 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human-Level AI Tales to AI Leveling Human Scales
Feb 21, 2026Comparing AI models to "human level" is often misleading when benchmark scores are incommensurate or human baselines are drawn from a narrow population. To address this, we propose a framework that calibrates items against the 'world population' and report performance on a common, human-anchored scale. Concretely, we build on a set of multi-level scales for different capabilities where each level should represent a probability of success of the whole world population on a logarithmic scale with a base $B$. We calibrate each scale for each capability (reasoning, comprehension, knowledge, volume, etc.) by compiling publicly released human test data spanning education and reasoning benchmarks (PISA, TIMSS, ICAR, UKBioBank, and ReliabilityBench). The base $B$ is estimated by extrapolating between samples with two demographic profiles using LLMs, with the hypothesis that they condense rich information about human populations. We evaluate the quality of different mappings using group slicing and post-stratification. The new techniques allow for the recalibration and standardization of scales relative to the whole-world population.
General Scales Unlock AI Evaluation with Explanatory and Predictive Power
Mar 09, 2025Ensuring safe and effective use of AI requires understanding and anticipating its performance on novel tasks, from advanced scientific challenges to transformed workplace activities. So far, benchmarking has guided progress in AI, but it has offered limited explanatory and predictive power for general-purpose AI systems, given the low transferability across diverse tasks. In this paper, we introduce general scales for AI evaluation that can explain what common AI benchmarks really measure, extract ability profiles of AI systems, and predict their performance for new task instances, in- and out-of-distribution. Our fully-automated methodology builds on 18 newly-crafted rubrics that place instance demands on general scales that do not saturate. Illustrated for 15 large language models and 63 tasks, high explanatory power is unleashed from inspecting the demand and ability profiles, bringing insights on the sensitivity and specificity exhibited by different benchmarks, and how knowledge, metacognition and reasoning are affected by model size, chain-of-thought and distillation. Surprisingly, high predictive power at the instance level becomes possible using these demand levels, providing superior estimates over black-box baseline predictors based on embeddings or finetuning, especially in out-of-distribution settings (new tasks and new benchmarks). The scales, rubrics, battery, techniques and results presented here represent a major step for AI evaluation, underpinning the reliable deployment of AI in the years ahead.
PredictaBoard: Benchmarking LLM Score Predictability
Feb 20, 2025Despite possessing impressive skills, Large Language Models (LLMs) often fail unpredictably, demonstrating inconsistent success in even basic common sense reasoning tasks. This unpredictability poses a significant challenge to ensuring their safe deployment, as identifying and operating within a reliable "safe zone" is essential for mitigating risks. To address this, we present PredictaBoard, a novel collaborative benchmarking framework designed to evaluate the ability of score predictors (referred to as assessors) to anticipate LLM errors on specific task instances (i.e., prompts) from existing datasets. PredictaBoard evaluates pairs of LLMs and assessors by considering the rejection rate at different tolerance errors. As such, PredictaBoard stimulates research into developing better assessors and making LLMs more predictable, not only with a higher average performance. We conduct illustrative experiments using baseline assessors and state-of-the-art LLMs. PredictaBoard highlights the critical need to evaluate predictability alongside performance, paving the way for safer AI systems where errors are not only minimised but also anticipated and effectively mitigated. Code for our benchmark can be found at https://github.com/Kinds-of-Intelligence-CFI/PredictaBoard
Predictable Artificial Intelligence
Oct 09, 2023



We introduce the fundamental ideas and challenges of Predictable AI, a nascent research area that explores the ways in which we can anticipate key indicators of present and future AI ecosystems. We argue that achieving predictability is crucial for fostering trust, liability, control, alignment and safety of AI ecosystems, and thus should be prioritised over performance. While distinctive from other areas of technical and non-technical AI research, the questions, hypotheses and challenges relevant to Predictable AI were yet to be clearly described. This paper aims to elucidate them, calls for identifying paths towards AI predictability and outlines the potential impact of this emergent field.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Compute and Energy Consumption Trends in Deep Learning Inference
Sep 12, 2021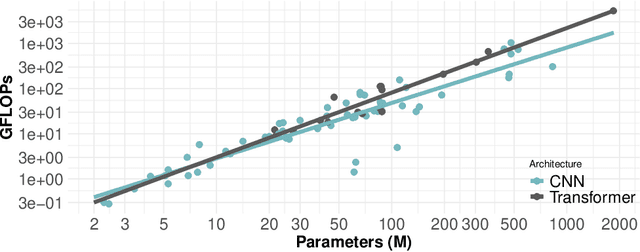
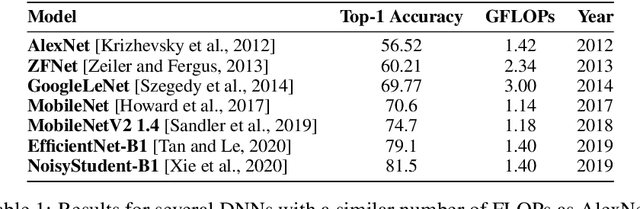
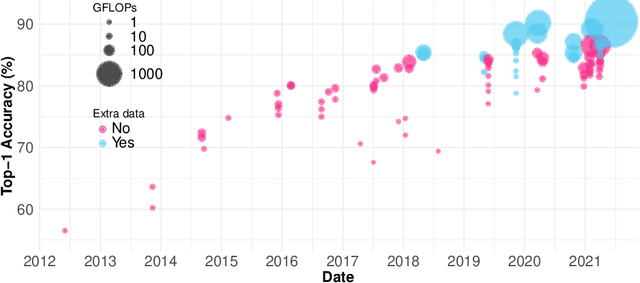
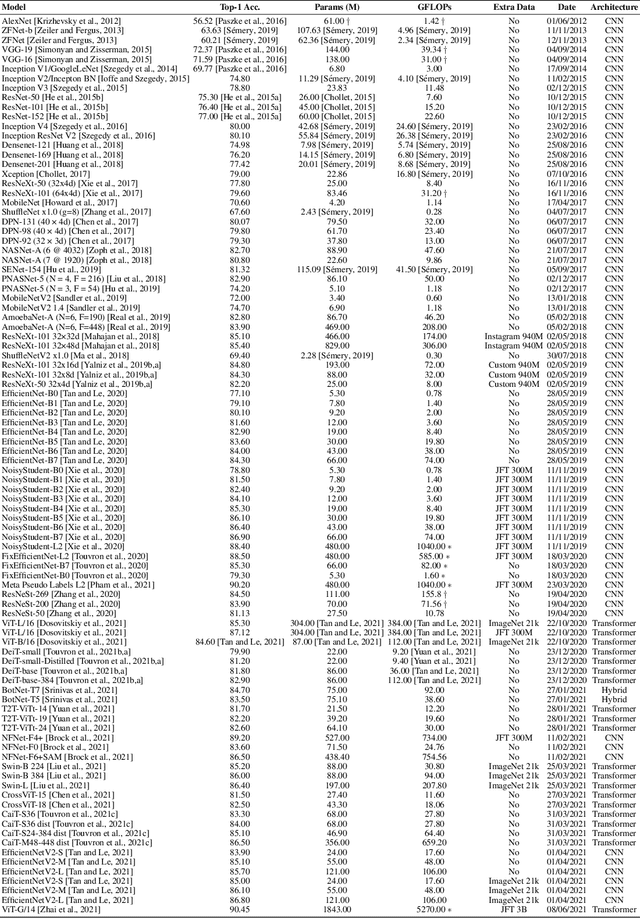
The progress of some AI paradigms such as deep learning is said to be linked to an exponential growth in the number of parameters. There are many studies corroborating these trends, but does this translate into an exponential increase in energy consumption? In order to answer this question we focus on inference costs rather than training costs, as the former account for most of the computing effort, solely because of the multiplicative factors. Also, apart from algorithmic innovations, we account for more specific and powerful hardware (leading to higher FLOPS) that is usually accompanied with important energy efficiency optimisations. We also move the focus from the first implementation of a breakthrough paper towards the consolidated version of the techniques one or two year later. Under this distinctive and comprehensive perspective, we study relevant models in the areas of computer vision and natural language processing: for a sustained increase in performance we see a much softer growth in energy consumption than previously anticipated. The only caveat is, yet again, the multiplicative factor, as future AI increases penetration and becomes more pervasive.
Fairness and Missing Values
May 29, 2019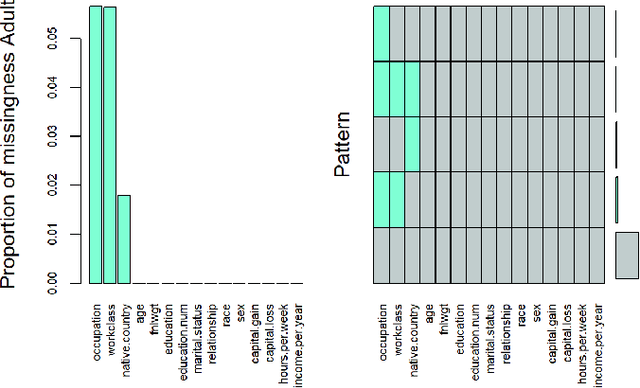

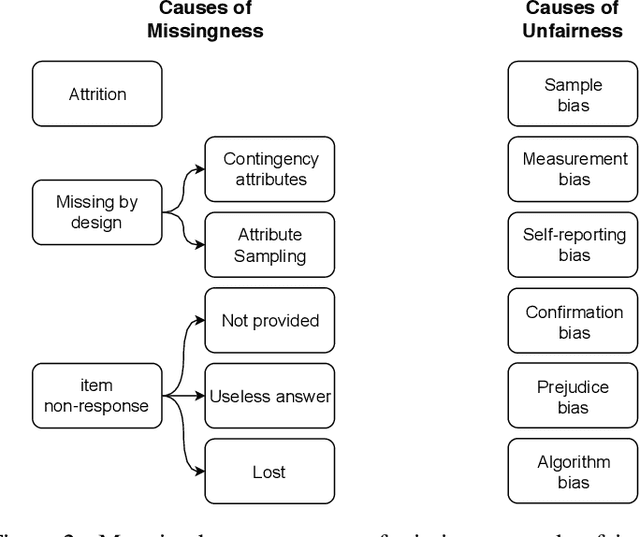
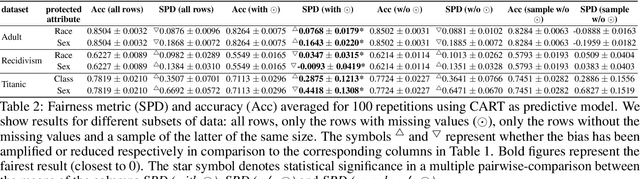
The causes underlying unfair decision making are complex, being internalised in different ways by decision makers, other actors dealing with data and models, and ultimately by the individuals being affected by these decisions. One frequent manifestation of all these latent causes arises in the form of missing values: protected groups are more reluctant to give information that could be used against them, delicate information for some groups can be erased by human operators, or data acquisition may simply be less complete and systematic for minority groups. As a result, missing values and bias in data are two phenomena that are tightly coupled. However, most recent techniques, libraries and experimental results dealing with fairness in machine learning have simply ignored missing data. In this paper, we claim that fairness research should not miss the opportunity to deal properly with missing data. To support this claim, (1) we analyse the sources of missing data and bias, and we map the common causes, (2) we find that rows containing missing values are usually fairer than the rest, which should not be treated as the uncomfortable ugly data that different techniques and libraries get rid of at the first occasion, and (3) we study the trade-off between performance and fairness when the rows with missing values are used (either because the technique deals with them directly or by imputation methods). We end the paper with a series of recommended procedures about what to do with missing data when aiming for fair decision making.
Analysing Results from AI Benchmarks: Key Indicators and How to Obtain Them
Nov 20, 2018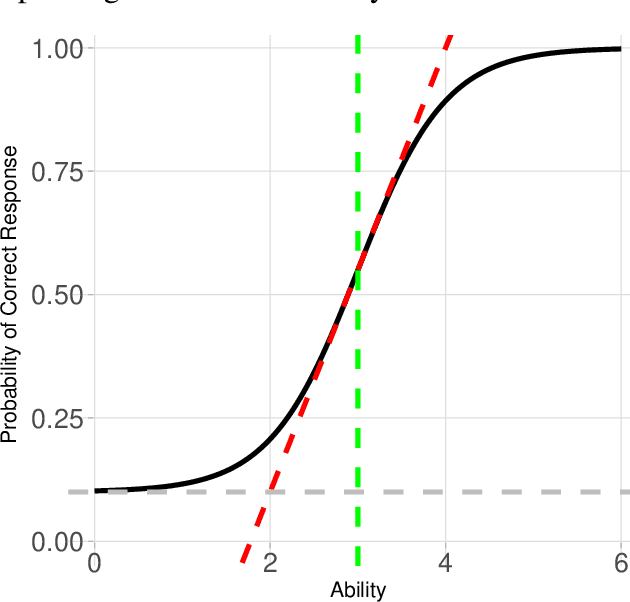
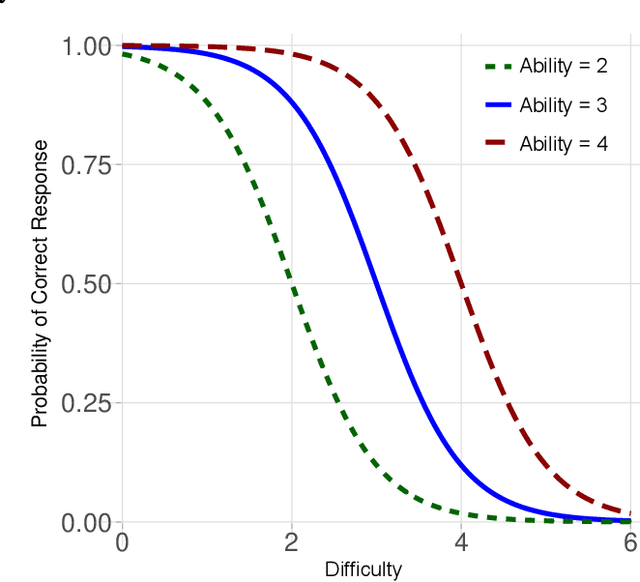


Item response theory (IRT) can be applied to the analysis of the evaluation of results from AI benchmarks. The two-parameter IRT model provides two indicators (difficulty and discrimination) on the side of the item (or AI problem) while only one indicator (ability) on the side of the respondent (or AI agent). In this paper we analyse how to make this set of indicators dual, by adding a fourth indicator, generality, on the side of the respondent. Generality is meant to be dual to discrimination, and it is based on difficulty. Namely, generality is defined as a new metric that evaluates whether an agent is consistently good at easy problems and bad at difficult ones. With the addition of generality, we see that this set of four key indicators can give us more insight on the results of AI benchmarks. In particular, we explore two popular benchmarks in AI, the Arcade Learning Environment (Atari 2600 games) and the General Video Game AI competition. We provide some guidelines to estimate and interpret these indicators for other AI benchmarks and competitions.
General-purpose Declarative Inductive Programming with Domain-Specific Background Knowledge for Data Wrangling Automation
Sep 26, 2018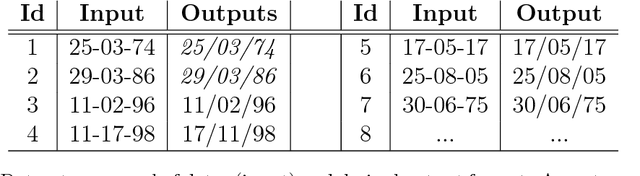

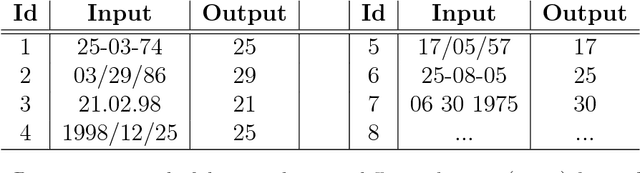
Given one or two examples, humans are good at understanding how to solve a problem independently of its domain, because they are able to detect what the problem is and to choose the appropriate background knowledge according to the context. For instance, presented with the string "8/17/2017" to be transformed to "17th of August of 2017", humans will process this in two steps: (1) they recognise that it is a date and (2) they map the date to the 17th of August of 2017. Inductive Programming (IP) aims at learning declarative (functional or logic) programs from examples. Two key advantages of IP are the use of background knowledge and the ability to synthesise programs from a few input/output examples (as humans do). In this paper we propose to use IP as a means for automating repetitive data manipulation tasks, frequently presented during the process of {\em data wrangling} in many data manipulation problems. Here we show that with the use of general-purpose declarative (programming) languages jointly with generic IP systems and the definition of domain-specific knowledge, many specific data wrangling problems from different application domains can be automatically solved from very few examples. We also propose an integrated benchmark for data wrangling, which we share publicly for the community.
A multidisciplinary task-based perspective for evaluating the impact of AI autonomy and generality on the future of work
Jul 06, 2018
This paper presents a multidisciplinary task approach for assessing the impact of artificial intelligence on the future of work. We provide definitions of a task from two main perspectives: socio-economic and computational. We propose to explore ways in which we can integrate or map these perspectives, and link them with the skills or capabilities required by them, for humans and AI systems. Finally, we argue that in order to understand the dynamics of tasks, we have to explore the relevance of autonomy and generality of AI systems for the automation or alteration of the workplace.