 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Simulation as a Proxy for High-order Tasks in Large Language Models
Feb 05, 2025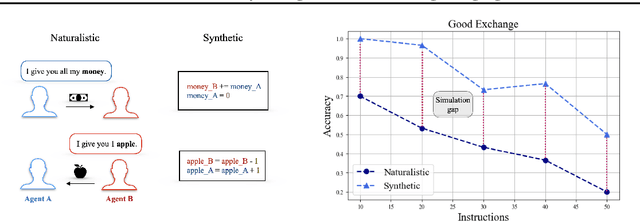


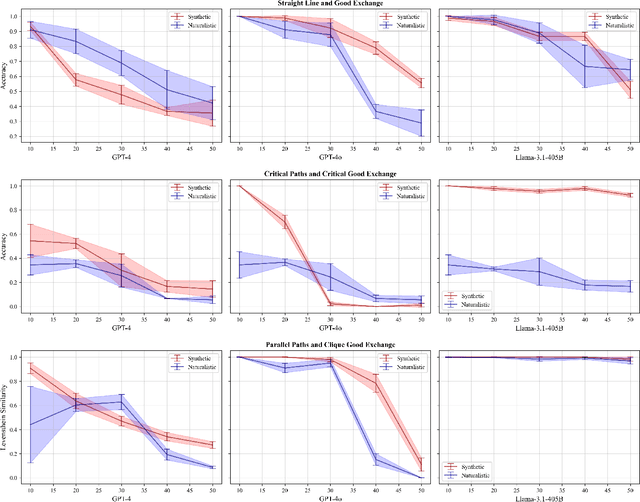
Many reasoning, planning, and problem-solving tasks share an intrinsic algorithmic nature: correctly simulating each step is a sufficient condition to solve them correctly. We collect pairs of naturalistic and synthetic reasoning tasks to assess the capabilities of Large Language Models (LLM). While naturalistic tasks often require careful human handcrafting, we show that synthetic data is, in many cases, a good proxy that is much easier to collect at scale. We leverage common constructs in programming as the counterpart of the building blocks of naturalistic reasoning tasks, such as straight-line programs, code that contains critical paths, and approximate and redundant instructions. We further assess the capabilities of LLMs on sorting problems and repeated operations via sorting algorithms and nested loops. Our synthetic datasets further reveal that while the most powerful LLMs exhibit relatively strong execution capabilities, the process is fragile: it is negatively affected by memorisation and seems to rely heavily on pattern recognition. Our contribution builds upon synthetically testing the reasoning capabilities of LLMs as a scalable complement to handcrafted human-annotated problems.
"They've Stolen My GPL-Licensed Model!": Toward Standardized and Transparent Model Licensing
Dec 16, 2024



As model parameter sizes reach the billion-level range and their training consumes zettaFLOPs of computation, components reuse and collaborative development are become increasingly prevalent in the Machine Learning (ML) community. These components, including models, software, and datasets, may originate from various sources and be published under different licenses, which govern the use and distribution of licensed works and their derivatives. However, commonly chosen licenses, such as GPL and Apache, are software-specific and are not clearly defined or bounded in the context of model publishing. Meanwhile, the reused components may also have free-content licenses and model licenses, which pose a potential risk of license noncompliance and rights infringement within the model production workflow. In this paper, we propose addressing the above challenges along two lines: 1) For license analysis, we have developed a new vocabulary for ML workflow management and encoded license rules to enable ontological reasoning for analyzing rights granting and compliance issues. 2) For standardized model publishing, we have drafted a set of model licenses that provide flexible options to meet the diverse needs of model publishing. Our analysis tool is built on Turtle language and Notation3 reasoning engine, envisioned as a first step toward Linked Open Model Production Data. We have also encoded our proposed model licenses into rules and demonstrated the effects of GPL and other commonly used licenses in model publishing, along with the flexibility advantages of our licenses, through comparisons and experiments.
A Scalable Communication Protocol for Networks of Large Language Models
Oct 14, 2024



Communication is a prerequisite for collaboration. When scaling networks of AI-powered agents, communication must be versatile, efficient, and portable. These requisites, which we refer to as the Agent Communication Trilemma, are hard to achieve in large networks of agents. We introduce Agora, a meta protocol that leverages existing communication standards to make LLM-powered agents solve complex problems efficiently. In Agora, agents typically use standardised routines for frequent communications, natural language for rare communications, and LLM-written routines for everything in between. Agora sidesteps the Agent Communication Trilemma and robustly handles changes in interfaces and members, allowing unprecedented scalability with full decentralisation and minimal involvement of human beings. On large Agora networks, we observe the emergence of self-organising, fully automated protocols that achieve complex goals without human intervention.
Code Simulation Challenges for Large Language Models
Jan 21, 2024



We investigate the extent to which Large Language Models (LLMs) can simulate the execution of computer code and algorithms. We begin by looking at straight line programs, and show that current LLMs demonstrate poor performance even with such simple programs -- performance rapidly degrades with the length of code. We then investigate the ability of LLMs to simulate programs that contain critical paths and redundant instructions. We also go beyond straight line program simulation with sorting algorithms and nested loops, and we show the computational complexity of a routine directly affects the ability of an LLM to simulate its execution. We observe that LLMs execute instructions sequentially and with a low error margin only for short programs or standard procedures. LLMs' code simulation is in tension with their pattern recognition and memorisation capabilities: on tasks where memorisation is detrimental, we propose a novel prompting method to simulate code execution line by line. Empirically, our new Chain of Simulation (CoSm) method improves on the standard Chain of Thought prompting approach by avoiding the pitfalls of memorisation.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023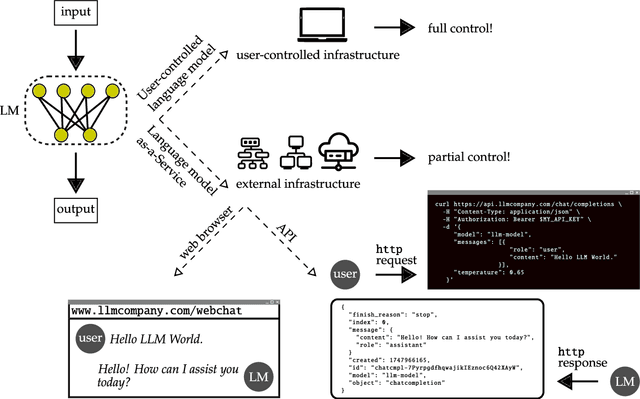

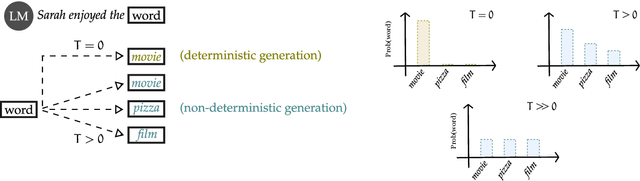
Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
Projected Subnetworks Scale Adaptation
Jan 27, 2023



Large models support great zero-shot and few-shot capabilities. However, updating these models on new tasks can break performance on previous seen tasks and their zero/few-shot unseen tasks. Our work explores how to update zero/few-shot learners such that they can maintain performance on seen/unseen tasks of previous tasks as well as new tasks. By manipulating the parameter updates of a gradient-based meta learner as the projected task-specific subnetworks, we show improvements for large models to retain seen and zero/few shot task performance in online settings.
Multiple Modes for Continual Learning
Sep 29, 2022


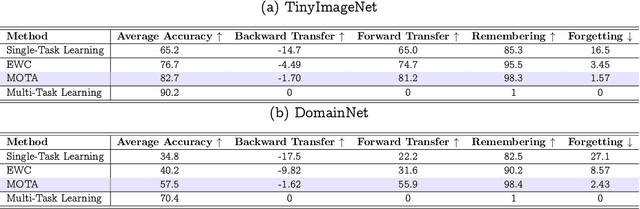
Adapting model parameters to incoming streams of data is a crucial factor to deep learning scalability. Interestingly, prior continual learning strategies in online settings inadvertently anchor their updated parameters to a local parameter subspace to remember old tasks, else drift away from the subspace and forget. From this observation, we formulate a trade-off between constructing multiple parameter modes and allocating tasks per mode. Mode-Optimized Task Allocation (MOTA), our contributed adaptation strategy, trains multiple modes in parallel, then optimizes task allocation per mode. We empirically demonstrate improvements over baseline continual learning strategies and across varying distribution shifts, namely sub-population, domain, and task shift.
Interpolating Compressed Parameter Subspaces
May 19, 2022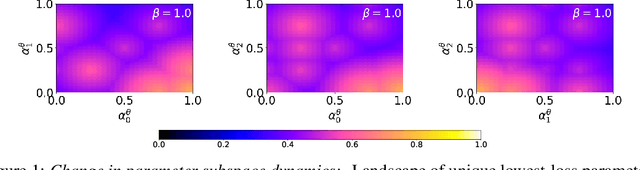
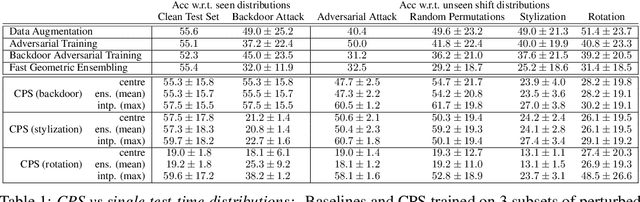
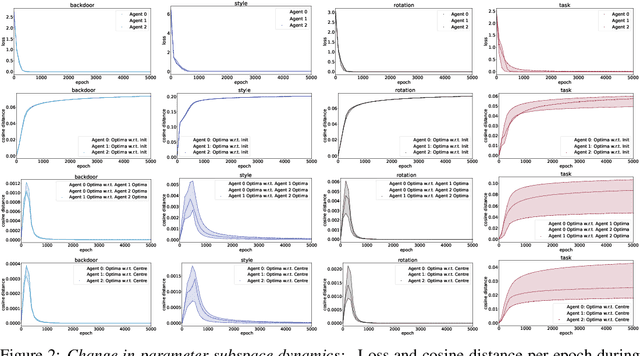
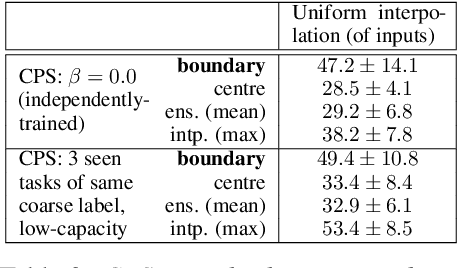
Inspired by recent work on neural subspaces and mode connectivity, we revisit parameter subspace sampling for shifted and/or interpolatable input distributions (instead of a single, unshifted distribution). We enforce a compressed geometric structure upon a set of trained parameters mapped to a set of train-time distributions, denoting the resulting subspaces as Compressed Parameter Subspaces (CPS). We show the success and failure modes of the types of shifted distributions whose optimal parameters reside in the CPS. We find that ensembling point-estimates within a CPS can yield a high average accuracy across a range of test-time distributions, including backdoor, adversarial, permutation, stylization and rotation perturbations. We also find that the CPS can contain low-loss point-estimates for various task shifts (albeit interpolated, perturbed, unseen or non-identical coarse labels). We further demonstrate this property in a continual learning setting with CIFAR100.
GreaseVision: Rewriting the Rules of the Interface
Apr 07, 2022


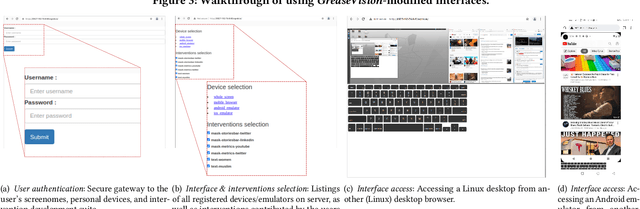
Digital harms can manifest across any interface. Key problems in addressing these harms include the high individuality of harms and the fast-changing nature of digital systems. As a result, we still lack a systematic approach to study harms and produce interventions for end-users. We put forward GreaseVision, a new framework that enables end-users to collaboratively develop interventions against harms in software using a no-code approach and recent advances in few-shot machine learning. The contribution of the framework and tool allow individual end-users to study their usage history and create personalized interventions. Our contribution also enables researchers to study the distribution of harms and interventions at scale.
Low-Loss Subspace Compression for Clean Gains against Multi-Agent Backdoor Attacks
Mar 07, 2022
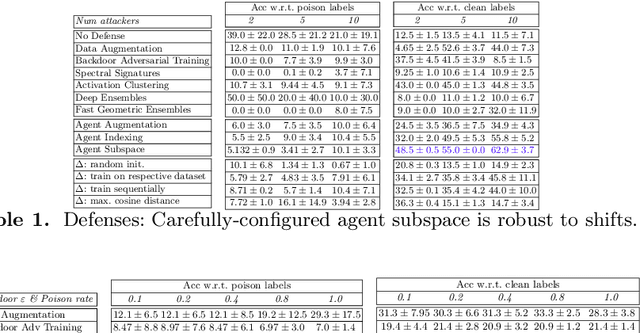


Recent exploration of the multi-agent backdoor attack demonstrated the backfiring effect, a natural defense against backdoor attacks where backdoored inputs are randomly classified. This yields a side-effect of low accuracy w.r.t. clean labels, which motivates this paper's work on the construction of multi-agent backdoor defenses that maximize accuracy w.r.t. clean labels and minimize that of poison labels. Founded upon agent dynamics and low-loss subspace construction, we contribute three defenses that yield improved multi-agent backdoor robustness.