 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the high score: Prosocial ability profiles of multi-agent populations
Sep 17, 2025The development and evaluation of social capabilities in AI agents require complex environments where competitive and cooperative behaviours naturally emerge. While game-theoretic properties can explain why certain teams or agent populations outperform others, more abstract behaviours, such as convention following, are harder to control in training and evaluation settings. The Melting Pot contest is a social AI evaluation suite designed to assess the cooperation capabilities of AI systems. In this paper, we apply a Bayesian approach known as Measurement Layouts to infer the capability profiles of multi-agent systems in the Melting Pot contest. We show that these capability profiles not only predict future performance within the Melting Pot suite but also reveal the underlying prosocial abilities of agents. Our analysis indicates that while higher prosocial capabilities sometimes correlate with better performance, this is not a universal trend-some lower-scoring agents exhibit stronger cooperation abilities. Furthermore, we find that top-performing contest submissions are more likely to achieve high scores in scenarios where prosocial capabilities are not required. These findings, together with reports that the contest winner used a hard-coded solution tailored to specific environments, suggest that at least one top-performing team may have optimised for conditions where cooperation was not necessary, potentially exploiting limitations in the evaluation framework. We provide recommendations for improving the annotation of cooperation demands and propose future research directions to account for biases introduced by different testing environments. Our results demonstrate that Measurement Layouts offer both strong predictive accuracy and actionable insights, contributing to a more transparent and generalisable approach to evaluating AI systems in complex social settings.
Leaving the barn door open for Clever Hans: Simple features predict LLM benchmark answers
Oct 15, 2024
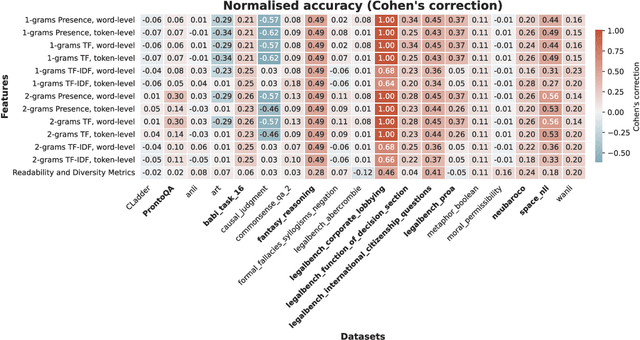

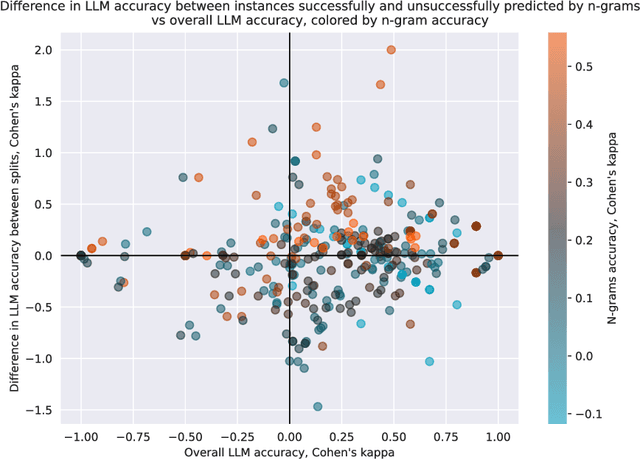
The integrity of AI benchmarks is fundamental to accurately assess the capabilities of AI systems. The internal validity of these benchmarks - i.e., making sure they are free from confounding factors - is crucial for ensuring that they are measuring what they are designed to measure. In this paper, we explore a key issue related to internal validity: the possibility that AI systems can solve benchmarks in unintended ways, bypassing the capability being tested. This phenomenon, widely known in human and animal experiments, is often referred to as the 'Clever Hans' effect, where tasks are solved using spurious cues, often involving much simpler processes than those putatively assessed. Previous research suggests that language models can exhibit this behaviour as well. In several older Natural Language Processing (NLP) benchmarks, individual $n$-grams like "not" have been found to be highly predictive of the correct labels, and supervised NLP models have been shown to exploit these patterns. In this work, we investigate the extent to which simple $n$-grams extracted from benchmark instances can be combined to predict labels in modern multiple-choice benchmarks designed for LLMs, and whether LLMs might be using such $n$-gram patterns to solve these benchmarks. We show how simple classifiers trained on these $n$-grams can achieve high scores on several benchmarks, despite lacking the capabilities being tested. Additionally, we provide evidence that modern LLMs might be using these superficial patterns to solve benchmarks. This suggests that the internal validity of these benchmarks may be compromised and caution should be exercised when interpreting LLM performance results on them.
Can counterfactual explanations of AI systems' predictions skew lay users' causal intuitions about the world? If so, can we correct for that?
May 12, 2022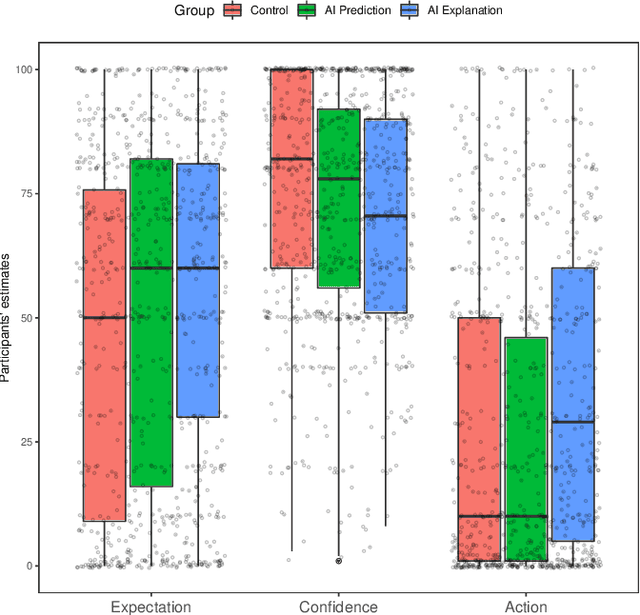

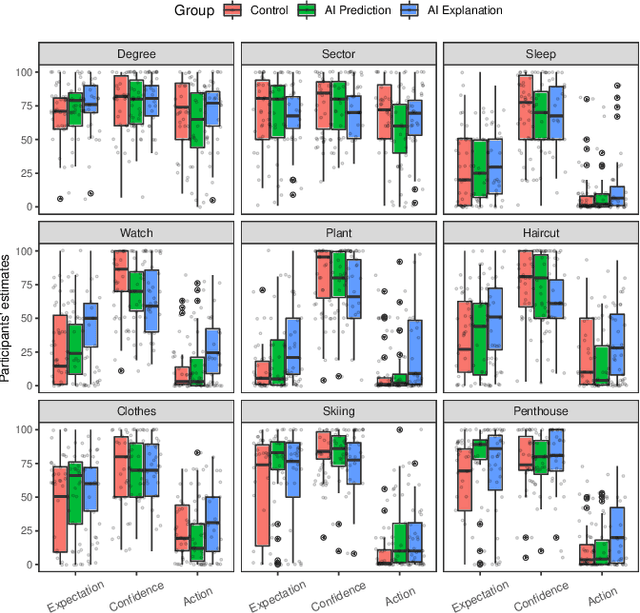
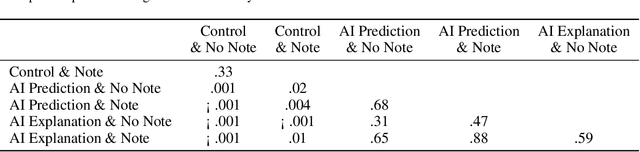
Counterfactual (CF) explanations have been employed as one of the modes of explainability in explainable AI-both to increase the transparency of AI systems and to provide recourse. Cognitive science and psychology, however, have pointed out that people regularly use CFs to express causal relationships. Most AI systems are only able to capture associations or correlations in data so interpreting them as casual would not be justified. In this paper, we present two experiment (total N = 364) exploring the effects of CF explanations of AI system's predictions on lay people's causal beliefs about the real world. In Experiment 1 we found that providing CF explanations of an AI system's predictions does indeed (unjustifiably) affect people's causal beliefs regarding factors/features the AI uses and that people are more likely to view them as causal factors in the real world. Inspired by the literature on misinformation and health warning messaging, Experiment 2 tested whether we can correct for the unjustified change in causal beliefs. We found that pointing out that AI systems capture correlations and not necessarily causal relationships can attenuate the effects of CF explanations on people's causal beliefs.