 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan vision language models learn intuitive physics from interaction?
Feb 05, 2026Pre-trained vision language models do not have good intuitions about the physical world. Recent work has shown that supervised fine-tuning can improve model performance on simple physical tasks. However, fine-tuned models do not appear to learn robust physical rules that can generalize to new contexts. Based on research in cognitive science, we hypothesize that models need to interact with an environment to properly learn its physical dynamics. We train models that learn through interaction with the environment using reinforcement learning. While learning from interaction allows models to improve their within-task performance, it fails to produce models with generalizable physical intuitions. We find that models trained on one task do not reliably generalize to related tasks, even if the tasks share visual statistics and physical principles, and regardless of whether the models are trained through interaction.
Exploring Major Transitions in the Evolution of Biological Cognition With Artificial Neural Networks
Sep 17, 2025Transitional accounts of evolution emphasise a few changes that shape what is evolvable, with dramatic consequences for derived lineages. More recently it has been proposed that cognition might also have evolved via a series of major transitions that manipulate the structure of biological neural networks, fundamentally changing the flow of information. We used idealised models of information flow, artificial neural networks (ANNs), to evaluate whether changes in information flow in a network can yield a transitional change in cognitive performance. We compared networks with feed-forward, recurrent and laminated topologies, and tested their performance learning artificial grammars that differed in complexity, controlling for network size and resources. We documented a qualitative expansion in the types of input that recurrent networks can process compared to feed-forward networks, and a related qualitative increase in performance for learning the most complex grammars. We also noted how the difficulty in training recurrent networks poses a form of transition barrier and contingent irreversibility -- other key features of evolutionary transitions. Not all changes in network topology confer a performance advantage in this task set. Laminated networks did not outperform non-laminated networks in grammar learning. Overall, our findings show how some changes in information flow can yield transitions in cognitive performance.
Cognitive Science-Inspired Evaluation of Core Capabilities for Object Understanding in AI
Mar 27, 2025

One of the core components of our world models is 'intuitive physics' - an understanding of objects, space, and causality. This capability enables us to predict events, plan action and navigate environments, all of which rely on a composite sense of objecthood. Despite its importance, there is no single, unified account of objecthood, though multiple theoretical frameworks provide insights. In the first part of this paper, we present a comprehensive overview of the main theoretical frameworks in objecthood research - Gestalt psychology, enactive cognition, and developmental psychology - and identify the core capabilities each framework attributes to object understanding, as well as what functional roles they play in shaping world models in biological agents. Given the foundational role of objecthood in world modelling, understanding objecthood is also essential in AI. In the second part of the paper, we evaluate how current AI paradigms approach and test objecthood capabilities compared to those in cognitive science. We define an AI paradigm as a combination of how objecthood is conceptualised, the methods used for studying objecthood, the data utilised, and the evaluation techniques. We find that, whilst benchmarks can detect that AI systems model isolated aspects of objecthood, the benchmarks cannot detect when AI systems lack functional integration across these capabilities, not solving the objecthood challenge fully. Finally, we explore novel evaluation approaches that align with the integrated vision of objecthood outlined in this paper. These methods are promising candidates for advancing from isolated object capabilities toward general-purpose AI with genuine object understanding in real-world contexts.
Bringing Comparative Cognition To Computers
Mar 04, 2025Researchers are increasingly subjecting artificial intelligence systems to psychological testing. But to rigorously compare their cognitive capacities with humans and other animals, we must avoid both over- and under-stating our similarities and differences. By embracing a comparative approach, we can integrate AI cognition research into the broader cognitive sciences.
Testing the limits of fine-tuning to improve reasoning in vision language models
Feb 21, 2025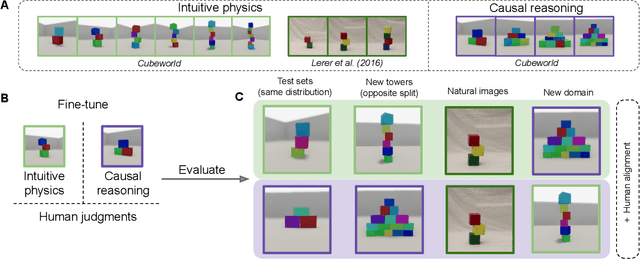
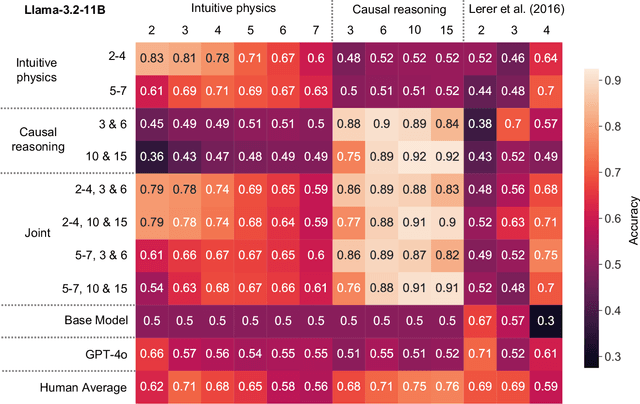
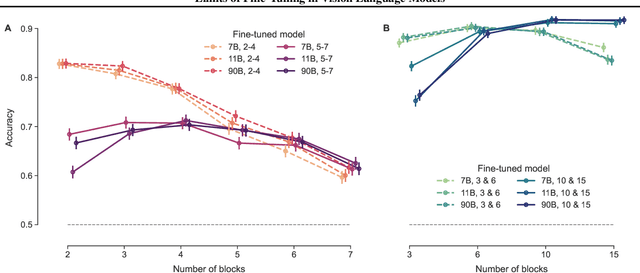
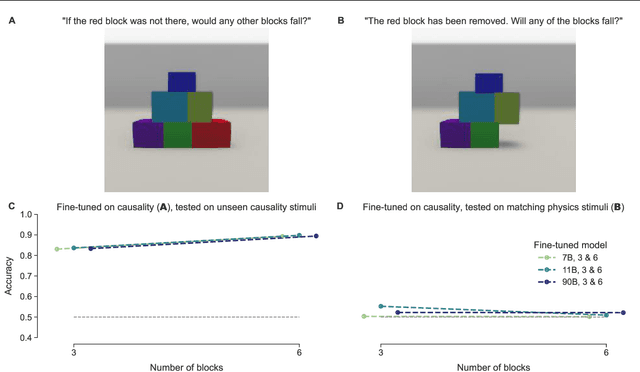
Pre-trained vision language models still fall short of human visual cognition. In an effort to improve visual cognition and align models with human behavior, we introduce visual stimuli and human judgments on visual cognition tasks, allowing us to systematically evaluate performance across cognitive domains under a consistent environment. We fine-tune models on ground truth data for intuitive physics and causal reasoning and find that this improves model performance in the respective fine-tuning domain. Furthermore, it can improve model alignment with human behavior. However, we find that fine-tuning does not contribute to robust human-like generalization to data with other visual characteristics or to tasks in other cognitive domains.
PredictaBoard: Benchmarking LLM Score Predictability
Feb 20, 2025Despite possessing impressive skills, Large Language Models (LLMs) often fail unpredictably, demonstrating inconsistent success in even basic common sense reasoning tasks. This unpredictability poses a significant challenge to ensuring their safe deployment, as identifying and operating within a reliable "safe zone" is essential for mitigating risks. To address this, we present PredictaBoard, a novel collaborative benchmarking framework designed to evaluate the ability of score predictors (referred to as assessors) to anticipate LLM errors on specific task instances (i.e., prompts) from existing datasets. PredictaBoard evaluates pairs of LLMs and assessors by considering the rejection rate at different tolerance errors. As such, PredictaBoard stimulates research into developing better assessors and making LLMs more predictable, not only with a higher average performance. We conduct illustrative experiments using baseline assessors and state-of-the-art LLMs. PredictaBoard highlights the critical need to evaluate predictability alongside performance, paving the way for safer AI systems where errors are not only minimised but also anticipated and effectively mitigated. Code for our benchmark can be found at https://github.com/Kinds-of-Intelligence-CFI/PredictaBoard
A little less conversation, a little more action, please: Investigating the physical common-sense of LLMs in a 3D embodied environment
Oct 30, 2024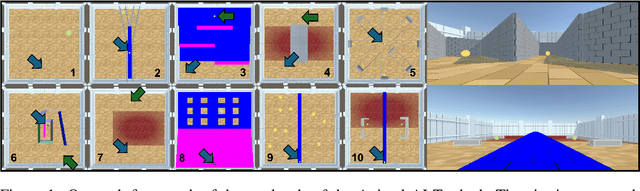
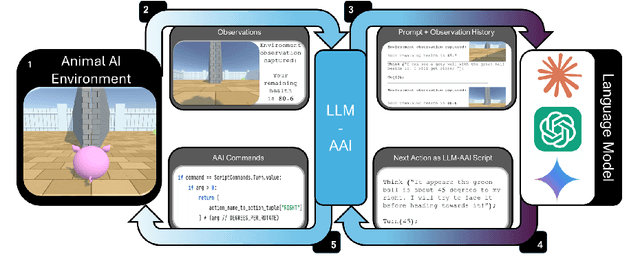


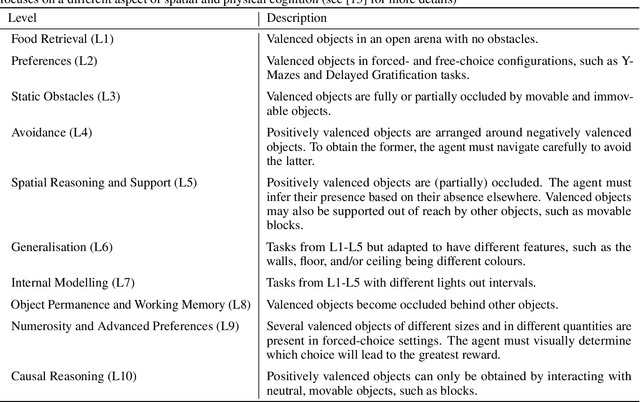
As general-purpose tools, Large Language Models (LLMs) must often reason about everyday physical environments. In a question-and-answer capacity, understanding the interactions of physical objects may be necessary to give appropriate responses. Moreover, LLMs are increasingly used as reasoning engines in agentic systems, designing and controlling their action sequences. The vast majority of research has tackled this issue using static benchmarks, comprised of text or image-based questions about the physical world. However, these benchmarks do not capture the complexity and nuance of real-life physical processes. Here we advocate for a second, relatively unexplored, approach: 'embodying' the LLMs by granting them control of an agent within a 3D environment. We present the first embodied and cognitively meaningful evaluation of physical common-sense reasoning in LLMs. Our framework allows direct comparison of LLMs with other embodied agents, such as those based on Deep Reinforcement Learning, and human and non-human animals. We employ the Animal-AI (AAI) environment, a simulated 3D virtual laboratory, to study physical common-sense reasoning in LLMs. For this, we use the AAI Testbed, a suite of experiments that replicate laboratory studies with non-human animals, to study physical reasoning capabilities including distance estimation, tracking out-of-sight objects, and tool use. We demonstrate that state-of-the-art multi-modal models with no finetuning can complete this style of task, allowing meaningful comparison to the entrants of the 2019 Animal-AI Olympics competition and to human children. Our results show that LLMs are currently outperformed by human children on these tasks. We argue that this approach allows the study of physical reasoning using ecologically valid experiments drawn directly from cognitive science, improving the predictability and reliability of LLMs.
Centaur: a foundation model of human cognition
Oct 26, 2024



Establishing a unified theory of cognition has been a major goal of psychology. While there have been previous attempts to instantiate such theories by building computational models, we currently do not have one model that captures the human mind in its entirety. Here we introduce Centaur, a computational model that can predict and simulate human behavior in any experiment expressible in natural language. We derived Centaur by finetuning a state-of-the-art language model on a novel, large-scale data set called Psych-101. Psych-101 reaches an unprecedented scale, covering trial-by-trial data from over 60,000 participants performing over 10,000,000 choices in 160 experiments. Centaur not only captures the behavior of held-out participants better than existing cognitive models, but also generalizes to new cover stories, structural task modifications, and entirely new domains. Furthermore, we find that the model's internal representations become more aligned with human neural activity after finetuning. Taken together, Centaur is the first real candidate for a unified model of human cognition. We anticipate that it will have a disruptive impact on the cognitive sciences, challenging the existing paradigm for developing computational models.
Animal-AI 3: What's New & Why You Should Care
Dec 18, 2023
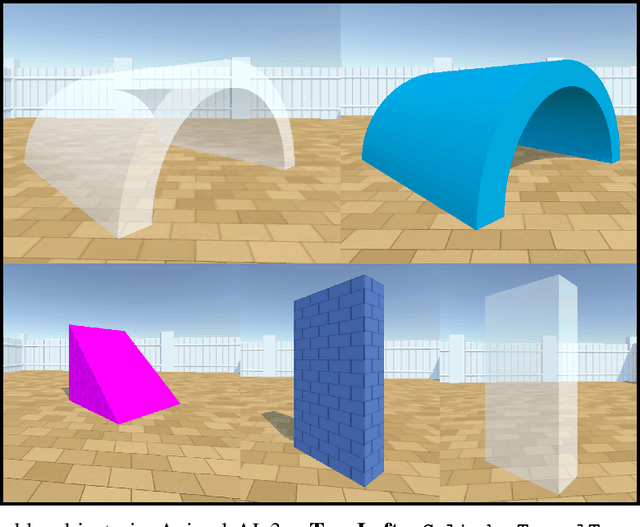
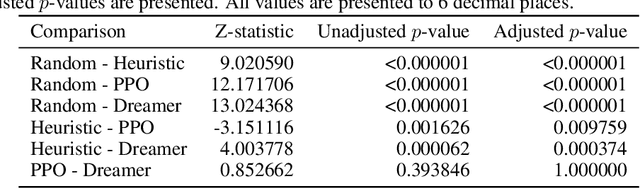
The Animal-AI Environment is a unique game-based research platform designed to serve both the artificial intelligence and cognitive science research communities. In this paper, we present Animal-AI 3, the latest version of the environment, outlining several major new features that make the game more engaging for humans and more complex for AI systems. New features include interactive buttons, reward dispensers, and player notifications, as well as an overhaul of the environment's graphics and processing for significant increases in agent training time and quality of the human player experience. We provide detailed guidance on how to build computational and behavioural experiments with Animal-AI 3. We present results from a series of agents, including the state-of-the-art Deep Reinforcement Learning agent (dreamer-v3), on newly designed tests and the Animal-AI Testbed of 900 tasks inspired by research in comparative psychology. Animal-AI 3 is designed to facilitate collaboration between the cognitive sciences and artificial intelligence. This paper serves as a stand-alone document that motivates, describes, and demonstrates Animal-AI 3 for the end user.
Predictable Artificial Intelligence
Oct 09, 2023



We introduce the fundamental ideas and challenges of Predictable AI, a nascent research area that explores the ways in which we can anticipate key indicators of present and future AI ecosystems. We argue that achieving predictability is crucial for fostering trust, liability, control, alignment and safety of AI ecosystems, and thus should be prioritised over performance. While distinctive from other areas of technical and non-technical AI research, the questions, hypotheses and challenges relevant to Predictable AI were yet to be clearly described. This paper aims to elucidate them, calls for identifying paths towards AI predictability and outlines the potential impact of this emergent field.