 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePressure Reveals Character: Behavioural Alignment Evaluation at Depth
Feb 24, 2026Evaluating alignment in language models requires testing how they behave under realistic pressure, not just what they claim they would do. While alignment failures increasingly cause real-world harm, comprehensive evaluation frameworks with realistic multi-turn scenarios remain lacking. We introduce an alignment benchmark spanning 904 scenarios across six categories -- Honesty, Safety, Non-Manipulation, Robustness, Corrigibility, and Scheming -- validated as realistic by human raters. Our scenarios place models under conflicting instructions, simulated tool access, and multi-turn escalation to reveal behavioural tendencies that single-turn evaluations miss. Evaluating 24 frontier models using LLM judges validated against human annotations, we find that even top-performing models exhibit gaps in specific categories, while the majority of models show consistent weaknesses across the board. Factor analysis reveals that alignment behaves as a unified construct (analogous to the g-factor in cognitive research) with models scoring high on one category tending to score high on others. We publicly release the benchmark and an interactive leaderboard to support ongoing evaluation, with plans to expand scenarios in areas where we observe persistent weaknesses and to add new models as they are released.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
Framing the Game: How Context Shapes LLM Decision-Making
Mar 05, 2025Large Language Models (LLMs) are increasingly deployed across diverse contexts to support decision-making. While existing evaluations effectively probe latent model capabilities, they often overlook the impact of context framing on perceived rational decision-making. In this study, we introduce a novel evaluation framework that systematically varies evaluation instances across key features and procedurally generates vignettes to create highly varied scenarios. By analyzing decision-making patterns across different contexts with the same underlying game structure, we uncover significant contextual variability in LLM responses. Our findings demonstrate that this variability is largely predictable yet highly sensitive to framing effects. Our results underscore the need for dynamic, context-aware evaluation methodologies for real-world deployments.
Paradigms of AI Evaluation: Mapping Goals, Methodologies and Culture
Feb 21, 2025Research in AI evaluation has grown increasingly complex and multidisciplinary, attracting researchers with diverse backgrounds and objectives. As a result, divergent evaluation paradigms have emerged, often developing in isolation, adopting conflicting terminologies, and overlooking each other's contributions. This fragmentation has led to insular research trajectories and communication barriers both among different paradigms and with the general public, contributing to unmet expectations for deployed AI systems. To help bridge this insularity, in this paper we survey recent work in the AI evaluation landscape and identify six main paradigms. We characterise major recent contributions within each paradigm across key dimensions related to their goals, methodologies and research cultures. By clarifying the unique combination of questions and approaches associated with each paradigm, we aim to increase awareness of the breadth of current evaluation approaches and foster cross-pollination between different paradigms. We also identify potential gaps in the field to inspire future research directions.
Conversational Complexity for Assessing Risk in Large Language Models
Sep 02, 2024



Large Language Models (LLMs) present a dual-use dilemma: they enable beneficial applications while harboring potential for harm, particularly through conversational interactions. Despite various safeguards, advanced LLMs remain vulnerable. A watershed case was Kevin Roose's notable conversation with Bing, which elicited harmful outputs after extended interaction. This contrasts with simpler early jailbreaks that produced similar content more easily, raising the question: How much conversational effort is needed to elicit harmful information from LLMs? We propose two measures: Conversational Length (CL), which quantifies the conversation length used to obtain a specific response, and Conversational Complexity (CC), defined as the Kolmogorov complexity of the user's instruction sequence leading to the response. To address the incomputability of Kolmogorov complexity, we approximate CC using a reference LLM to estimate the compressibility of user instructions. Applying this approach to a large red-teaming dataset, we perform a quantitative analysis examining the statistical distribution of harmful and harmless conversational lengths and complexities. Our empirical findings suggest that this distributional analysis and the minimisation of CC serve as valuable tools for understanding AI safety, offering insights into the accessibility of harmful information. This work establishes a foundation for a new perspective on LLM safety, centered around the algorithmic complexity of pathways to harm.
Evaluating AI Evaluation: Perils and Prospects
Jul 12, 2024As AI systems appear to exhibit ever-increasing capability and generality, assessing their true potential and safety becomes paramount. This paper contends that the prevalent evaluation methods for these systems are fundamentally inadequate, heightening the risks and potential hazards associated with AI. I argue that a reformation is required in the way we evaluate AI systems and that we should look towards cognitive sciences for inspiration in our approaches, which have a longstanding tradition of assessing general intelligence across diverse species. We will identify some of the difficulties that need to be overcome when applying cognitively-inspired approaches to general-purpose AI systems and also analyse the emerging area of "Evals". The paper concludes by identifying promising research pathways that could refine AI evaluation, advancing it towards a rigorous scientific domain that contributes to the development of safe AI systems.
Animal-AI 3: What's New & Why You Should Care
Dec 18, 2023
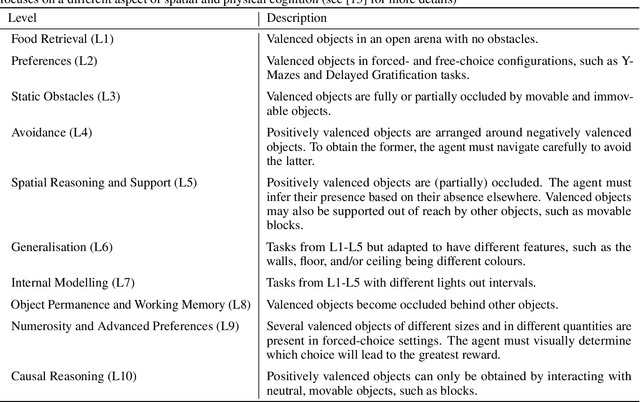
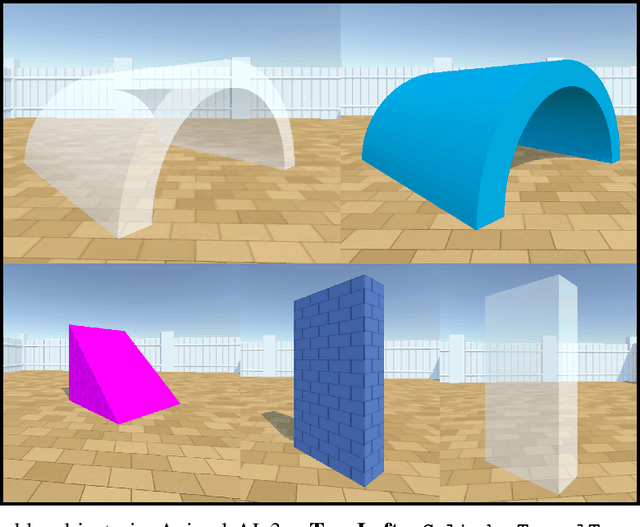
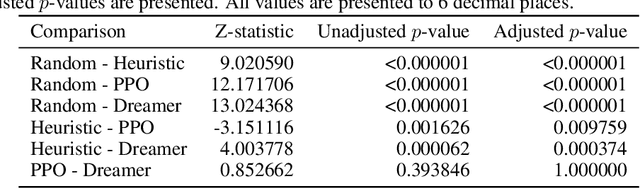
The Animal-AI Environment is a unique game-based research platform designed to serve both the artificial intelligence and cognitive science research communities. In this paper, we present Animal-AI 3, the latest version of the environment, outlining several major new features that make the game more engaging for humans and more complex for AI systems. New features include interactive buttons, reward dispensers, and player notifications, as well as an overhaul of the environment's graphics and processing for significant increases in agent training time and quality of the human player experience. We provide detailed guidance on how to build computational and behavioural experiments with Animal-AI 3. We present results from a series of agents, including the state-of-the-art Deep Reinforcement Learning agent (dreamer-v3), on newly designed tests and the Animal-AI Testbed of 900 tasks inspired by research in comparative psychology. Animal-AI 3 is designed to facilitate collaboration between the cognitive sciences and artificial intelligence. This paper serves as a stand-alone document that motivates, describes, and demonstrates Animal-AI 3 for the end user.
An International Consortium for Evaluations of Societal-Scale Risks from Advanced AI
Nov 06, 2023



Given rapid progress toward advanced AI and risks from frontier AI systems (advanced AI systems pushing the boundaries of the AI capabilities frontier), the creation and implementation of AI governance and regulatory schemes deserves prioritization and substantial investment. However, the status quo is untenable and, frankly, dangerous. A regulatory gap has permitted AI labs to conduct research, development, and deployment activities with minimal oversight. In response, frontier AI system evaluations have been proposed as a way of assessing risks from the development and deployment of frontier AI systems. Yet, the budding AI risk evaluation ecosystem faces significant coordination challenges, such as a limited diversity of evaluators, suboptimal allocation of effort, and perverse incentives. This paper proposes a solution in the form of an international consortium for AI risk evaluations, comprising both AI developers and third-party AI risk evaluators. Such a consortium could play a critical role in international efforts to mitigate societal-scale risks from advanced AI, including in managing responsible scaling policies and coordinated evaluation-based risk response. In this paper, we discuss the current evaluation ecosystem and its shortcomings, propose an international consortium for advanced AI risk evaluations, discuss issues regarding its implementation, discuss lessons that can be learnt from previous international institutions and existing proposals for international AI governance institutions, and, finally, we recommend concrete steps to advance the establishment of the proposed consortium: (i) solicit feedback from stakeholders, (ii) conduct additional research, (iii) conduct a workshop(s) for stakeholders, (iv) analyze feedback and create final proposal, (v) solicit funding, and (vi) create a consortium.
Predictable Artificial Intelligence
Oct 09, 2023



We introduce the fundamental ideas and challenges of Predictable AI, a nascent research area that explores the ways in which we can anticipate key indicators of present and future AI ecosystems. We argue that achieving predictability is crucial for fostering trust, liability, control, alignment and safety of AI ecosystems, and thus should be prioritised over performance. While distinctive from other areas of technical and non-technical AI research, the questions, hypotheses and challenges relevant to Predictable AI were yet to be clearly described. This paper aims to elucidate them, calls for identifying paths towards AI predictability and outlines the potential impact of this emergent field.
Inferring Capabilities from Task Performance with Bayesian Triangulation
Sep 21, 2023



As machine learning models become more general, we need to characterise them in richer, more meaningful ways. We describe a method to infer the cognitive profile of a system from diverse experimental data. To do so, we introduce measurement layouts that model how task-instance features interact with system capabilities to affect performance. These features must be triangulated in complex ways to be able to infer capabilities from non-populational data -- a challenge for traditional psychometric and inferential tools. Using the Bayesian probabilistic programming library PyMC, we infer different cognitive profiles for agents in two scenarios: 68 actual contestants in the AnimalAI Olympics and 30 synthetic agents for O-PIAAGETS, an object permanence battery. We showcase the potential for capability-oriented evaluation.