 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Magnifier: Spatial upsampling for multichannel speech enhancement
May 06, 2026While the spatial directivity of multichannel speech enhancement algorithms improves with the number of microphones, fitting large capture arrays into real-world edge devices is typically limited by physical constraints. To overcome this limitation, we propose Spatial-Magnifier, a neural network designed to generate virtual microphone (VM) signals from a limited set of real microphone (RM) measurements. Moreover, we introduce the Spatial Audio Representation Learning (SARL) framework, which leverages estimated VM signals and features to condition a downstream speech enhancement system. Experimental results demonstrate that the proposed framework outperforms existing spatial upsampling baselines across various speech extraction systems, including end-to-end multichannel speech enhancement and neural beamforming. The proposed method nearly recovers the oracle performance achieved when all microphones are available.
Unified Diffusion Refinement for Multi-Channel Speech Enhancement and Separation
Mar 25, 2026We propose Uni-ArrayDPS, a novel diffusion-based refinement framework for unified multi-channel speech enhancement and separation. Existing methods for multi-channel speech enhancement/separation are mostly discriminative and are highly effective at producing high-SNR outputs. However, they can still generate unnatural speech with non-linear distortions caused by the neural network and regression-based objectives. To address this issue, we propose Uni-ArrayDPS, which refines the outputs of any strong discriminative model using a speech diffusion prior. Uni-ArrayDPS is generative, array-agnostic, and training-free, and supports both enhancement and separation. Given a discriminative model's enhanced/separated speech, we use it, together with the noisy mixtures, to estimate the noise spatial covariance matrix (SCM). We then use this SCM to compute the likelihood required for diffusion posterior sampling of the clean speech source(s). Uni-ArrayDPS requires only a pre-trained clean-speech diffusion model as a prior and does not require additional training or fine-tuning, allowing it to generalize directly across tasks (enhancement/separation), microphone array geometries, and discriminative model backbones. Extensive experiments show that Uni-ArrayDPS consistently improves a wide range of discriminative models for both enhancement and separation tasks. We also report strong results on a real-world dataset. Audio demos are provided at \href{https://xzwy.github.io/Uni-ArrayDPS/}{https://xzwy.github.io/Uni-ArrayDPS/}.
ArrayDPS-Refine: Generative Refinement of Discriminative Multi-Channel Speech Enhancement
Mar 25, 2026Multi-channel speech enhancement aims to recover clean speech from noisy multi-channel recordings. Most deep learning methods employ discriminative training, which can lead to non-linear distortions from regression-based objectives, especially under challenging environmental noise conditions. Inspired by ArrayDPS for unsupervised multi-channel source separation, we introduce ArrayDPS-Refine, a method designed to enhance the outputs of discriminative models using a clean speech diffusion prior. ArrayDPS-Refine is training-free, generative, and array-agnostic. It first estimates the noise spatial covariance matrix (SCM) from the enhanced speech produced by a discriminative model, then uses this estimated noise SCM for diffusion posterior sampling. This approach allows direct refinement of any discriminative model's output without retraining. Our results show that ArrayDPS-Refine consistently improves the performance of various discriminative models, including state-of-the-art waveform and STFT domain models. Audio demos are provided at https://xzwy.github.io/ArrayDPSRefineDemo/.
Improving Resource-Efficient Speech Enhancement via Neural Differentiable DSP Vocoder Refinement
Aug 20, 2025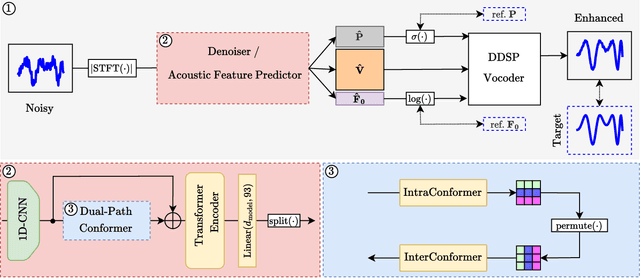
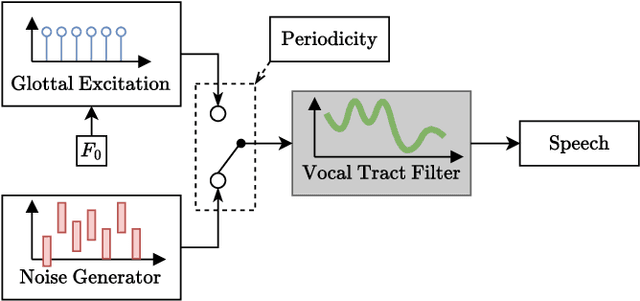
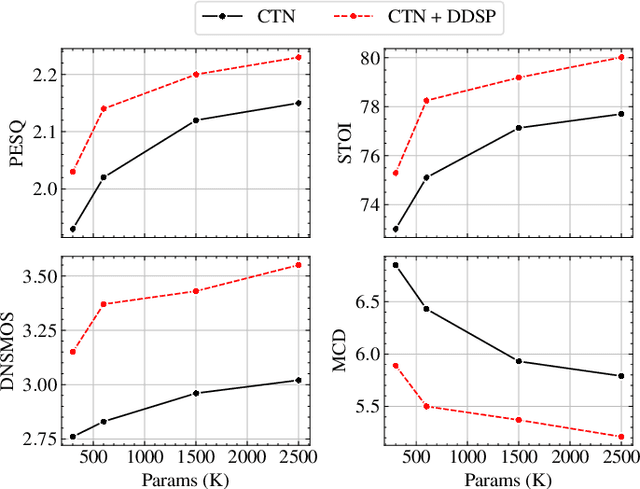
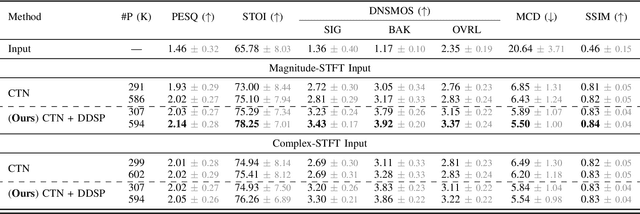
Deploying speech enhancement (SE) systems in wearable devices, such as smart glasses, is challenging due to the limited computational resources on the device. Although deep learning methods have achieved high-quality results, their computational cost limits their feasibility on embedded platforms. This work presents an efficient end-to-end SE framework that leverages a Differentiable Digital Signal Processing (DDSP) vocoder for high-quality speech synthesis. First, a compact neural network predicts enhanced acoustic features from noisy speech: spectral envelope, fundamental frequency (F0), and periodicity. These features are fed into the DDSP vocoder to synthesize the enhanced waveform. The system is trained end-to-end with STFT and adversarial losses, enabling direct optimization at the feature and waveform levels. Experimental results show that our method improves intelligibility and quality by 4% (STOI) and 19% (DNSMOS) over strong baselines without significantly increasing computation, making it well-suited for real-time applications.
A Novel Deep Learning Framework for Efficient Multichannel Acoustic Feedback Control
May 21, 2025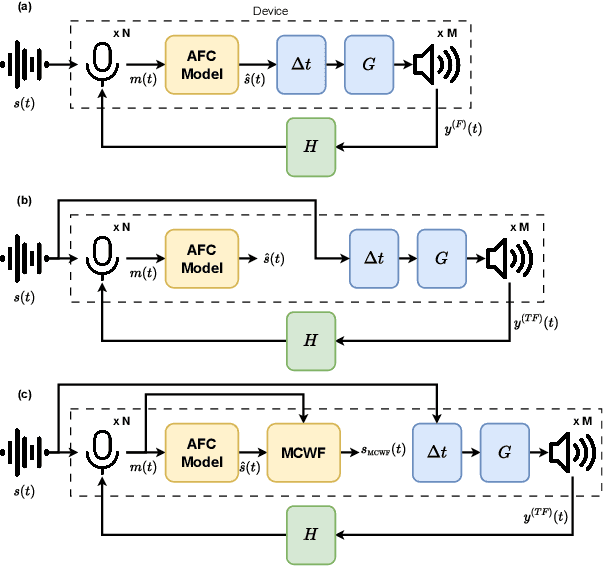
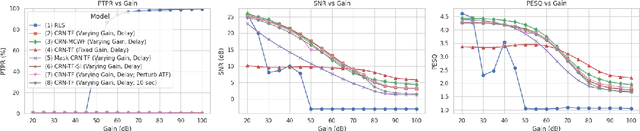
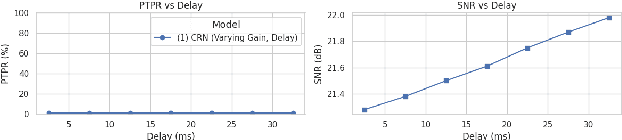
This study presents a deep-learning framework for controlling multichannel acoustic feedback in audio devices. Traditional digital signal processing methods struggle with convergence when dealing with highly correlated noise such as feedback. We introduce a Convolutional Recurrent Network that efficiently combines spatial and temporal processing, significantly enhancing speech enhancement capabilities with lower computational demands. Our approach utilizes three training methods: In-a-Loop Training, Teacher Forcing, and a Hybrid strategy with a Multichannel Wiener Filter, optimizing performance in complex acoustic environments. This scalable framework offers a robust solution for real-world applications, making significant advances in Acoustic Feedback Control technology.
Efficient Audiovisual Speech Processing via MUTUD: Multimodal Training and Unimodal Deployment
Jan 30, 2025



Building reliable speech systems often requires combining multiple modalities, like audio and visual cues. While such multimodal solutions frequently lead to improvements in performance and may even be critical in certain cases, they come with several constraints such as increased sensory requirements, computational cost, and modality synchronization, to mention a few. These challenges constrain the direct uses of these multimodal solutions in real-world applications. In this work, we develop approaches where the learning happens with all available modalities but the deployment or inference is done with just one or reduced modalities. To do so, we propose a Multimodal Training and Unimodal Deployment (MUTUD) framework which includes a Temporally Aligned Modality feature Estimation (TAME) module that can estimate information from missing modality using modalities present during inference. This innovative approach facilitates the integration of information across different modalities, enhancing the overall inference process by leveraging the strengths of each modality to compensate for the absence of certain modalities during inference. We apply MUTUD to various audiovisual speech tasks and show that it can reduce the performance gap between the multimodal and corresponding unimodal models to a considerable extent. MUTUD can achieve this while reducing the model size and compute compared to multimodal models, in some cases by almost 80%.
Modulating State Space Model with SlowFast Framework for Compute-Efficient Ultra Low-Latency Speech Enhancement
Nov 04, 2024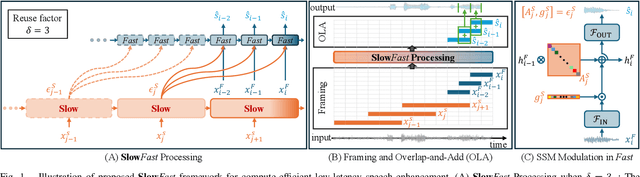
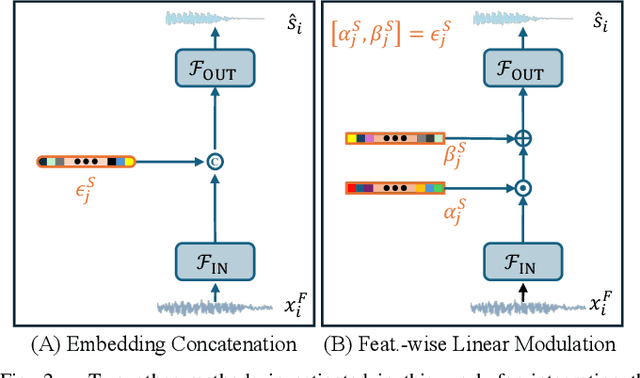
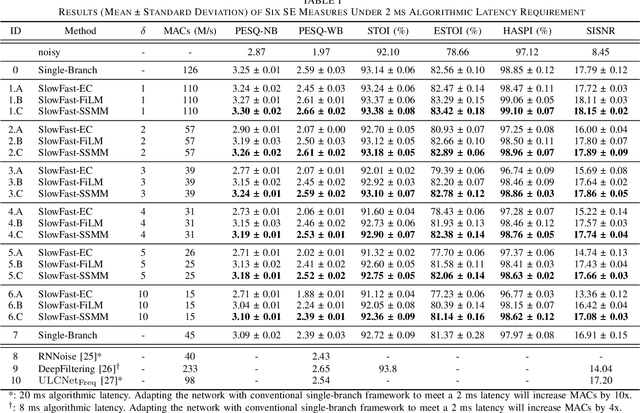

Deep learning-based speech enhancement (SE) methods often face significant computational challenges when needing to meet low-latency requirements because of the increased number of frames to be processed. This paper introduces the SlowFast framework which aims to reduce computation costs specifically when low-latency enhancement is needed. The framework consists of a slow branch that analyzes the acoustic environment at a low frame rate, and a fast branch that performs SE in the time domain at the needed higher frame rate to match the required latency. Specifically, the fast branch employs a state space model where its state transition process is dynamically modulated by the slow branch. Experiments on a SE task with a 2 ms algorithmic latency requirement using the Voice Bank + Demand dataset show that our approach reduces computation cost by 70% compared to a baseline single-branch network with equivalent parameters, without compromising enhancement performance. Furthermore, by leveraging the SlowFast framework, we implemented a network that achieves an algorithmic latency of just 60 {\mu}s (one sample point at 16 kHz sample rate) with a computation cost of 100 M MACs/s, while scoring a PESQ-NB of 3.12 and SISNR of 16.62.
Dynamic Gated Recurrent Neural Network for Compute-efficient Speech Enhancement
Aug 22, 2024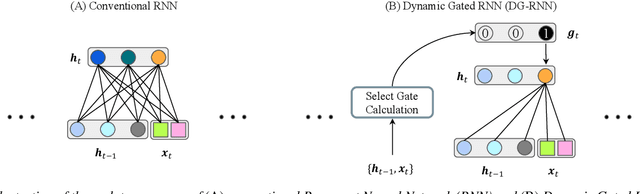
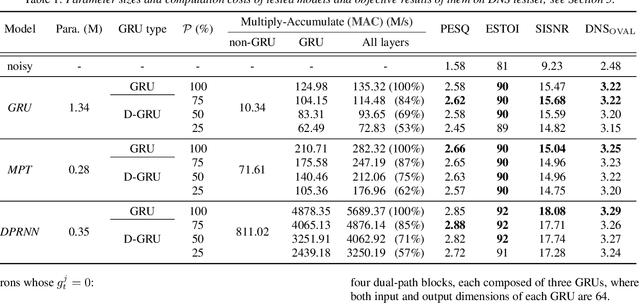
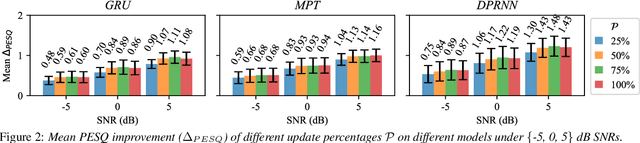
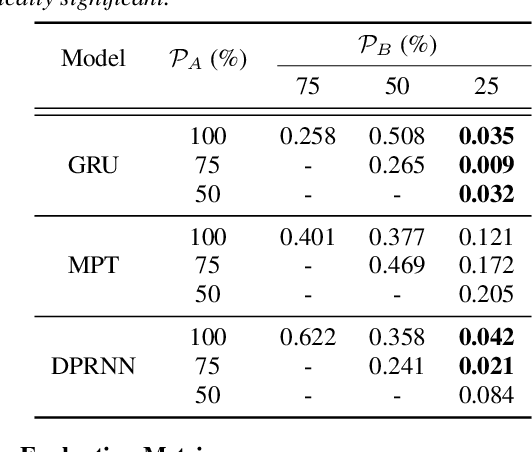
This paper introduces a new Dynamic Gated Recurrent Neural Network (DG-RNN) for compute-efficient speech enhancement models running on resource-constrained hardware platforms. It leverages the slow evolution characteristic of RNN hidden states over steps, and updates only a selected set of neurons at each step by adding a newly proposed select gate to the RNN model. This select gate allows the computation cost of the conventional RNN to be reduced during network inference. As a realization of the DG-RNN, we further propose the Dynamic Gated Recurrent Unit (D-GRU) which does not require additional parameters. Test results obtained from several state-of-the-art compute-efficient RNN-based speech enhancement architectures using the DNS challenge dataset, show that the D-GRU based model variants maintain similar speech intelligibility and quality metrics comparable to the baseline GRU based models even with an average 50% reduction in GRU computes.
FoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Aug 12, 2024


This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
All Neural Low-latency Directional Speech Extraction
Jul 05, 2024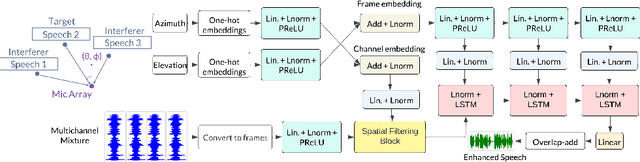
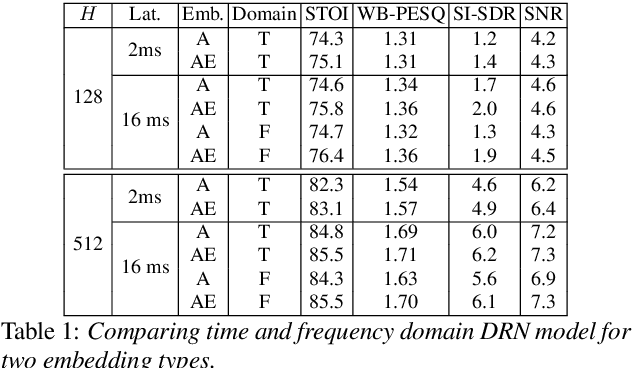
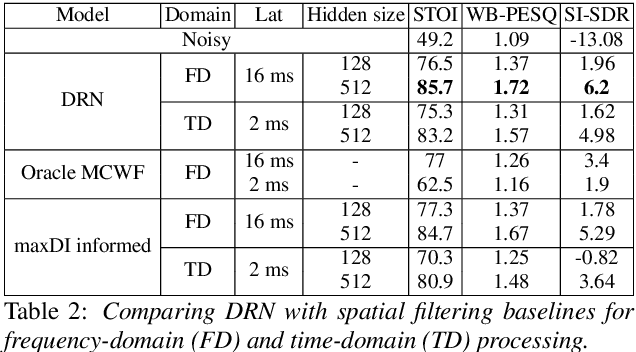
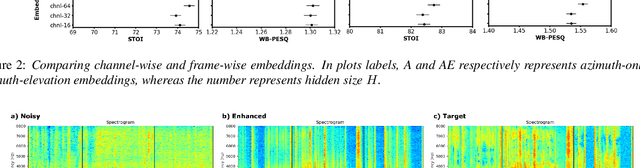
We introduce a novel all neural model for low-latency directional speech extraction. The model uses direction of arrival (DOA) embeddings from a predefined spatial grid, which are transformed and fused into a recurrent neural network based speech extraction model. This process enables the model to effectively extract speech from a specified DOA. Unlike previous methods that relied on hand-crafted directional features, the proposed model trains DOA embeddings from scratch using speech enhancement loss, making it suitable for low-latency scenarios. Additionally, it operates at a high frame rate, taking in DOA with each input frame, which brings in the capability of quickly adapting to changing scene in highly dynamic real-world scenarios. We provide extensive evaluation to demonstrate the model's efficacy in directional speech extraction, robustness to DOA mismatch, and its capability to quickly adapt to abrupt changes in DOA.