 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
Nov 04, 2024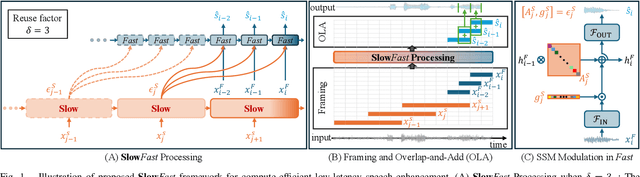
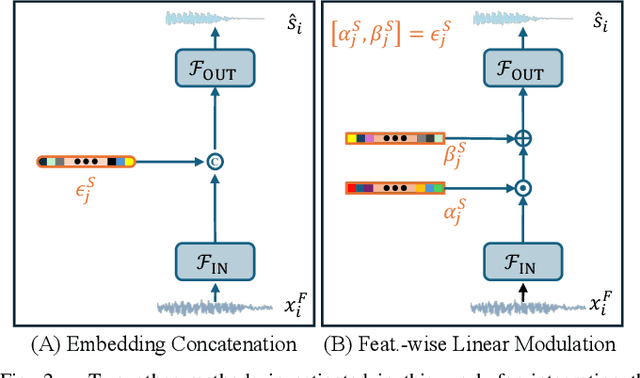
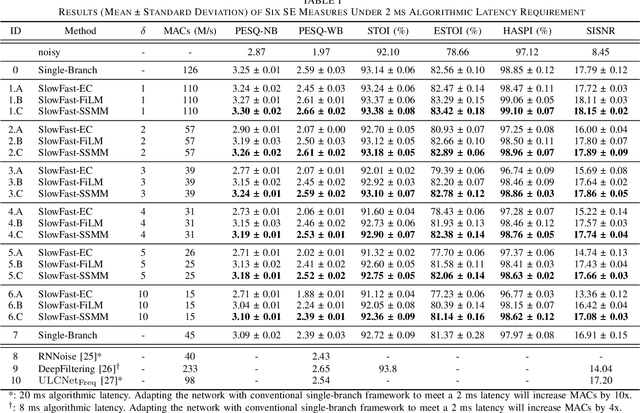

Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 60 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement
Aug 22, 2024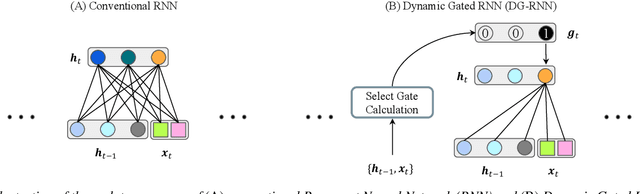
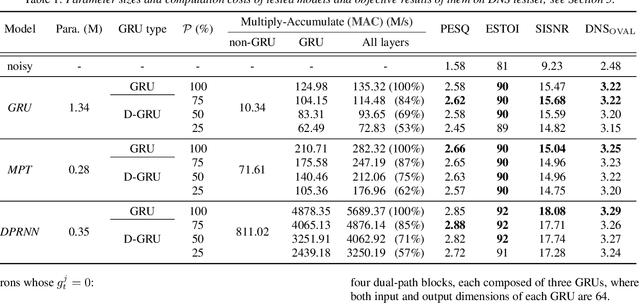
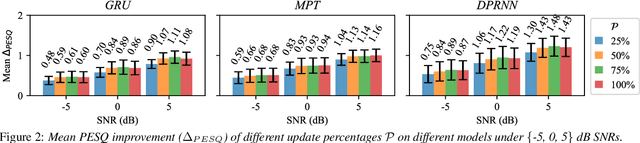
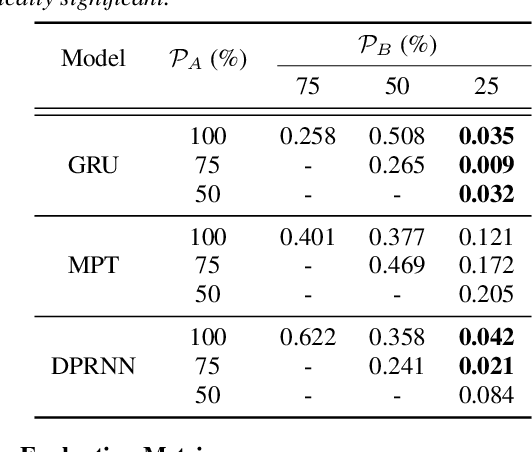
This paper introduces a new Dynamic Gated Recurrent Neural Network (DG-RNN) for compute-efficient speech enhancement models running on resource-constrained hardware platforms. It leverages the slow evolution characteristic of RNN hidden states over steps, and updates only a selected set of neurons at each step by adding a newly proposed select gate to the RNN model. This select gate allows the computation cost of the conventional RNN to be reduced during network inference. As a realization of the DG-RNN, we further propose the Dynamic Gated Recurrent Unit (D-GRU) which does not require additional parameters. Test results obtained from several state-of-the-art compute-efficient RNN-based speech enhancement architectures using the DNS challenge dataset, show that the D-GRU based model variants maintain similar speech intelligibility and quality metrics comparable to the baseline GRU based models even with an average 50% reduction in GRU computes.
Exploiting Symmetric Temporally Sparse BPTT for Efficient RNN Training
Dec 14, 2023Recurrent Neural Networks (RNNs) are useful in temporal sequence tasks. However, training RNNs involves dense matrix multiplications which require hardware that can support a large number of arithmetic operations and memory accesses. Implementing online training of RNNs on the edge calls for optimized algorithms for an efficient deployment on hardware. Inspired by the spiking neuron model, the Delta RNN exploits temporal sparsity during inference by skipping over the update of hidden states from those inactivated neurons whose change of activation across two timesteps is below a defined threshold. This work describes a training algorithm for Delta RNNs that exploits temporal sparsity in the backward propagation phase to reduce computational requirements for training on the edge. Due to the symmetric computation graphs of forward and backward propagation during training, the gradient computation of inactivated neurons can be skipped. Results show a reduction of $\sim$80% in matrix operations for training a 56k parameter Delta LSTM on the Fluent Speech Commands dataset with negligible accuracy loss. Logic simulations of a hardware accelerator designed for the training algorithm show 2-10X speedup in matrix computations for an activation sparsity range of 50%-90%. Additionally, we show that the proposed Delta RNN training will be useful for online incremental learning on edge devices with limited computing resources.