracy when tested on a \texttt{v2e}-generated event dataset of labeled pupils. This increase in efficiency makes it ideal for real-time eye tracking in resource-constrained devices. The project code and dataset are openly available at \url{https://github.com/qinche106/cb-convlstm-eyetracking}.
Biologically-Inspired Continual Learning of Human Motion Sequences
Nov 02, 2022This work proposes a model for continual learning on tasks involving temporal sequences, specifically, human motions. It improves on a recently proposed brain-inspired replay model (BI-R) by building a biologically-inspired conditional temporal variational autoencoder (BI-CTVAE), which instantiates a latent mixture-of-Gaussians for class representation. We investigate a novel continual-learning-to-generate (CL2Gen) scenario where the model generates motion sequences of different classes. The generative accuracy of the model is tested over a set of tasks. The final classification accuracy of BI-CTVAE on a human motion dataset after sequentially learning all action classes is 78%, which is 63% higher than using no-replay, and only 5.4% lower than a state-of-the-art offline trained GRU model.
A 23 $μ$W Keyword Spotting IC with Ring-Oscillator-Based Time-Domain Feature Extraction
Aug 01, 2022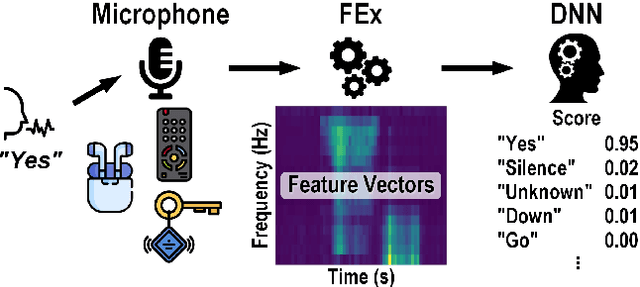
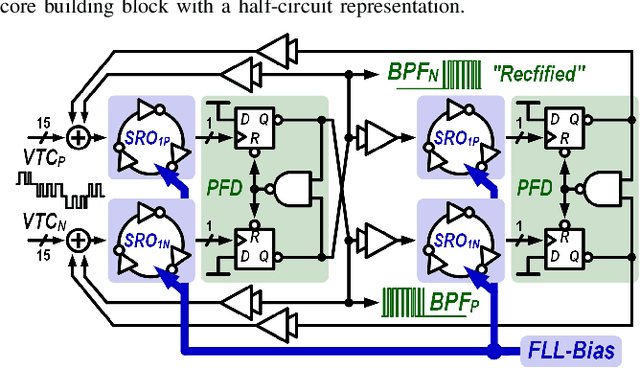
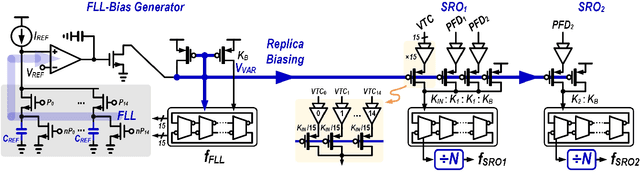
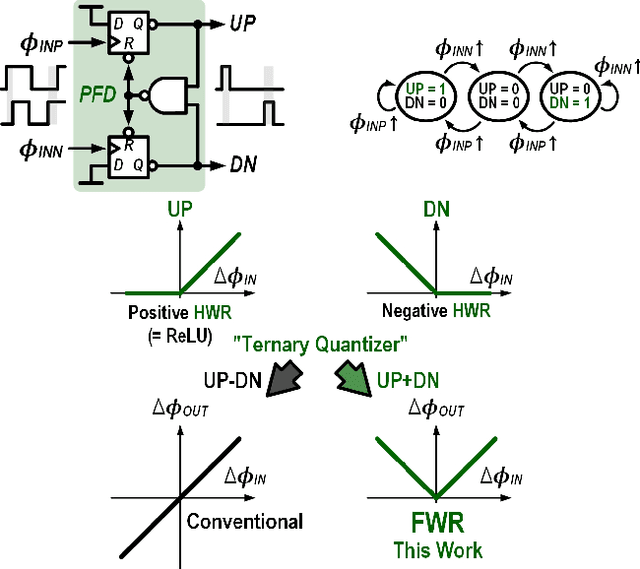
This article presents the first keyword spotting (KWS) IC which uses a ring-oscillator-based time-domain processing technique for its analog feature extractor (FEx). Its extensive usage of time-encoding schemes allows the analog audio signal to be processed in a fully time-domain manner except for the voltage-to-time conversion stage of the analog front-end. Benefiting from fundamental building blocks based on digital logic gates, it offers a better technology scalability compared to conventional voltage-domain designs. Fabricated in a 65 nm CMOS process, the prototyped KWS IC occupies 2.03mm$^{2}$ and dissipates 23 $\mu$W power consumption including analog FEx and digital neural network classifier. The 16-channel time-domain FEx achieves 54.89 dB dynamic range for 16 ms frame shift size while consuming 9.3 $\mu$W. The measurement result verifies that the proposed IC performs a 12-class KWS task on the Google Speech Command Dataset (GSCD) with >86% accuracy and 12.4 ms latency.