 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interaction Layer: An Exploration for Co-Designing User-LLM Interactions in Parental Wellbeing Support Systems
Nov 02, 2024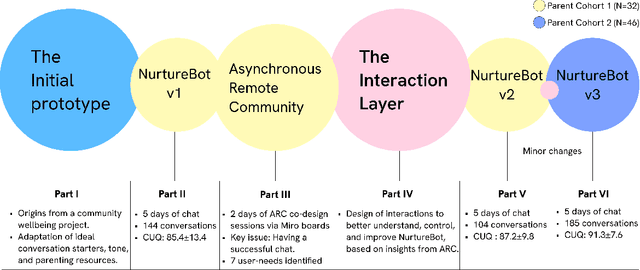



Parenting brings emotional and physical challenges, from balancing work, childcare, and finances to coping with exhaustion and limited personal time. Yet, one in three parents never seek support. AI systems potentially offer stigma-free, accessible, and affordable solutions. Yet, user adoption often fails due to issues with explainability and reliability. To see if these issues could be solved using a co-design approach, we developed and tested NurtureBot, a wellbeing support assistant for new parents. 32 parents co-designed the system through Asynchronous Remote Communities method, identifying the key challenge as achieving a "successful chat". Aspart of co-design, parents role-played as NurturBot, rewriting its dialogues to improve user understanding, control, and outcomes. The refined prototype evaluated by 32 initial and 46 new parents, showed improved user experience and usability, with final CUQ score of 91.3/100, demonstrating successful interaction patterns. Our process revealed useful interaction design lessons for effective AI parenting support.
Re-ENACT: Reinforcement Learning for Emotional Speech Generation using Actor-Critic Strategy
Aug 04, 2024



In this paper, we propose the first method to modify the prosodic features of a given speech signal using actor-critic reinforcement learning strategy. Our approach uses a Bayesian framework to identify contiguous segments of importance that links segments of the given utterances to perception of emotions in humans. We train a neural network to produce the variational posterior of a collection of Bernoulli random variables; our model applies a Markov prior on it to ensure continuity. A sample from this distribution is used for downstream emotion prediction. Further, we train the neural network to predict a soft assignment over emotion categories as the target variable. In the next step, we modify the prosodic features (pitch, intensity, and rhythm) of the masked segment to increase the score of target emotion. We employ an actor-critic reinforcement learning to train the prosody modifier by discretizing the space of modifications. Further, it provides a simple solution to the problem of gradient computation through WSOLA operation for rhythm manipulation. Our experiments demonstrate that this framework changes the perceived emotion of a given speech utterance to the target. Further, we show that our unified technique is on par with state-of-the-art emotion conversion models from supervised and unsupervised domains that require pairwise training.
A Closer Look at Wav2Vec2 Embeddings for On-Device Single-Channel Speech Enhancement
Mar 03, 2024



Self-supervised learned models have been found to be very effective for certain speech tasks such as automatic speech recognition, speaker identification, keyword spotting and others. While the features are undeniably useful in speech recognition and associated tasks, their utility in speech enhancement systems is yet to be firmly established, and perhaps not properly understood. In this paper, we investigate the uses of SSL representations for single-channel speech enhancement in challenging conditions and find that they add very little value for the enhancement task. Our constraints are designed around on-device real-time speech enhancement -- model is causal, the compute footprint is small. Additionally, we focus on low SNR conditions where such models struggle to provide good enhancement. In order to systematically examine how SSL representations impact performance of such enhancement models, we propose a variety of techniques to utilize these embeddings which include different forms of knowledge-distillation and pre-training.
A Diffeomorphic Flow-based Variational Framework for Multi-speaker Emotion Conversion
Nov 09, 2022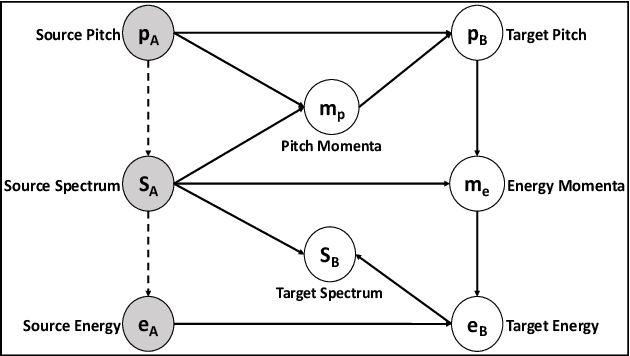
This paper introduces a new framework for non-parallel emotion conversion in speech. Our framework is based on two key contributions. First, we propose a stochastic version of the popular CycleGAN model. Our modified loss function introduces a Kullback Leibler (KL) divergence term that aligns the source and target data distributions learned by the generators, thus overcoming the limitations of sample wise generation. By using a variational approximation to this stochastic loss function, we show that our KL divergence term can be implemented via a paired density discriminator. We term this new architecture a variational CycleGAN (VCGAN). Second, we model the prosodic features of target emotion as a smooth and learnable deformation of the source prosodic features. This approach provides implicit regularization that offers key advantages in terms of better range alignment to unseen and out of distribution speakers. We conduct rigorous experiments and comparative studies to demonstrate that our proposed framework is fairly robust with high performance against several state-of-the-art baselines.
A Comparative Study of Data Augmentation Techniques for Deep Learning Based Emotion Recognition
Nov 09, 2022



Automated emotion recognition in speech is a long-standing problem. While early work on emotion recognition relied on hand-crafted features and simple classifiers, the field has now embraced end-to-end feature learning and classification using deep neural networks. In parallel to these models, researchers have proposed several data augmentation techniques to increase the size and variability of existing labeled datasets. Despite many seminal contributions in the field, we still have a poor understanding of the interplay between the network architecture and the choice of data augmentation. Moreover, only a handful of studies demonstrate the generalizability of a particular model across multiple datasets, which is a prerequisite for robust real-world performance. In this paper, we conduct a comprehensive evaluation of popular deep learning approaches for emotion recognition. To eliminate bias, we fix the model architectures and optimization hyperparameters using the VESUS dataset and then use repeated 5-fold cross validation to evaluate the performance on the IEMOCAP and CREMA-D datasets. Our results demonstrate that long-range dependencies in the speech signal are critical for emotion recognition and that speed/rate augmentation offers the most robust performance gain across models.
Knowledge Graph -- Deep Learning: A Case Study in Question Answering in Aviation Safety Domain
May 31, 2022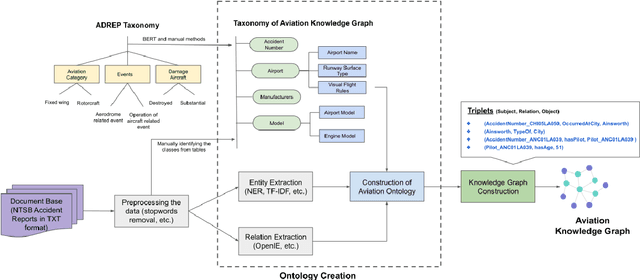
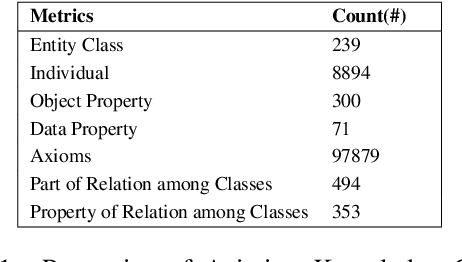
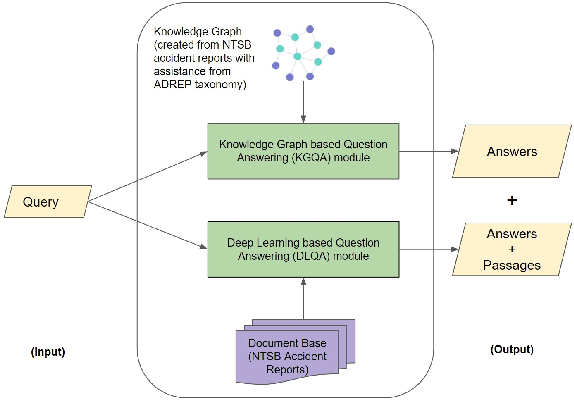

In the commercial aviation domain, there are a large number of documents, like, accident reports (NTSB, ASRS) and regulatory directives (ADs). There is a need for a system to access these diverse repositories efficiently in order to service needs in the aviation industry, like maintenance, compliance, and safety. In this paper, we propose a Knowledge Graph (KG) guided Deep Learning (DL) based Question Answering (QA) system for aviation safety. We construct a Knowledge Graph from Aircraft Accident reports and contribute this resource to the community of researchers. The efficacy of this resource is tested and proved by the aforesaid QA system. Natural Language Queries constructed from the documents mentioned above are converted into SPARQL (the interface language of the RDF graph database) queries and answered. On the DL side, we have two different QA models: (i) BERT QA which is a pipeline of Passage Retrieval (Sentence-BERT based) and Question Answering (BERT based), and (ii) the recently released GPT-3. We evaluate our system on a set of queries created from the accident reports. Our combined QA system achieves 9.3% increase in accuracy over GPT-3 and 40.3% increase over BERT QA. Thus, we infer that KG-DL performs better than either singly.
A Deep-Bayesian Framework for Adaptive Speech Duration Modification
Jul 11, 2021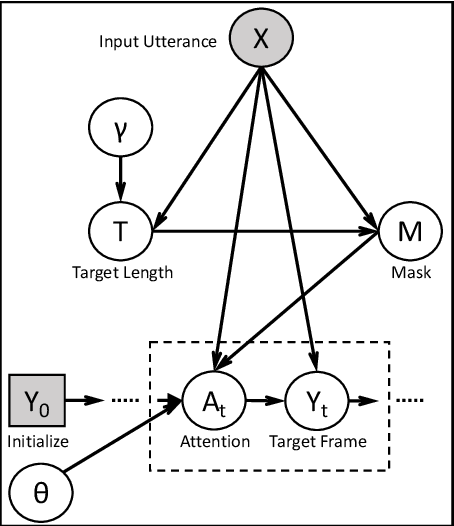

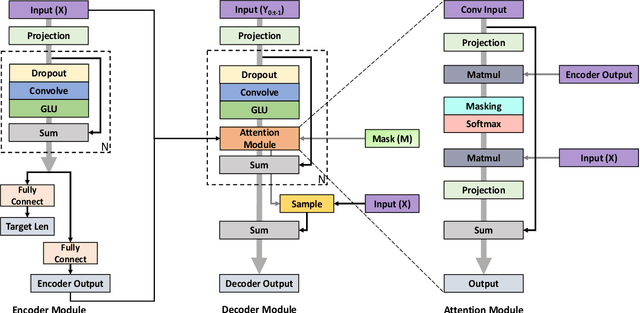
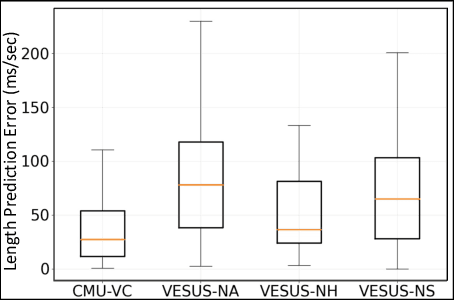
We propose the first method to adaptively modify the duration of a given speech signal. Our approach uses a Bayesian framework to define a latent attention map that links frames of the input and target utterances. We train a masked convolutional encoder-decoder network to produce this attention map via a stochastic version of the mean absolute error loss function; our model also predicts the length of the target speech signal using the encoder embeddings. The predicted length determines the number of steps for the decoder operation. During inference, we generate the attention map as a proxy for the similarity matrix between the given input speech and an unknown target speech signal. Using this similarity matrix, we compute a warping path of alignment between the two signals. Our experiments demonstrate that this adaptive framework produces similar results to dynamic time warping, which relies on a known target signal, on both voice conversion and emotion conversion tasks. We also show that our technique results in a high quality of generated speech that is on par with state-of-the-art vocoders.
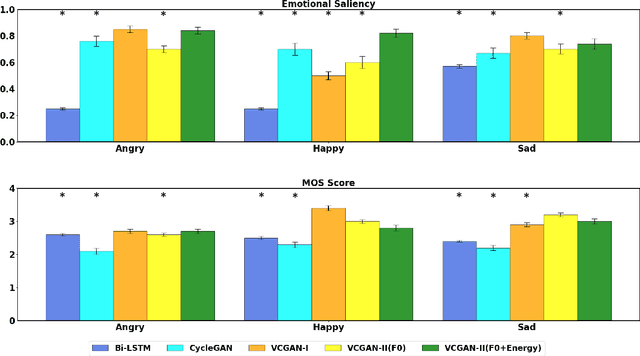
Non-parallel Emotion Conversion using a Deep-Generative Hybrid Network and an Adversarial Pair Discriminator
Aug 10, 2020


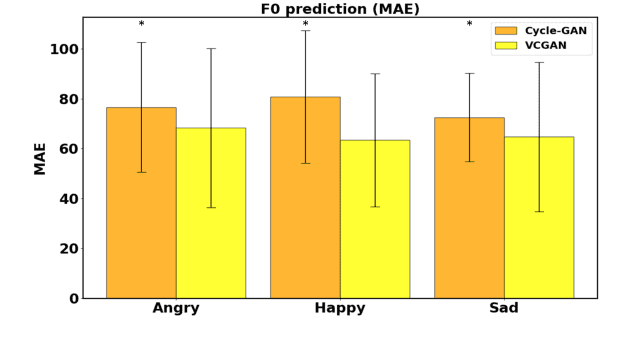
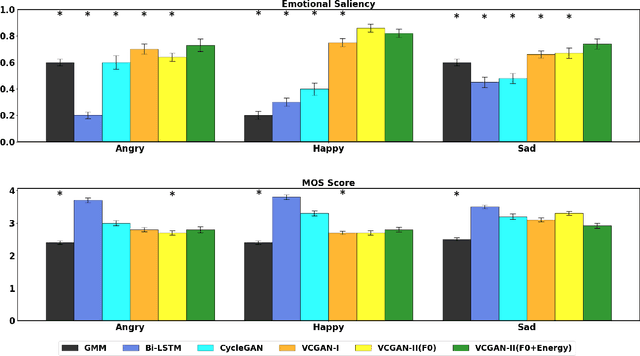
We introduce a novel method for emotion conversion in speech that does not require parallel training data. Our approach loosely relies on a cycle-GAN schema to minimize the reconstruction error from converting back and forth between emotion pairs. However, unlike the conventional cycle-GAN, our discriminator classifies whether a pair of input real and generated samples corresponds to the desired emotion conversion (e.g., A to B) or to its inverse (B to A). We will show that this setup, which we refer to as a variational cycle-GAN (VC-GAN), is equivalent to minimizing the empirical KL divergence between the source features and their cyclic counterpart. In addition, our generator combines a trainable deep network with a fixed generative block to implement a smooth and invertible transformation on the input features, in our case, the fundamental frequency (F0) contour. This hybrid architecture regularizes our adversarial training procedure. We use crowd sourcing to evaluate both the emotional saliency and the quality of synthesized speech. Finally, we show that our model generalizes to new speakers by modifying speech produced by Wavenet.
Multi-speaker Emotion Conversion via Latent Variable Regularization and a Chained Encoder-Decoder-Predictor Network
Aug 10, 2020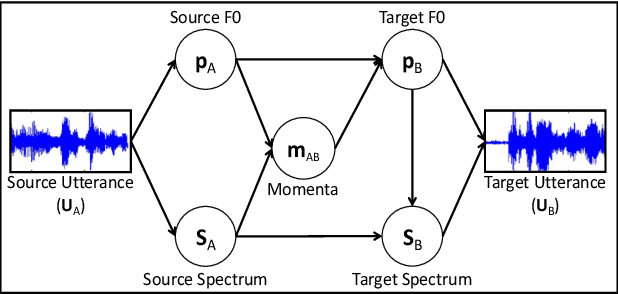
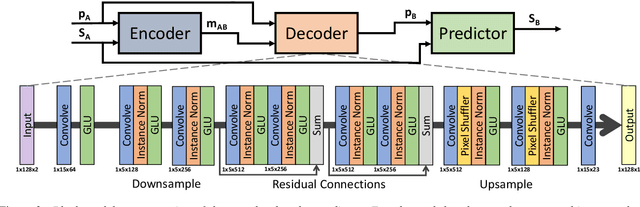
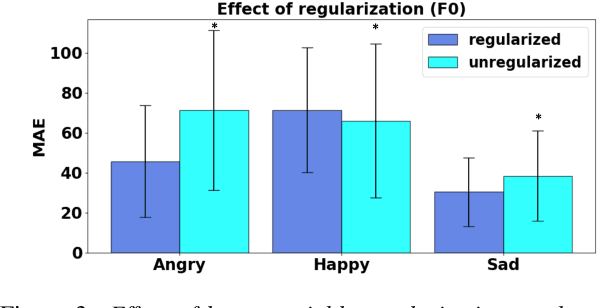
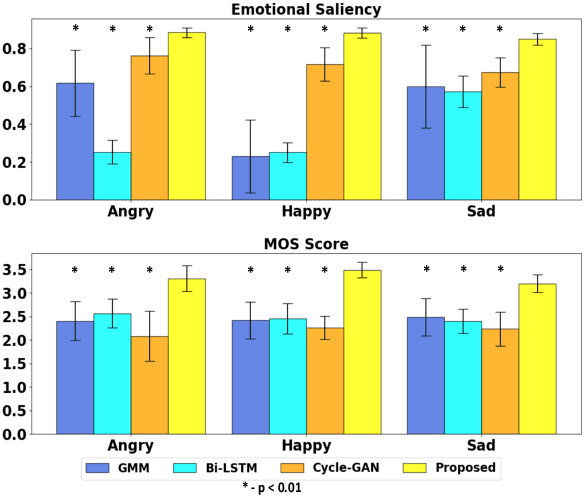
We propose a novel method for emotion conversion in speech based on a chained encoder-decoder-predictor neural network architecture. The encoder constructs a latent embedding of the fundamental frequency (F0) contour and the spectrum, which we regularize using the Large Diffeomorphic Metric Mapping (LDDMM) registration framework. The decoder uses this embedding to predict the modified F0 contour in a target emotional class. Finally, the predictor uses the original spectrum and the modified F0 contour to generate a corresponding target spectrum. Our joint objective function simultaneously optimizes the parameters of three model blocks. We show that our method outperforms the existing state-of-the-art approaches on both, the saliency of emotion conversion and the quality of resynthesized speech. In addition, the LDDMM regularization allows our model to convert phrases that were not present in training, thus providing evidence for out-of-sample generalization.