 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Predictable Artificial Intelligence
Oct 09, 2023



We introduce the fundamental ideas and challenges of Predictable AI, a nascent research area that explores the ways in which we can anticipate key indicators of present and future AI ecosystems. We argue that achieving predictability is crucial for fostering trust, liability, control, alignment and safety of AI ecosystems, and thus should be prioritised over performance. While distinctive from other areas of technical and non-technical AI research, the questions, hypotheses and challenges relevant to Predictable AI were yet to be clearly described. This paper aims to elucidate them, calls for identifying paths towards AI predictability and outlines the potential impact of this emergent field.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023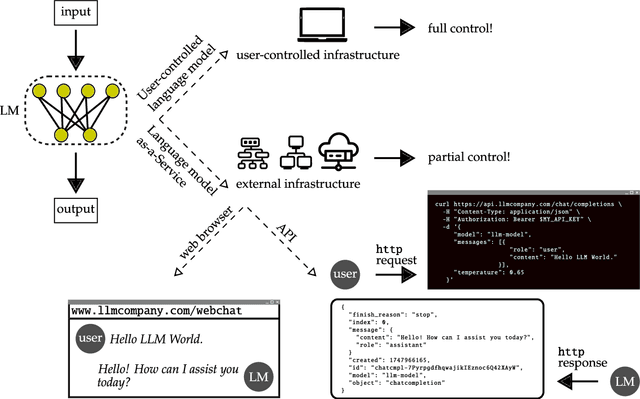

Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
Inferring Capabilities from Task Performance with Bayesian Triangulation
Sep 21, 2023



As machine learning models become more general, we need to characterise them in richer, more meaningful ways. We describe a method to infer the cognitive profile of a system from diverse experimental data. To do so, we introduce measurement layouts that model how task-instance features interact with system capabilities to affect performance. These features must be triangulated in complex ways to be able to infer capabilities from non-populational data -- a challenge for traditional psychometric and inferential tools. Using the Bayesian probabilistic programming library PyMC, we infer different cognitive profiles for agents in two scenarios: 68 actual contestants in the AnimalAI Olympics and 30 synthetic agents for O-PIAAGETS, an object permanence battery. We showcase the potential for capability-oriented evaluation.
Revealing the structure of language model capabilities
Jun 14, 2023Building a theoretical understanding of the capabilities of large language models (LLMs) is vital for our ability to predict and explain the behavior of these systems. Here, we investigate the structure of LLM capabilities by extracting latent capabilities from patterns of individual differences across a varied population of LLMs. Using a combination of Bayesian and frequentist factor analysis, we analyzed data from 29 different LLMs across 27 cognitive tasks. We found evidence that LLM capabilities are not monolithic. Instead, they are better explained by three well-delineated factors that represent reasoning, comprehension and core language modeling. Moreover, we found that these three factors can explain a high proportion of the variance in model performance. These results reveal a consistent structure in the capabilities of different LLMs and demonstrate the multifaceted nature of these capabilities. We also found that the three abilities show different relationships to model properties such as model size and instruction tuning. These patterns help refine our understanding of scaling laws and indicate that changes to a model that improve one ability might simultaneously impair others. Based on these findings, we suggest that benchmarks could be streamlined by focusing on tasks that tap into each broad model ability.