 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Comparative Cognition To Computers
Mar 04, 2025Researchers are increasingly subjecting artificial intelligence systems to psychological testing. But to rigorously compare their cognitive capacities with humans and other animals, we must avoid both over- and under-stating our similarities and differences. By embracing a comparative approach, we can integrate AI cognition research into the broader cognitive sciences.
A little less conversation, a little more action, please: Investigating the physical common-sense of LLMs in a 3D embodied environment
Oct 30, 2024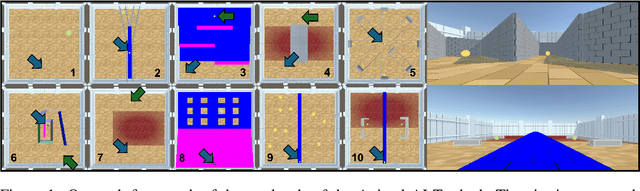
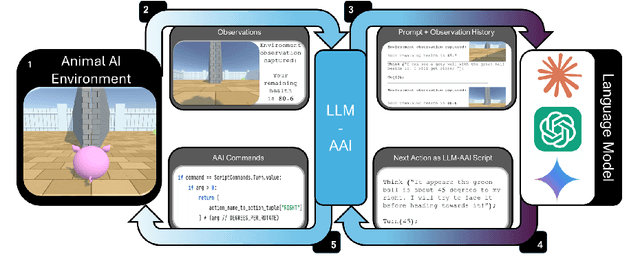


As general-purpose tools, Large Language Models (LLMs) must often reason about everyday physical environments. In a question-and-answer capacity, understanding the interactions of physical objects may be necessary to give appropriate responses. Moreover, LLMs are increasingly used as reasoning engines in agentic systems, designing and controlling their action sequences. The vast majority of research has tackled this issue using static benchmarks, comprised of text or image-based questions about the physical world. However, these benchmarks do not capture the complexity and nuance of real-life physical processes. Here we advocate for a second, relatively unexplored, approach: 'embodying' the LLMs by granting them control of an agent within a 3D environment. We present the first embodied and cognitively meaningful evaluation of physical common-sense reasoning in LLMs. Our framework allows direct comparison of LLMs with other embodied agents, such as those based on Deep Reinforcement Learning, and human and non-human animals. We employ the Animal-AI (AAI) environment, a simulated 3D virtual laboratory, to study physical common-sense reasoning in LLMs. For this, we use the AAI Testbed, a suite of experiments that replicate laboratory studies with non-human animals, to study physical reasoning capabilities including distance estimation, tracking out-of-sight objects, and tool use. We demonstrate that state-of-the-art multi-modal models with no finetuning can complete this style of task, allowing meaningful comparison to the entrants of the 2019 Animal-AI Olympics competition and to human children. Our results show that LLMs are currently outperformed by human children on these tasks. We argue that this approach allows the study of physical reasoning using ecologically valid experiments drawn directly from cognitive science, improving the predictability and reliability of LLMs.
Leaving the barn door open for Clever Hans: Simple features predict LLM benchmark answers
Oct 15, 2024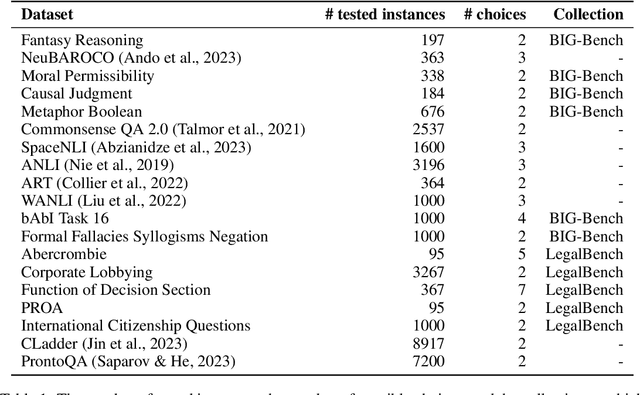
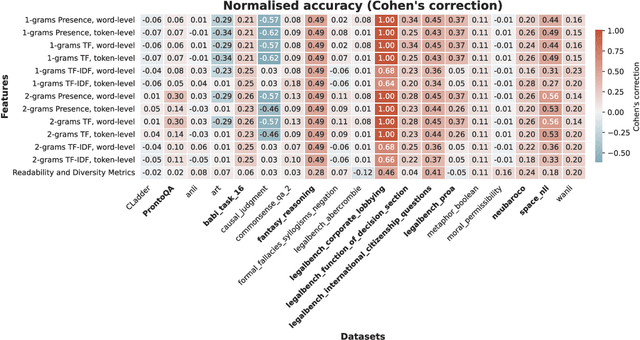

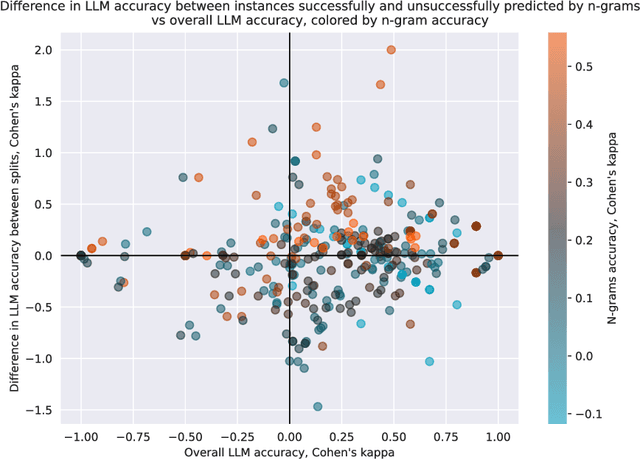
The integrity of AI benchmarks is fundamental to accurately assess the capabilities of AI systems. The internal validity of these benchmarks - i.e., making sure they are free from confounding factors - is crucial for ensuring that they are measuring what they are designed to measure. In this paper, we explore a key issue related to internal validity: the possibility that AI systems can solve benchmarks in unintended ways, bypassing the capability being tested. This phenomenon, widely known in human and animal experiments, is often referred to as the 'Clever Hans' effect, where tasks are solved using spurious cues, often involving much simpler processes than those putatively assessed. Previous research suggests that language models can exhibit this behaviour as well. In several older Natural Language Processing (NLP) benchmarks, individual $n$-grams like "not" have been found to be highly predictive of the correct labels, and supervised NLP models have been shown to exploit these patterns. In this work, we investigate the extent to which simple $n$-grams extracted from benchmark instances can be combined to predict labels in modern multiple-choice benchmarks designed for LLMs, and whether LLMs might be using such $n$-gram patterns to solve these benchmarks. We show how simple classifiers trained on these $n$-grams can achieve high scores on several benchmarks, despite lacking the capabilities being tested. Additionally, we provide evidence that modern LLMs might be using these superficial patterns to solve benchmarks. This suggests that the internal validity of these benchmarks may be compromised and caution should be exercised when interpreting LLM performance results on them.
100 instances is all you need: predicting the success of a new LLM on unseen data by testing on a few instances
Sep 05, 2024



Predicting the performance of LLMs on individual task instances is essential to ensure their reliability in high-stakes applications. To do so, a possibility is to evaluate the considered LLM on a set of task instances and train an assessor to predict its performance based on features of the instances. However, this approach requires evaluating each new LLM on a sufficiently large set of task instances to train an assessor specific to it. In this work, we leverage the evaluation results of previously tested LLMs to reduce the number of evaluations required to predict the performance of a new LLM. In practice, we propose to test the new LLM on a small set of reference instances and train a generic assessor which predicts the performance of the LLM on an instance based on the performance of the former on the reference set and features of the instance of interest. We conduct empirical studies on HELM-Lite and KindsOfReasoning, a collection of existing reasoning datasets that we introduce, where we evaluate all instruction-fine-tuned OpenAI models until the January 2024 version of GPT4. When predicting performance on instances with the same distribution as those used to train the generic assessor, we find this achieves performance comparable to the LLM-specific assessors trained on the full set of instances. Additionally, we find that randomly selecting the reference instances performs as well as some advanced selection methods we tested. For out of distribution, however, no clear winner emerges and the overall performance is worse, suggesting that the inherent predictability of LLMs is low.
Animal-AI 3: What's New & Why You Should Care
Dec 18, 2023
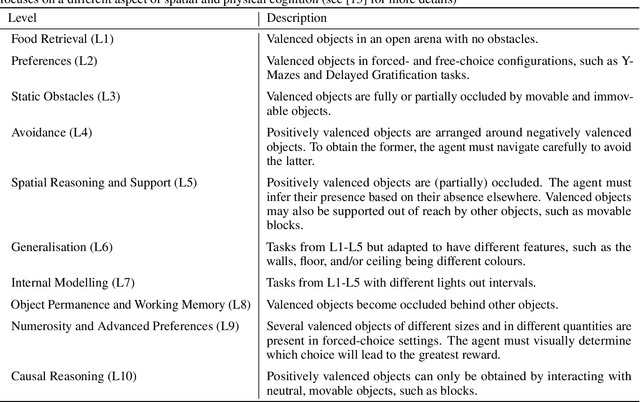
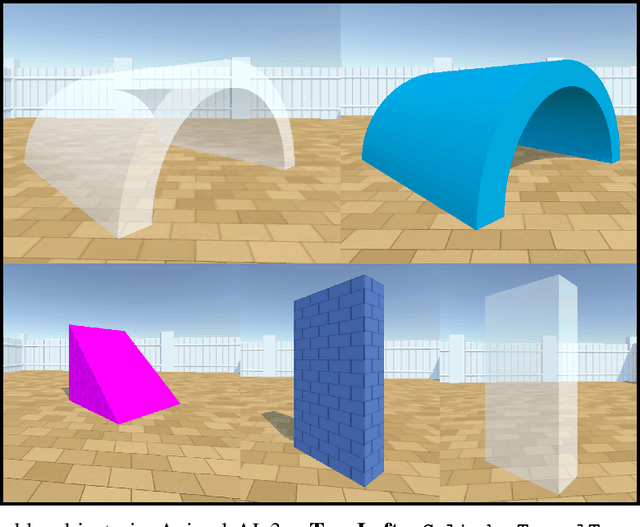
The Animal-AI Environment is a unique game-based research platform designed to serve both the artificial intelligence and cognitive science research communities. In this paper, we present Animal-AI 3, the latest version of the environment, outlining several major new features that make the game more engaging for humans and more complex for AI systems. New features include interactive buttons, reward dispensers, and player notifications, as well as an overhaul of the environment's graphics and processing for significant increases in agent training time and quality of the human player experience. We provide detailed guidance on how to build computational and behavioural experiments with Animal-AI 3. We present results from a series of agents, including the state-of-the-art Deep Reinforcement Learning agent (dreamer-v3), on newly designed tests and the Animal-AI Testbed of 900 tasks inspired by research in comparative psychology. Animal-AI 3 is designed to facilitate collaboration between the cognitive sciences and artificial intelligence. This paper serves as a stand-alone document that motivates, describes, and demonstrates Animal-AI 3 for the end user.