 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissociative Identity: Language Model Agents Lack Grounding for Reputation Mechanisms
May 28, 2026As autonomous language model agents proliferate, forming an emerging agentic web with real-world consequences, what credibility signals can you use to decide whether to trust an unfamiliar agent in the wild and delegate to it? A natural governance intuition is to extend human identity verification and reputation mechanisms, from ``Know Your Customer'' and credit scores to ``Know Your Agent'' regimes. However, we argue that this analogy is fundamentally incomplete. Reputation mechanisms function both as social signals and as corrective feedback that sustain an equilibrium of trustworthy behavior, presuming a persistent identity associated with behavioral continuity, sanction sensitivity, and costly non-fungibility. Yet language model agents are ontologically \emph{dissociative}: they are essentially an assemblage of mutable modules -- foundational models, system prompts, tool-access policies, external memory, and, in some cases, a multi-agent system as a whole -- any of which may change agent behavior -- with a fluid persona that is also vulnerable to adversarial attack and may not internalize sanctions. Drawing on dissociative identity disorder jurisprudence, this dissociativity leaves agents without grounding for identifiability, predictability, credibility, and rehabilitability -- the very properties that reputation mechanisms aim to sustain -- thereby collapsing trust. We argue that identity-based, ex post, regulative, sanction-based governance, such as reputation, is structurally inapplicable to dissociative agents, and we suggest a shift to observability-based, ex ante, constitutive, protocol-based behavioral harnesses.
The Interaction Layer: An Exploration for Co-Designing User-LLM Interactions in Parental Wellbeing Support Systems
Nov 02, 2024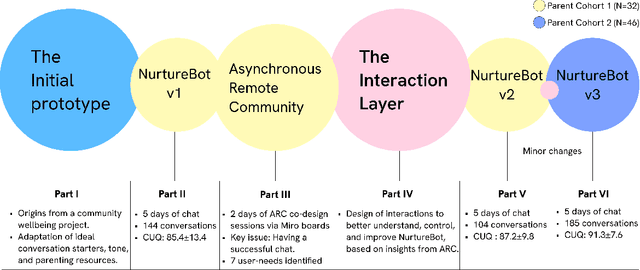



Parenting brings emotional and physical challenges, from balancing work, childcare, and finances to coping with exhaustion and limited personal time. Yet, one in three parents never seek support. AI systems potentially offer stigma-free, accessible, and affordable solutions. Yet, user adoption often fails due to issues with explainability and reliability. To see if these issues could be solved using a co-design approach, we developed and tested NurtureBot, a wellbeing support assistant for new parents. 32 parents co-designed the system through Asynchronous Remote Communities method, identifying the key challenge as achieving a "successful chat". Aspart of co-design, parents role-played as NurturBot, rewriting its dialogues to improve user understanding, control, and outcomes. The refined prototype evaluated by 32 initial and 46 new parents, showed improved user experience and usability, with final CUQ score of 91.3/100, demonstrating successful interaction patterns. Our process revealed useful interaction design lessons for effective AI parenting support.
Design of a dynamic and self-adapting system, supported with artificial intelligence, machine learning and real-time intelligence for predictive cyber risk analytics
May 19, 2020
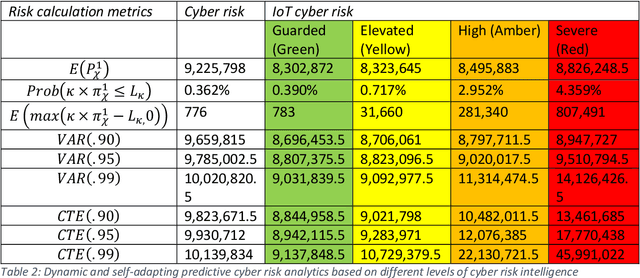
This paper surveys deep learning algorithms, IoT cyber security and risk models, and established mathematical formulas to identify the best approach for developing a dynamic and self-adapting system for predictive cyber risk analytics supported with Artificial Intelligence and Machine Learning and real-time intelligence in edge computing. The paper presents a new mathematical approach for integrating concepts for cognition engine design, edge computing and Artificial Intelligence and Machine Learning to automate anomaly detection. This engine instigates a step change by applying Artificial Intelligence and Machine Learning embedded at the edge of IoT networks, to deliver safe and functional real-time intelligence for predictive cyber risk analytics. This will enhance capacities for risk analytics and assists in the creation of a comprehensive and systematic understanding of the opportunities and threats that arise when edge computing nodes are deployed, and when Artificial Intelligence and Machine Learning technologies are migrated to the periphery of the internet and into local IoT networks.
Some HCI Priorities for GDPR-Compliant Machine Learning
Mar 16, 2018In this short paper, we consider the roles of HCI in enabling the better governance of consequential machine learning systems using the rights and obligations laid out in the recent 2016 EU General Data Protection Regulation (GDPR)---a law which involves heavy interaction with people and systems. Focussing on those areas that relate to algorithmic systems in society, we propose roles for HCI in legal contexts in relation to fairness, bias and discrimination; data protection by design; data protection impact assessments; transparency and explanations; the mitigation and understanding of automation bias; and the communication of envisaged consequences of processing.
Fairness and Accountability Design Needs for Algorithmic Support in High-Stakes Public Sector Decision-Making
Feb 03, 2018Calls for heightened consideration of fairness and accountability in algorithmically-informed public decisions---like taxation, justice, and child protection---are now commonplace. How might designers support such human values? We interviewed 27 public sector machine learning practitioners across 5 OECD countries regarding challenges understanding and imbuing public values into their work. The results suggest a disconnect between organisational and institutional realities, constraints and needs, and those addressed by current research into usable, transparent and 'discrimination-aware' machine learning---absences likely to undermine practical initiatives unless addressed. We see design opportunities in this disconnect, such as in supporting the tracking of concept drift in secondary data sources, and in building usable transparency tools to identify risks and incorporate domain knowledge, aimed both at managers and at the 'street-level bureaucrats' on the frontlines of public service. We conclude by outlining ethical challenges and future directions for collaboration in these high-stakes applications.
* 14 pages, 0 figures, ACM Conference on Human Factors in Computing Systems (CHI'18), April 21--26, Montreal, Canada
Like trainer, like bot? Inheritance of bias in algorithmic content moderation
Jul 05, 2017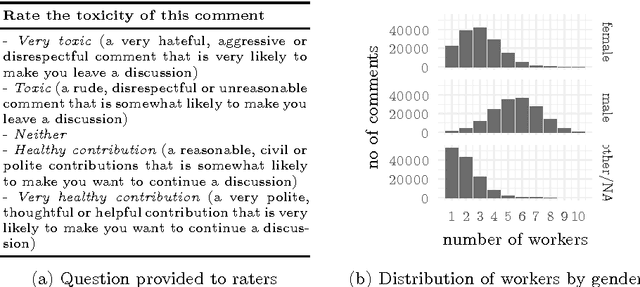
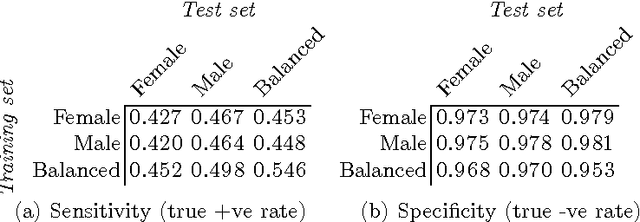
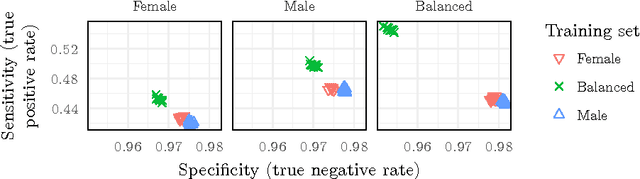
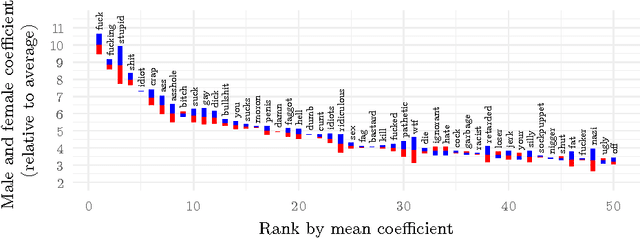
The internet has become a central medium through which `networked publics' express their opinions and engage in debate. Offensive comments and personal attacks can inhibit participation in these spaces. Automated content moderation aims to overcome this problem using machine learning classifiers trained on large corpora of texts manually annotated for offence. While such systems could help encourage more civil debate, they must navigate inherently normatively contestable boundaries, and are subject to the idiosyncratic norms of the human raters who provide the training data. An important objective for platforms implementing such measures might be to ensure that they are not unduly biased towards or against particular norms of offence. This paper provides some exploratory methods by which the normative biases of algorithmic content moderation systems can be measured, by way of a case study using an existing dataset of comments labelled for offence. We train classifiers on comments labelled by different demographic subsets (men and women) to understand how differences in conceptions of offence between these groups might affect the performance of the resulting models on various test sets. We conclude by discussing some of the ethical choices facing the implementers of algorithmic moderation systems, given various desired levels of diversity of viewpoints amongst discussion participants.