 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a physically realistic computationally efficient DVS pixel model
May 12, 2025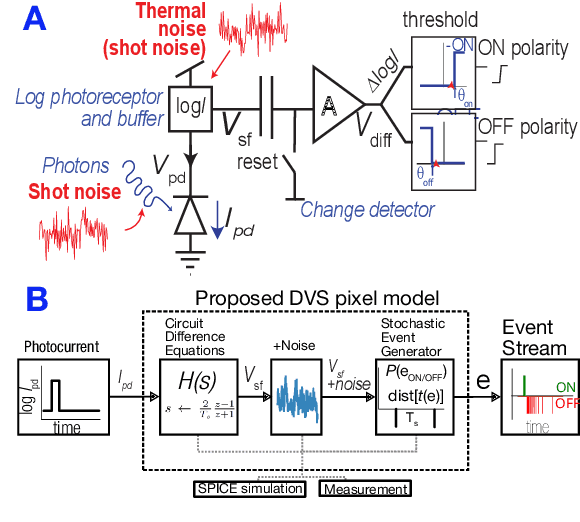



Dynamic Vision Sensor (DVS) event camera models are important tools for predicting camera response, optimizing biases, and generating realistic simulated datasets. Existing DVS models have been useful, but have not demonstrated high realism for challenging HDR scenes combined with adequate computational efficiency for array-level scene simulation. This paper reports progress towards a physically realistic and computationally efficient DVS model based on large-signal differential equations derived from circuit analysis, with parameters fitted from pixel measurements and circuit simulation. These are combined with an efficient stochastic event generation mechanism based on first-passage-time theory, allowing accurate noise generation with timesteps greater than 1000x longer than previous methods
Modulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
Nov 04, 2024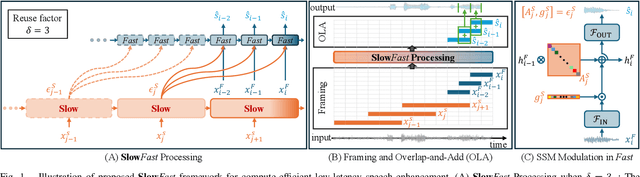
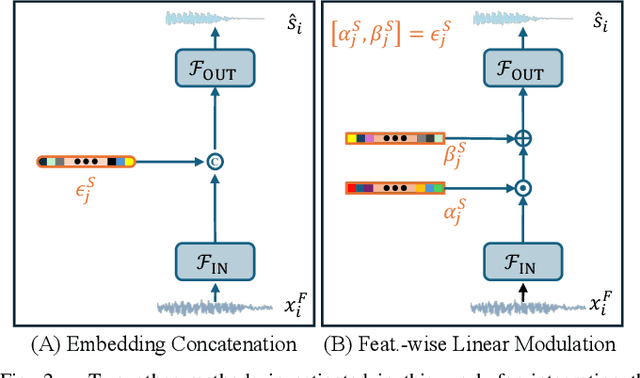
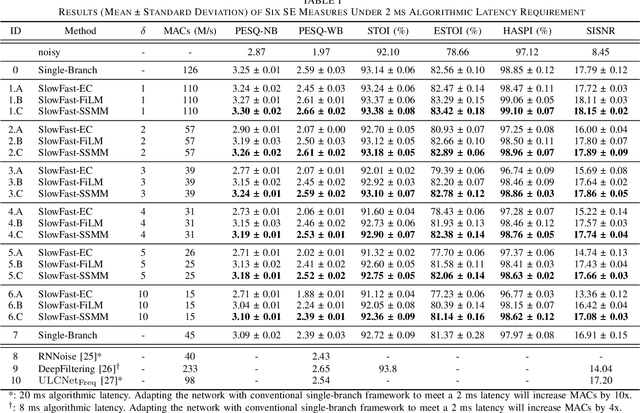

Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 60 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
Steering Prediction via a Multi-Sensor System for Autonomous Racing
Sep 28, 2024



Autonomous racing has rapidly gained research attention. Traditionally, racing cars rely on 2D LiDAR as their primary visual system. In this work, we explore the integration of an event camera with the existing system to provide enhanced temporal information. Our goal is to fuse the 2D LiDAR data with event data in an end-to-end learning framework for steering prediction, which is crucial for autonomous racing. To the best of our knowledge, this is the first study addressing this challenging research topic. We start by creating a multisensor dataset specifically for steering prediction. Using this dataset, we establish a benchmark by evaluating various SOTA fusion methods. Our observations reveal that existing methods often incur substantial computational costs. To address this, we apply low-rank techniques to propose a novel, efficient, and effective fusion design. We introduce a new fusion learning policy to guide the fusion process, enhancing robustness against misalignment. Our fusion architecture provides better steering prediction than LiDAR alone, significantly reducing the RMSE from 7.72 to 1.28. Compared to the second-best fusion method, our work represents only 11% of the learnable parameters while achieving better accuracy. The source code, dataset, and benchmark will be released to promote future research.
SciDVS: A Scientific Event Camera with 1.7% Temporal Contrast Sensitivity at 0.7 lux
Sep 15, 2024



This paper reports a Dynamic Vision Sensor (DVS) event camera that is 6x more sensitive at 14x lower illumination than existing commercial and prototype cameras. Event cameras output a sparse stream of brightness change events. Their high dynamic range (HDR), quick response, and high temporal resolution provide key advantages for scientific applications that involve low lighting conditions and sparse visual events. However, current DVS are hindered by low sensitivity, resulting from shot noise and pixel-to-pixel mismatch. Commercial DVS have a minimum brightness change threshold of >10%. Sensitive prototypes achieved as low as 1%, but required kilo-lux illumination. Our SciDVS prototype fabricated in a 180nm CMOS image sensor process achieves 1.7% sensitivity at chip illumination of 0.7 lx and 18 Hz bandwidth. Novel features of SciDVS are (1) an auto-centering in-pixel preamplifier providing intrascene HDR and increased sensitivity, (2) improved control of bandwidth to limit shot noise, and (3) optional pixel binning, allowing the user to trade spatial resolution for sensitivity.
Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement
Aug 22, 2024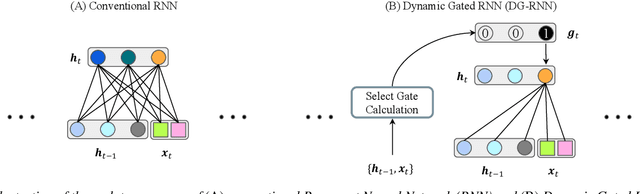
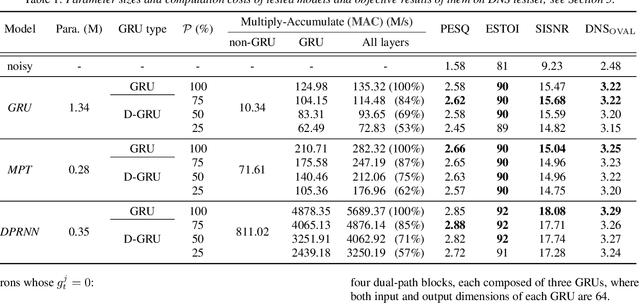
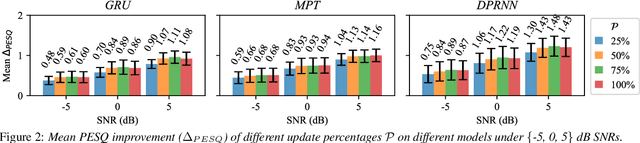
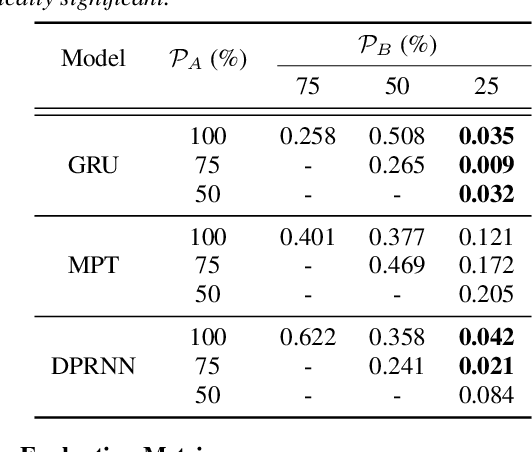
This paper introduces a new Dynamic Gated Recurrent Neural Network (DG-RNN) for compute-efficient speech enhancement models running on resource-constrained hardware platforms. It leverages the slow evolution characteristic of RNN hidden states over steps, and updates only a selected set of neurons at each step by adding a newly proposed select gate to the RNN model. This select gate allows the computation cost of the conventional RNN to be reduced during network inference. As a realization of the DG-RNN, we further propose the Dynamic Gated Recurrent Unit (D-GRU) which does not require additional parameters. Test results obtained from several state-of-the-art compute-efficient RNN-based speech enhancement architectures using the DNS challenge dataset, show that the D-GRU based model variants maintain similar speech intelligibility and quality metrics comparable to the baseline GRU based models even with an average 50% reduction in GRU computes.
Hardware Neural Control of CartPole and F1TENTH Race Car
Jul 11, 2024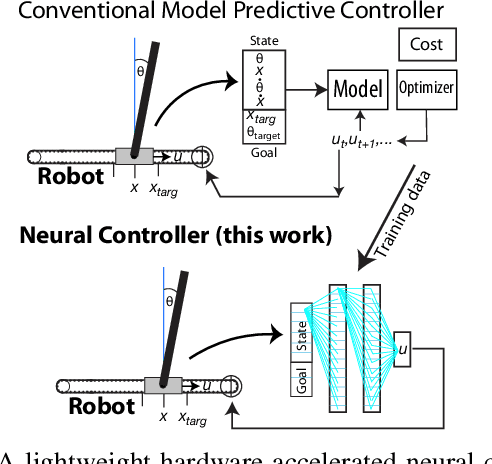

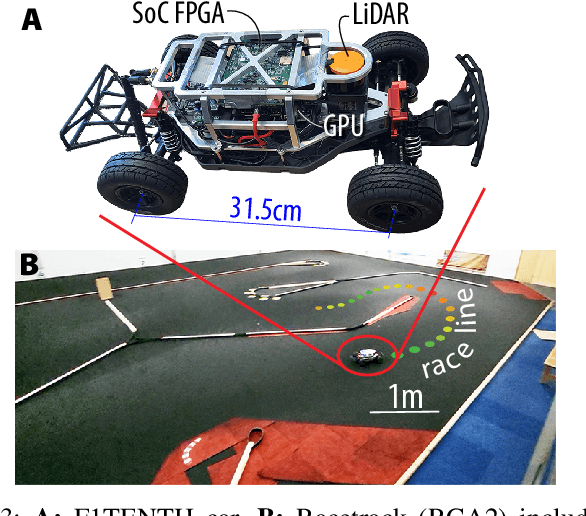
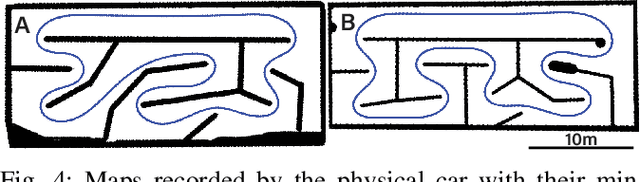
Nonlinear model predictive control (NMPC) has proven to be an effective control method, but it is expensive to compute. This work demonstrates the use of hardware FPGA neural network controllers trained to imitate NMPC with supervised learning. We use these Neural Controllers (NCs) implemented on inexpensive embedded FPGA hardware for high frequency control on physical cartpole and F1TENTH race car. Our results show that the NCs match the control performance of the NMPCs in simulation and outperform it in reality, due to the faster control rate that is afforded by the quick FPGA NC inference. We demonstrate kHz control rates for a physical cartpole and offloading control to the FPGA hardware on the F1TENTH car. Code and hardware implementation for this paper are available at https:// github.com/SensorsINI/Neural-Control-Tools.
A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM
May 06, 2024This paper introduces, to the best of the authors' knowledge, the first fine-grained temporal sparsity-aware keyword spotting (KWS) IC leveraging temporal similarities between neighboring feature vectors extracted from input frames and network hidden states, eliminating unnecessary operations and memory accesses. This KWS IC, featuring a bio-inspired delta-gated recurrent neural network ({\Delta}RNN) classifier, achieves an 11-class Google Speech Command Dataset (GSCD) KWS accuracy of 90.5% and energy consumption of 36nJ/decision. At 87% temporal sparsity, computing latency and energy per inference are reduced by 2.4$\times$/3.4$\times$, respectively. The 65nm design occupies 0.78mm$^2$ and features two additional blocks, a compact 0.084mm$^2$ digital infinite-impulse-response (IIR)-based band-pass filter (BPF) audio feature extractor (FEx) and a 24kB 0.6V near-Vth weight SRAM with 6.6$\times$ lower read power compared to the standard SRAM.
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.
Exploiting Alternating DVS Shot Noise Event Pair Statistics to Reduce Background Activity
Apr 12, 2023Dynamic Vision Sensors (DVS) record "events" corresponding to pixel-level brightness changes, resulting in data-efficient representation of a dynamic visual scene. As DVS expand into increasingly diverse applications, non-ideal behaviors in their output under extreme sensing conditions are important to consider. Under low illumination (below ~10 lux) their output begins to be dominated by shot noise events (SNEs) which increase the data output and obscure true signal. SNE rates can be controlled to some degree by tuning circuit parameters to reduce sensitivity or temporal response bandwidth at the cost of signal loss. Alternatively, an improved understanding of SNE statistics can be leveraged to develop novel techniques for minimizing uninformative sensor output. We first explain a fundamental observation about sequential pairing of opposite polarity SNEs based on pixel circuit logic and validate our theory using DVS recordings and simulations. Finally, we derive a practical result from this new understanding and demonstrate two novel biasing techniques to reduce SNEs by 50% and 80% respectively while still retaining sensitivity and/or temporal resolution.
A 23 $μ$W Keyword Spotting IC with Ring-Oscillator-Based Time-Domain Feature Extraction
Aug 01, 2022
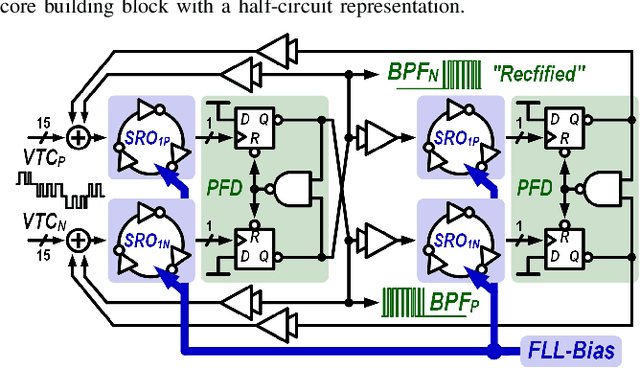
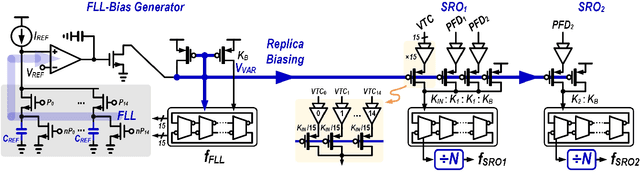
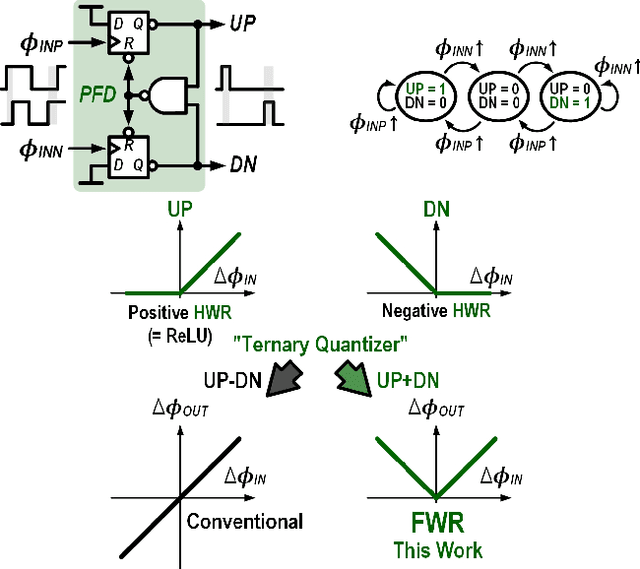
This article presents the first keyword spotting (KWS) IC which uses a ring-oscillator-based time-domain processing technique for its analog feature extractor (FEx). Its extensive usage of time-encoding schemes allows the analog audio signal to be processed in a fully time-domain manner except for the voltage-to-time conversion stage of the analog front-end. Benefiting from fundamental building blocks based on digital logic gates, it offers a better technology scalability compared to conventional voltage-domain designs. Fabricated in a 65 nm CMOS process, the prototyped KWS IC occupies 2.03mm$^{2}$ and dissipates 23 $\mu$W power consumption including analog FEx and digital neural network classifier. The 16-channel time-domain FEx achieves 54.89 dB dynamic range for 16 ms frame shift size while consuming 9.3 $\mu$W. The measurement result verifies that the proposed IC performs a 12-class KWS task on the Google Speech Command Dataset (GSCD) with >86% accuracy and 12.4 ms latency.